The Fellowship of the LLMs: Multi-Agent Workflows for Synthetic Preference Optimization Dataset Generation

0

Sign in to get full access
Overview
- The paper discusses a workflow for generating synthetic datasets for training large language models (LLMs) to optimize user preferences.
- It involves a multi-agent system where different agents collaborate to create high-quality preference data.
- The goal is to help train LLMs to better understand and cater to user preferences, which is important for real-world applications.
Plain English Explanation
The paper presents a method for creating synthetic data that can be used to train large language models (LLMs) to better understand and respond to user preferences. The key idea is to use a multi-agent system where different "agents" work together to generate high-quality preference data.
For example, one agent might create sample user preferences, while another agent tries to evaluate how well an LLM can interpret those preferences. By iterating this process, the system can produce a diverse and realistic dataset that LLMs can be trained on.
The goal is to help train LLMs to be more sensitive to user needs and desires, which is crucial for applications where LLMs interact directly with people, such as customer service chatbots or recommendation systems. By having access to high-quality preference data, the LLMs can learn to provide more personalized and useful responses.
Technical Explanation
The paper proposes a multi-agent workflow for generating synthetic datasets to train LLMs to optimize user preferences. The workflow involves several specialized agents that collaborate to create high-quality preference data:
- Preference Generator Agent: Generates sample user preferences, including information about user goals, constraints, and value functions.
- Preference Evaluator Agent: Assesses how well an LLM can interpret and respond to the generated preferences.
- Preference Optimizer Agent: Iteratively refines the preference samples to improve the LLM's performance.
- Dataset Aggregator Agent: Collects the refined preference samples into a cohesive dataset for training the LLM.
The agents interact through a series of negotiation and optimization steps, with the goal of converging on a dataset that challenges the LLM to fully understand and cater to user preferences. The authors demonstrate the effectiveness of this approach through experiments on synthetic and real-world preference datasets, showing that LLMs trained on the generated data perform better on preference-based tasks.
Critical Analysis
The paper presents a novel and promising approach for generating synthetic datasets to train LLMs to optimize user preferences. The multi-agent workflow is an interesting way to leverage the strengths of different specialized components to produce high-quality data.
However, the paper does not address some potential limitations and challenges of this approach:
- Scalability: The multi-agent workflow may become computationally expensive or difficult to coordinate as the number of agents and preference samples grows. The authors should discuss strategies for scaling the system to larger datasets and more complex preference domains.
- Bias and Realism: While the authors claim the generated datasets are "high-quality," it's unclear how they ensure the preferences are diverse, unbiased, and representative of real-world user behavior. Further evaluation of the dataset's realism and ecological validity would be helpful.
- Dependency on LLM Performance: The success of the workflow relies on the Preference Evaluator Agent's ability to accurately assess the LLM's performance on preference-based tasks. If this component is not well-calibrated, it could lead to suboptimal dataset generation.
Despite these potential issues, the overall approach is novel and has promising applications in training LLMs to better understand and cater to user preferences, which is an important capability for real-world deployment of these models.
Conclusion
The paper presents a multi-agent workflow for generating synthetic datasets to train LLMs to optimize user preferences. By leveraging specialized agents to iteratively refine the preference data, the authors demonstrate improvements in the LLMs' performance on preference-based tasks.
This work has significant implications for the development of LLMs that can better understand and respond to user needs, which is crucial for real-world applications such as customer service, recommendation systems, and interactive assistants. While the approach has some potential limitations, the overall concept is innovative and could inspire further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Fellowship of the LLMs: Multi-Agent Workflows for Synthetic Preference Optimization Dataset Generation
Samee Arif, Sualeha Farid, Abdul Hameed Azeemi, Awais Athar, Agha Ali Raza
This paper presents synthetic Preference Optimization (PO) datasets generated using multi-agent workflows and evaluates the effectiveness and potential of these workflows in the dataset generation process. PO dataset generation requires two modules: (1) response evaluation, and (2) response generation. In the response evaluation module, the responses from Large Language Models (LLMs) are evaluated and ranked - a task typically carried out by human annotators that we automate using LLMs. We assess the response evaluation module in a 2 step process. In step 1, we assess LLMs as evaluators using three distinct prompting strategies. In step 2, we apply the winning prompting strategy to compare the performance of LLM-as-a-Judge, LLMs-as-a-Jury, and LLM Debate. In each step, we use inter-rater agreement using Cohen's Kappa between human annotators and LLMs. For the response generation module, we compare different configurations for the LLM Feedback Loop using the identified LLM evaluator configuration. We use the win rate (the fraction of times a generation framework is selected as the best by an LLM evaluator) to determine the best multi-agent configuration for generation. After identifying the best configurations for both modules, we use models from the GPT, Gemma, and Llama families to generate our PO datasets using the above pipeline. We generate two types of PO datasets, one to improve the generation capabilities of individual LLM and the other to improve the multi-agent workflow. Our evaluation shows that GPT-4o-as-a-Judge is more consistent across datasets when the candidate responses do not include responses from the GPT family. Additionally, we find that the LLM Feedback Loop, with Llama as the generator and Gemma as the reviewer, achieves a notable 71.8% and 73.8% win rate over single-agent Llama and Gemma, respectively.
Read more9/10/2024

0
LLM-based multi-agent poetry generation in non-cooperative environments
Ran Zhang, Steffen Eger
Despite substantial progress of large language models (LLMs) for automatic poetry generation, the generated poetry lacks diversity while the training process differs greatly from human learning. Under the rationale that the learning process of the poetry generation systems should be more human-like and their output more diverse and novel, we introduce a framework based on social learning where we emphasize non-cooperative interactions besides cooperative interactions to encourage diversity. Our experiments are the first attempt at LLM-based multi-agent systems in non-cooperative environments for poetry generation employing both TRAINING-BASED agents (GPT-2) and PROMPTING-BASED agents (GPT-3 and GPT-4). Our evaluation based on 96k generated poems shows that our framework benefits the poetry generation process for TRAINING-BASED agents resulting in 1) a 3.0-3.7 percentage point (pp) increase in diversity and a 5.6-11.3 pp increase in novelty according to distinct and novel n-grams. The generated poetry from TRAINING-BASED agents also exhibits group divergence in terms of lexicons, styles and semantics. PROMPTING-BASED agents in our framework also benefit from non-cooperative environments and a more diverse ensemble of models with non-homogeneous agents has the potential to further enhance diversity, with an increase of 7.0-17.5 pp according to our experiments. However, PROMPTING-BASED agents show a decrease in lexical diversity over time and do not exhibit the group-based divergence intended in the social network. Our paper argues for a paradigm shift in creative tasks such as automatic poetry generation to include social learning processes (via LLM-based agent modeling) similar to human interaction.
Read more9/9/2024
0
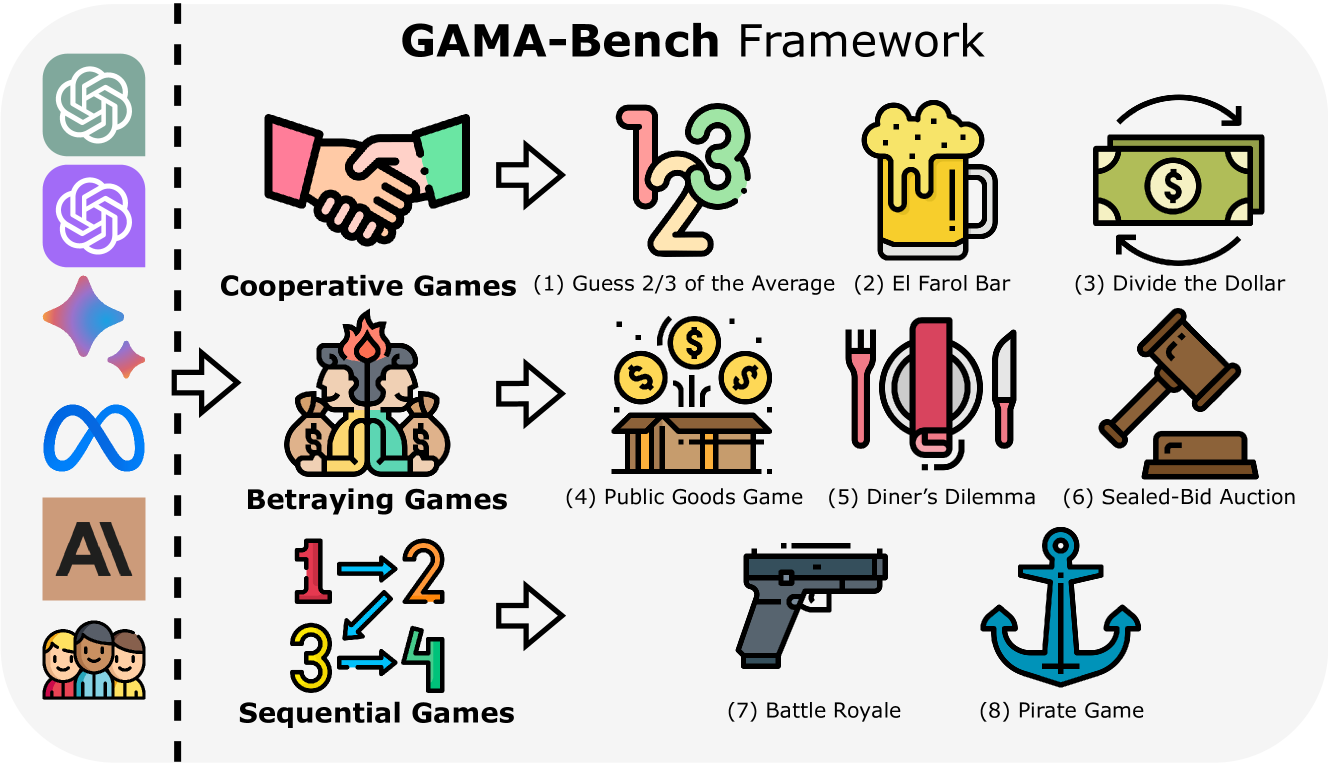
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
Decision-making, a complicated task requiring various types of abilities, presents an excellent framework for assessing Large Language Models (LLMs). Our research investigates decision-making capabilities of LLMs through the lens of Game Theory. We focus specifically on games that support the simultaneous participation of more than two agents. We introduce GAMA($gamma$)-Bench, which evaluates LLMs' Gaming Ability in Multi-Agent environments. $gamma$-Bench includes eight classical multi-agent games and a scoring scheme specially designed to quantitatively assess LLMs' performance. Leveraging $gamma$-Bench, we investigate LLMs' robustness, generalizability, and strategies for enhancement. Results reveal that while GPT-3.5 shows satisfying robustness, its generalizability is relatively limited. However, its performance can be improved through approaches such as Chain-of-Thought. Additionally, we evaluate twelve versions from six models, including GPT-3.5, GPT-4, Gemini, LLaMA-3.1, Mixtral, and Qwen-2. We find that Gemini-1.5-Pro outperforms other models with a score of $63.8$ out of $100$, followed by LLaMA-3.1-70B and GPT-4 with scores of $60.9$ and $60.5$, respectively. The code and experimental results are made publicly available via https://github.com/CUHK-ARISE/GAMABench.
Read more9/4/2024
0
Cooperation, Competition, and Maliciousness: LLM-Stakeholders Interactive Negotiation
Sahar Abdelnabi, Amr Gomaa, Sarath Sivaprasad, Lea Schonherr, Mario Fritz
There is an growing interest in using Large Language Models (LLMs) in multi-agent systems to tackle interactive real-world tasks that require effective collaboration and assessing complex situations. Yet, we still have a limited understanding of LLMs' communication and decision-making abilities in multi-agent setups. The fundamental task of negotiation spans many key features of communication, such as cooperation, competition, and manipulation potentials. Thus, we propose using scorable negotiation to evaluate LLMs. We create a testbed of complex multi-agent, multi-issue, and semantically rich negotiation games. To reach an agreement, agents must have strong arithmetic, inference, exploration, and planning capabilities while integrating them in a dynamic and multi-turn setup. We propose multiple metrics to rigorously quantify agents' performance and alignment with the assigned role. We provide procedures to create new games and increase games' difficulty to have an evolving benchmark. Importantly, we evaluate critical safety aspects such as the interaction dynamics between agents influenced by greedy and adversarial players. Our benchmark is highly challenging; GPT-3.5 and small models mostly fail, and GPT-4 and SoTA large models (e.g., Llama-3 70b) still underperform.
Read more6/11/2024