FedMLP: Federated Multi-Label Medical Image Classification under Task Heterogeneity

0
Sign in to get full access
Overview
- Federated learning technique for multi-label medical image classification in heterogeneous environments
- Addresses data and task heterogeneity challenges in federated learning
- Proposes a Federated Multi-Label Perceptron (FedMLP) model to enable personalized learning
Plain English Explanation
The paper presents a federated learning approach called FedMLP for classifying medical images with multiple labels. Federated learning allows training AI models across multiple devices or institutions without sharing the underlying data, which is important for sensitive medical data.
However, federated learning faces challenges when the data and tasks are heterogeneous across the participating devices or institutions. This paper tackles these challenges by proposing the FedMLP model, which can learn personalized models for each participant while also sharing knowledge across the federation.
The key idea is to use a multi-label perceptron network that can handle the partial label information often present in medical imaging data. The model is trained in a federated manner, allowing each participant to learn a personalized version of the model while also benefiting from the knowledge shared across the federation.
Technical Explanation
The paper introduces the FedMLP algorithm for federated multi-label medical image classification. FedMLP is designed to address the challenges of data and task heterogeneity in federated learning environments.
The model architecture consists of a shared base network and personalized head networks. The base network learns common representations, while the personalized head networks adapt the model to the unique characteristics of each client's data distribution and labeling patterns.
The federated training process alternates between local updates on client devices and global aggregation at the server. Clients perform stochastic gradient descent updates on their local data, and the server aggregates these updates using a weighted average to update the shared base network.
The paper also introduces a novel multi-label perceptron loss function that can handle partial label information, which is common in medical imaging datasets. This loss function allows the model to learn effectively even when some labels are missing.
The authors evaluate FedMLP on a federated multi-label chest X-ray classification task using the MIMIC-CXR dataset. They compare FedMLP to centralized and federated baselines, demonstrating its ability to outperform these approaches, particularly in the presence of task heterogeneity.
Critical Analysis
The paper provides a well-designed solution to the important problem of federated multi-label medical image classification, which has significant real-world applications. The authors thoughtfully address the challenges of data and task heterogeneity, which are crucial considerations for deploying federated learning in complex, real-world scenarios.
One potential limitation of the work is the use of a relatively simple multi-label perceptron model as the base architecture. While this choice allows the authors to focus on the federated learning aspects, more advanced neural network architectures, such as convolutional neural networks or transformer-based models, could potentially yield improved performance.
Additionally, the paper does not explore the impact of different client sampling strategies or communication protocols, which are important practical considerations for deploying federated learning systems. Further research could investigate the sensitivity of FedMLP to these factors.
Conclusion
The FedMLP algorithm presented in this paper is a significant contribution to the field of federated learning, particularly for multi-label medical image classification in heterogeneous environments. By addressing the challenges of data and task heterogeneity, the authors have developed a model that can learn personalized yet collaborative representations, which is crucial for sensitive domains like healthcare. The promising results suggest that FedMLP could have a transformative impact on federated learning applications in the medical domain and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FedMLP: Federated Multi-Label Medical Image Classification under Task Heterogeneity
Zhaobin Sun (School of Electronic Information and Communications, Huazhong University of Science and Technology), Nannan Wu (School of Electronic Information and Communications, Huazhong University of Science and Technology), Junjie Shi (School of Electronic Information and Communications, Huazhong University of Science and Technology), Li Yu (School of Electronic Information and Communications, Huazhong University of Science and Technology), Xin Yang (School of Electronic Information and Communications, Huazhong University of Science and Technology), Kwang-Ting Cheng (School of Engineering, Hong Kong University of Science and Technology), Zengqiang Yan (School of Electronic Information and Communications, Huazhong University of Science and Technology)
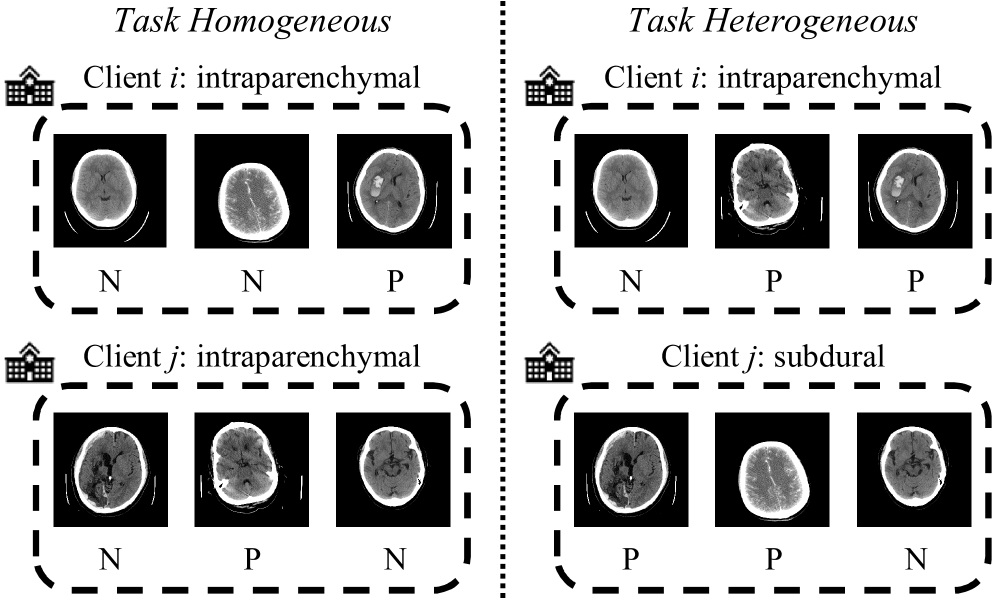
Cross-silo federated learning (FL) enables decentralized organizations to collaboratively train models while preserving data privacy and has made significant progress in medical image classification. One common assumption is task homogeneity where each client has access to all classes during training. However, in clinical practice, given a multi-label classification task, constrained by the level of medical knowledge and the prevalence of diseases, each institution may diagnose only partial categories, resulting in task heterogeneity. How to pursue effective multi-label medical image classification under task heterogeneity is under-explored. In this paper, we first formulate such a realistic label missing setting in the multi-label FL domain and propose a two-stage method FedMLP to combat class missing from two aspects: pseudo label tagging and global knowledge learning. The former utilizes a warmed-up model to generate class prototypes and select samples with high confidence to supplement missing labels, while the latter uses a global model as a teacher for consistency regularization to prevent forgetting missing class knowledge. Experiments on two publicly-available medical datasets validate the superiority of FedMLP against the state-of-the-art both federated semi-supervised and noisy label learning approaches under task heterogeneity. Code is available at https://github.com/szbonaldo/FedMLP.
Read more6/28/2024

0
On the Impact of Data Heterogeneity in Federated Learning Environments with Application to Healthcare Networks
Usevalad Milasheuski, Luca Barbieri, Bernardo Camajori Tedeschini, Monica Nicoli, Stefano Savazzi
Federated Learning (FL) allows multiple privacy-sensitive applications to leverage their dataset for a global model construction without any disclosure of the information. One of those domains is healthcare, where groups of silos collaborate in order to generate a global predictor with improved accuracy and generalization. However, the inherent challenge lies in the high heterogeneity of medical data, necessitating sophisticated techniques for assessment and compensation. This paper presents a comprehensive exploration of the mathematical formalization and taxonomy of heterogeneity within FL environments, focusing on the intricacies of medical data. In particular, we address the evaluation and comparison of the most popular FL algorithms with respect to their ability to cope with quantity-based, feature and label distribution-based heterogeneity. The goal is to provide a quantitative evaluation of the impact of data heterogeneity in FL systems for healthcare networks as well as a guideline on FL algorithm selection. Our research extends beyond existing studies by benchmarking seven of the most common FL algorithms against the unique challenges posed by medical data use cases. The paper targets the prediction of the risk of stroke recurrence through a set of tabular clinical reports collected by different federated hospital silos: data heterogeneity frequently encountered in this scenario and its impact on FL performance are discussed.
Read more9/6/2024
0
UniFed: A Universal Federation of a Mixture of Highly Heterogeneous Medical Image Classification Tasks
Atefe Hassani, Islem Rekik
A fundamental challenge in federated learning lies in mixing heterogeneous datasets and classification tasks while minimizing the high communication cost caused by clients as well as the exchange of weight updates with the server over a fixed number of rounds. This results in divergent model convergence rates and performance, which may hinder their deployment in precision medicine. In real-world scenarios, client data is collected from different hospitals with extremely varying components (e.g., imaging modality, organ type, etc). Previous studies often overlooked the convoluted heterogeneity during the training stage where the target learning tasks vary across clients as well as the dataset type and their distributions. To address such limitations, we unprecedentedly introduce UniFed, a universal federated learning paradigm that aims to classify any disease from any imaging modality. UniFed also handles the issue of varying convergence times in the client-specific optimization based on the complexity of their learning tasks. Specifically, by dynamically adjusting both local and global models, UniFed considers the varying task complexities of clients and the server, enhancing its adaptability to real-world scenarios, thereby mitigating issues related to overtraining and excessive communication. Furthermore, our framework incorporates a sequential model transfer mechanism that takes into account the diverse tasks among hospitals and a dynamic task-complexity based ordering. We demonstrate the superiority of our framework in terms of accuracy, communication cost, and convergence time over relevant benchmarks in diagnosing retina, histopathology, and liver tumour diseases under federated learning. Our UniFed code is available at https://github.com/basiralab/UniFed.
Read more8/19/2024

0
Federated Impression for Learning with Distributed Heterogeneous Data
Sana Ayromlou, Atrin Arya, Armin Saadat, Purang Abolmaesumi, Xiaoxiao Li
Standard deep learning-based classification approaches may not always be practical in real-world clinical applications, as they require a centralized collection of all samples. Federated learning (FL) provides a paradigm that can learn from distributed datasets across clients without requiring them to share data, which can help mitigate privacy and data ownership issues. In FL, sub-optimal convergence caused by data heterogeneity is common among data from different health centers due to the variety in data collection protocols and patient demographics across centers. Through experimentation in this study, we show that data heterogeneity leads to the phenomenon of catastrophic forgetting during local training. We propose FedImpres which alleviates catastrophic forgetting by restoring synthetic data that represents the global information as federated impression. To achieve this, we distill the global model resulting from each communication round. Subsequently, we use the synthetic data alongside the local data to enhance the generalization of local training. Extensive experiments show that the proposed method achieves state-of-the-art performance on both the BloodMNIST and Retina datasets, which contain label imbalance and domain shift, with an improvement in classification accuracy of up to 20%.
Read more9/12/2024