Few-Shot Domain Adaptation for Learned Image Compression

0
Sign in to get full access
Overview
- Proposes a few-shot domain adaptation approach for learned image compression
- Aims to improve performance on new image domains with limited training data
- Combines transfer learning and meta-learning techniques
Plain English Explanation
The paper explores a technique called few-shot domain adaptation for improving the performance of learned image compression models on new image domains. Learned image compression uses machine learning to encode and decode images more efficiently than traditional methods.
The challenge is that these models may not perform well when applied to new types of images that differ from their original training data. The few-shot domain adaptation approach proposed in the paper attempts to address this by quickly adapting the model to a new domain using only a small amount of training data from that domain.
The method combines transfer learning techniques, which leverage knowledge gained from a prior task, with meta-learning approaches that allow the model to learn how to adapt efficiently. This allows the compressed image quality to be maintained even when the model is applied to new types of images.
Technical Explanation
The paper presents a few-shot domain adaptation framework for learned image compression. The core idea is to leverage transfer learning and meta-learning to quickly adapt a pre-trained compression model to a new target domain using only a small number of training samples.
The model consists of an encoder, which compresses the input image, and a decoder, which reconstructs the image from the compressed representation. During the meta-training phase, the model is exposed to multiple source domains and learns to rapidly adapt its parameters to a new target domain using only a few gradient updates.
This meta-learning process is guided by a bi-level optimization procedure that jointly optimizes the model's initial parameters and the adaptation strategy. The inner optimization updates the model's weights to minimize the reconstruction loss on the target domain, while the outer optimization updates the initial parameters and adaptation strategy to perform well on average across multiple target domains.
At inference time, the pre-trained model is fine-tuned on a small number of samples from the target domain using the learned adaptation strategy, allowing it to maintain high compression performance even on new types of images.
The authors evaluate their approach on several benchmark datasets and demonstrate significant improvements over standard fine-tuning and few-shot learning baselines, highlighting the effectiveness of the proposed few-shot domain adaptation framework for learned image compression.
Critical Analysis
The paper presents a promising approach for improving the performance of learned image compression models on new domains. The combination of transfer learning and meta-learning techniques allows the model to adapt quickly to new data distributions, which is an important capability for practical deployment of these models.
However, the authors acknowledge that the proposed method may be limited by the availability of diverse source domains during meta-training. If the meta-training data does not sufficiently cover the space of possible target domains, the model's ability to adapt may be constrained.
Additionally, the paper does not explore the computational and memory overhead of the meta-learning process, which could be a concern for real-world applications with limited resources. Further analysis of the trade-offs between adaptation performance and model complexity would be valuable.
Overall, the work presents a compelling approach to the challenge of domain adaptation for learned image compression, and the insights could be relevant to other areas of machine learning where adapting models to new data distributions is crucial.
Conclusion
This paper introduces a few-shot domain adaptation framework for learned image compression, which leverages transfer learning and meta-learning to enable rapid adaptation of a pre-trained model to new target domains. The proposed approach demonstrates strong performance on benchmark datasets, highlighting its potential to improve the practical deployment of learned image compression techniques.
While the method has some limitations, such as the need for diverse meta-training data, the paper contributes valuable insights into the challenges of domain adaptation for image compression and provides a promising direction for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Few-Shot Domain Adaptation for Learned Image Compression
Tianyu Zhang, Haotian Zhang, Yuqi Li, Li Li, Dong Liu
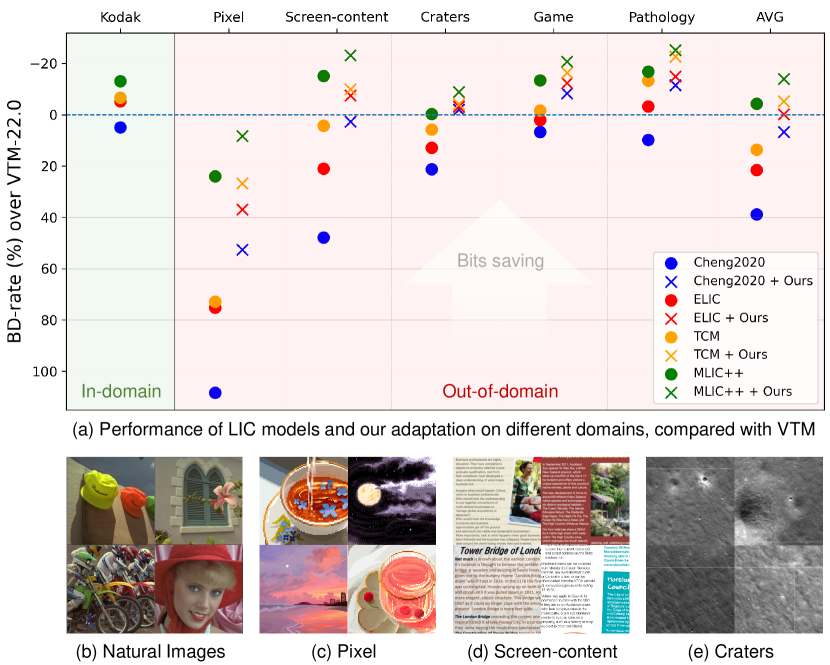
Learned image compression (LIC) has achieved state-of-the-art rate-distortion performance, deemed promising for next-generation image compression techniques. However, pre-trained LIC models usually suffer from significant performance degradation when applied to out-of-training-domain images, implying their poor generalization capabilities. To tackle this problem, we propose a few-shot domain adaptation method for LIC by integrating plug-and-play adapters into pre-trained models. Drawing inspiration from the analogy between latent channels and frequency components, we examine domain gaps in LIC and observe that out-of-training-domain images disrupt pre-trained channel-wise decomposition. Consequently, we introduce a method for channel-wise re-allocation using convolution-based adapters and low-rank adapters, which are lightweight and compatible to mainstream LIC schemes. Extensive experiments across multiple domains and multiple representative LIC schemes demonstrate that our method significantly enhances pre-trained models, achieving comparable performance to H.266/VVC intra coding with merely 25 target-domain samples. Additionally, our method matches the performance of full-model finetune while transmitting fewer than $2%$ of the parameters.
Read more9/18/2024

0
Rethinking Learned Image Compression: Context is All You Need
Jixiang Luo
Since LIC has made rapid progress recently compared to traditional methods, this paper attempts to discuss the question about 'Where is the boundary of Learned Image Compression(LIC)?'. Thus this paper splits the above problem into two sub-problems:1)Where is the boundary of rate-distortion performance of PSNR? 2)How to further improve the compression gain and achieve the boundary? Therefore this paper analyzes the effectiveness of scaling parameters for encoder, decoder and context model, which are the three components of LIC. Then we conclude that scaling for LIC is to scale for context model and decoder within LIC. Extensive experiments demonstrate that overfitting can actually serve as an effective context. By optimizing the context, this paper further improves PSNR and achieves state-of-the-art performance, showing a performance gain of 14.39% with BD-RATE over VVC.
Read more8/6/2024
🖼️
0
CIC: Circular Image Compression
Honggui Li, Sinan Chen, Nahid Md Lokman Hossain, Maria Trocan, Beata Mikovicova, Muhammad Fahimullah, Dimitri Galayko, Mohamad Sawan
Learned image compression (LIC) is currently the cutting-edge method. However, the inherent difference between testing and training images of LIC results in performance degradation to some extent. Especially for out-of-sample, out-of-distribution, or out-of-domain testing images, the performance of LIC dramatically degraded. Classical LIC is a serial image compression (SIC) approach that utilizes an open-loop architecture with serial encoding and decoding units. Nevertheless, according to the theory of automatic control, a closed-loop architecture holds the potential to improve the dynamic and static performance of LIC. Therefore, a circular image compression (CIC) approach with closed-loop encoding and decoding elements is proposed to minimize the gap between testing and training images and upgrade the capability of LIC. The proposed CIC establishes a nonlinear loop equation and proves that steady-state error between reconstructed and original images is close to zero by Talor series expansion. The proposed CIC method possesses the property of Post-Training and plug-and-play which can be built on any existing advanced SIC methods. Experimental results on five public image compression datasets demonstrate that the proposed CIC outperforms five open-source state-of-the-art competing SIC algorithms in reconstruction capacity. Experimental results further show that the proposed method is suitable for out-of-sample testing images with dark backgrounds, sharp edges, high contrast, grid shapes, or complex patterns.
Read more7/24/2024

0
Rethinking Domain Adaptation and Generalization in the Era of CLIP
Ruoyu Feng, Tao Yu, Xin Jin, Xiaoyuan Yu, Lei Xiao, Zhibo Chen
In recent studies on domain adaptation, significant emphasis has been placed on the advancement of learning shared knowledge from a source domain to a target domain. Recently, the large vision-language pre-trained model, i.e., CLIP has shown strong ability on zero-shot recognition, and parameter efficient tuning can further improve its performance on specific tasks. This work demonstrates that a simple domain prior boosts CLIP's zero-shot recognition in a specific domain. Besides, CLIP's adaptation relies less on source domain data due to its diverse pre-training dataset. Furthermore, we create a benchmark for zero-shot adaptation and pseudo-labeling based self-training with CLIP. Last but not least, we propose to improve the task generalization ability of CLIP from multiple unlabeled domains, which is a more practical and unique scenario. We believe our findings motivate a rethinking of domain adaptation benchmarks and the associated role of related algorithms in the era of CLIP.
Read more7/23/2024