Few-shot point cloud reconstruction and denoising via learned Guassian splats renderings and fine-tuned diffusion features
2404.01112
0
0
📶
Abstract
Existing deep learning methods for the reconstruction and denoising of point clouds rely on small datasets of 3D shapes. We circumvent the problem by leveraging deep learning methods trained on billions of images. We propose a method to reconstruct point clouds from few images and to denoise point clouds from their rendering by exploiting prior knowledge distilled from image-based deep learning models. To improve reconstruction in constraint settings, we regularize the training of a differentiable renderer with hybrid surface and appearance by introducing semantic consistency supervision. In addition, we propose a pipeline to finetune Stable Diffusion to denoise renderings of noisy point clouds and we demonstrate how these learned filters can be used to remove point cloud noise coming without 3D supervision. We compare our method with DSS and PointRadiance and achieved higher quality 3D reconstruction on the Sketchfab Testset and SCUT Dataset.
Create account to get full access
Overview
- Existing deep learning methods for reconstructing and denoising point clouds rely on small datasets of 3D shapes.
- The researchers propose a method to reconstruct point clouds from few images and denoise point clouds by leveraging deep learning models trained on billions of images.
- They introduce a regularization technique to improve reconstruction in constrained settings and a pipeline to fine-tune Stable Diffusion to denoise renderings of noisy point clouds.
- The method outperforms previous approaches on 3D reconstruction benchmarks.
Plain English Explanation
Point clouds are 3D data representations made up of many individual points. They are useful in a variety of applications, from virtual reality to autonomous vehicles. However, existing deep learning techniques for reconstructing and cleaning up point clouds often rely on small, limited datasets of 3D shapes.
The researchers in this paper found a clever way around this problem. Instead of using small 3D datasets, they leveraged deep learning models that had been trained on billions of 2D images. By combining these powerful image-based models with some new techniques, they were able to reconstruct point clouds from just a few input images. They also developed a way to "clean up" or denoise point clouds by having their system learn from examples of noisy and clean point cloud renderings.
To make their reconstruction technique work better in constrained settings, the researchers added a "semantic consistency" regularization step. This helped the system maintain the proper shape and appearance of the reconstructed 3D objects. They also fine-tuned the well-known Stable Diffusion AI model to denoise point cloud renderings, without needing any 3D training data.
Overall, this research shows how we can tap into the vast troves of 2D image data to tackle challenging 3D reconstruction and denoising problems, opening up new possibilities in fields like robotics, virtual reality, and beyond.
Technical Explanation
The key technical contributions of this paper are:
- A method to reconstruct point clouds from few input images by leveraging deep learning models trained on large 2D image datasets.
- A technique to denoise point clouds by fine-tuning the Stable Diffusion AI model on examples of noisy and clean point cloud renderings.
- A regularization approach that enforces "semantic consistency" during the point cloud reconstruction process, helping to maintain the proper shape and appearance of 3D objects.
The researchers first train a differentiable renderer that can generate 2D image renderings of 3D point clouds. They then use this renderer to train a point cloud reconstruction model, taking inspiration from successful image-to-image translation techniques.
To improve reconstruction in constrained settings (e.g. with few input images), the team introduces a semantic consistency loss. This loss term encourages the reconstructed point clouds to align with the visual semantics of the input images, leading to more faithful 3D reconstructions.
For point cloud denoising, the researchers propose a pipeline to fine-tune the Stable Diffusion model. This large, pre-trained AI system is adapted to the task of removing noise from point cloud renderings, without requiring any 3D training data.
Experiments show that this combined approach of leveraging 2D image models, semantic consistency regularization, and Stable Diffusion finetuning outperforms previous state-of-the-art methods for point cloud reconstruction and denoising.
Critical Analysis
The paper makes a compelling case for how large 2D image datasets can be leveraged to tackle 3D reconstruction and denoising problems, which traditionally have relied on limited 3D training data. The researchers' technical innovations, like the semantic consistency regularization and the Stable Diffusion finetuning pipeline, are clever and well-executed.
That said, the paper does not explore some potential limitations or edge cases of the proposed methods. For example, it's unclear how well the techniques would generalize to highly complex or unusual 3D shapes that differ significantly from the training data. The denoising approach also seems to assume a specific type of noise, and may not work as well for more diverse noise patterns.
Additionally, while the Stable Diffusion finetuning is an interesting idea, the paper does not provide a deep analysis of the model's inner workings or the rationale behind this particular approach. Readers may be left wondering about the theoretical underpinnings and potential failure modes of this component.
Overall, this is a strong piece of research that demonstrates the power of leveraging 2D image data for 3D tasks. However, further exploration of the method's limitations and robustness would help provide a more comprehensive understanding of its capabilities and potential real-world applications.
Conclusion
This paper presents a novel approach to point cloud reconstruction and denoising that sidesteps the traditional reliance on limited 3D training data. By tapping into the wealth of 2D image datasets and combining it with technical innovations like semantic consistency regularization and Stable Diffusion finetuning, the researchers have developed a highly effective system for tackling these 3D challenges.
The results show significant improvements over previous state-of-the-art methods, suggesting that this kind of hybrid 2D-3D approach could have widespread implications for fields like robotics, virtual reality, and autonomous vehicles. As 3D data becomes increasingly important in our digital world, techniques like these will be crucial for unlocking the full potential of point cloud technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
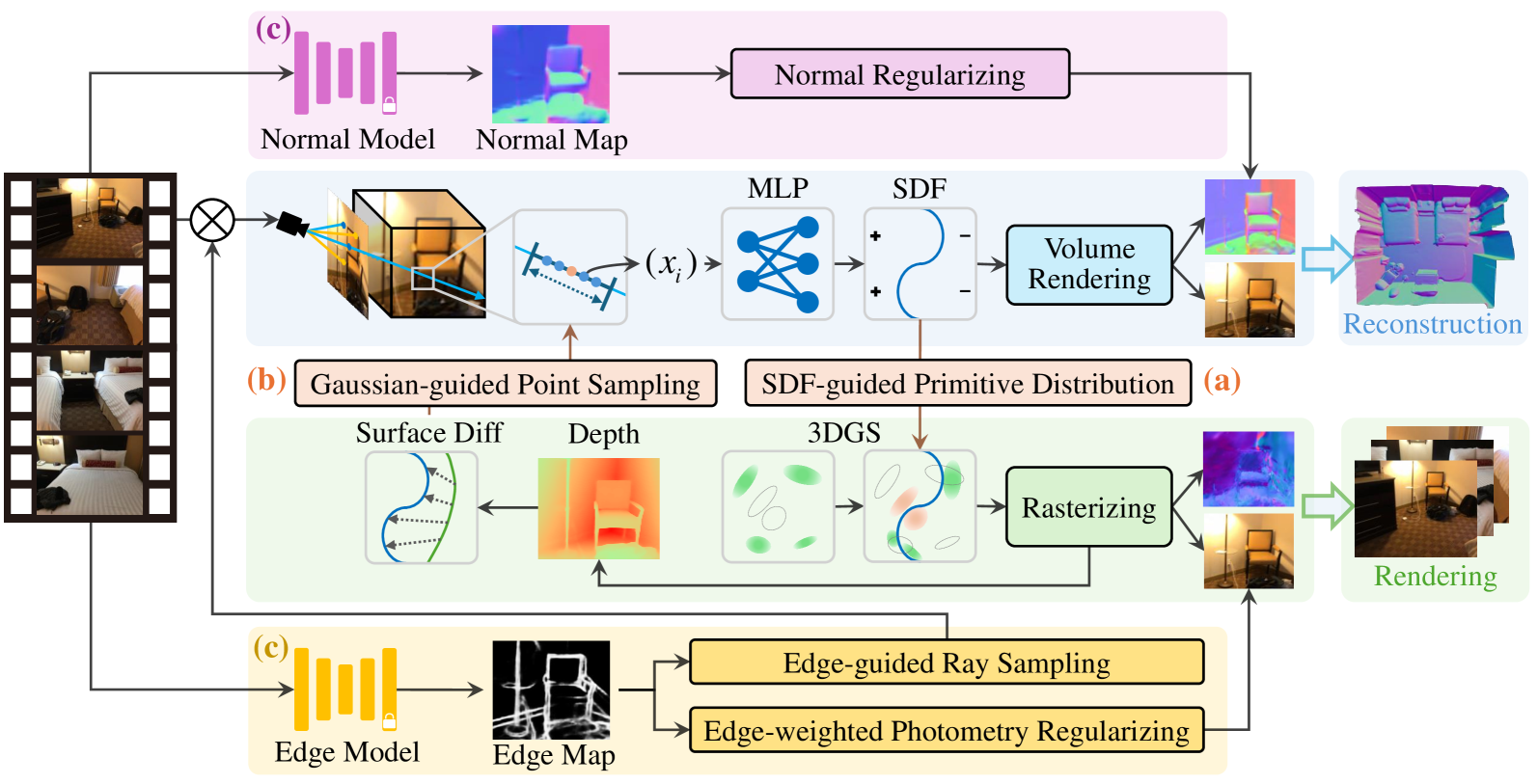
GaussianRoom: Improving 3D Gaussian Splatting with SDF Guidance and Monocular Cues for Indoor Scene Reconstruction
Haodong Xiang, Xinghui Li, Xiansong Lai, Wanting Zhang, Zhichao Liao, Kai Cheng, Xueping Liu
0
0
Recently, 3D Gaussian Splatting(3DGS) has revolutionized neural rendering with its high-quality rendering and real-time speed. However, when it comes to indoor scenes with a significant number of textureless areas, 3DGS yields incomplete and noisy reconstruction results due to the poor initialization of the point cloud and under-constrained optimization. Inspired by the continuity of signed distance field (SDF), which naturally has advantages in modeling surfaces, we present a unified optimizing framework integrating neural SDF with 3DGS. This framework incorporates a learnable neural SDF field to guide the densification and pruning of Gaussians, enabling Gaussians to accurately model scenes even with poor initialized point clouds. At the same time, the geometry represented by Gaussians improves the efficiency of the SDF field by piloting its point sampling. Additionally, we regularize the optimization with normal and edge priors to eliminate geometry ambiguity in textureless areas and improve the details. Extensive experiments in ScanNet and ScanNet++ show that our method achieves state-of-the-art performance in both surface reconstruction and novel view synthesis.
5/31/2024
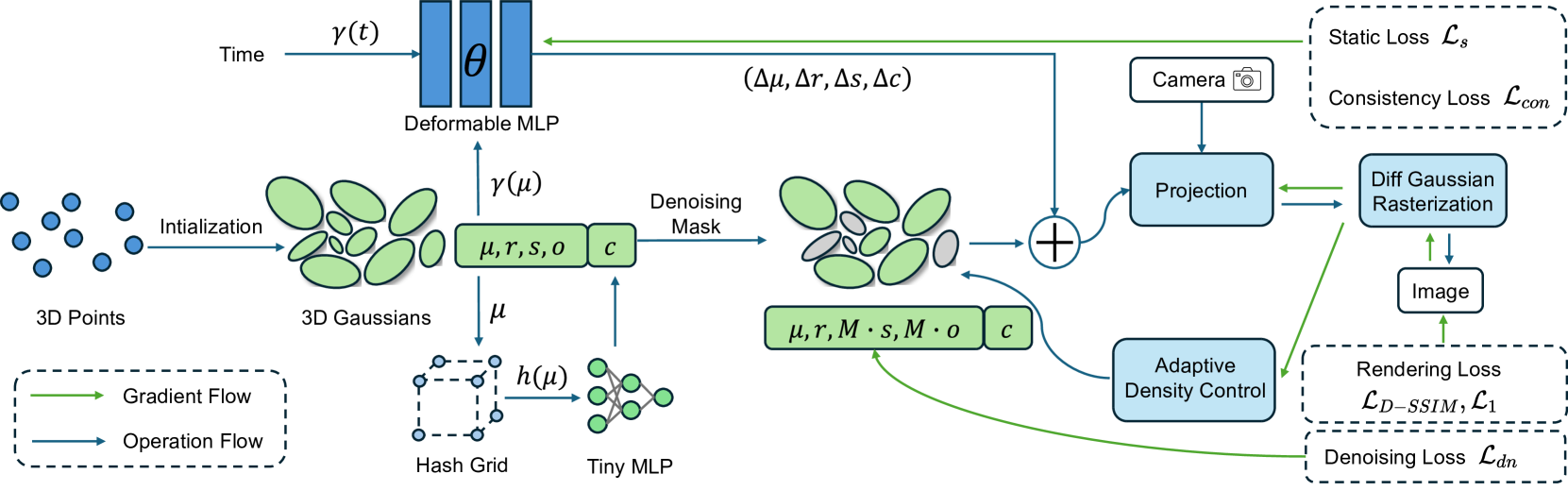
A Refined 3D Gaussian Representation for High-Quality Dynamic Scene Reconstruction
Bin Zhang, Bi Zeng, Zexin Peng
0
0
In recent years, Neural Radiance Fields (NeRF) has revolutionized three-dimensional (3D) reconstruction with its implicit representation. Building upon NeRF, 3D Gaussian Splatting (3D-GS) has departed from the implicit representation of neural networks and instead directly represents scenes as point clouds with Gaussian-shaped distributions. While this shift has notably elevated the rendering quality and speed of radiance fields but inevitably led to a significant increase in memory usage. Additionally, effectively rendering dynamic scenes in 3D-GS has emerged as a pressing challenge. To address these concerns, this paper purposes a refined 3D Gaussian representation for high-quality dynamic scene reconstruction. Firstly, we use a deformable multi-layer perceptron (MLP) network to capture the dynamic offset of Gaussian points and express the color features of points through hash encoding and a tiny MLP to reduce storage requirements. Subsequently, we introduce a learnable denoising mask coupled with denoising loss to eliminate noise points from the scene, thereby further compressing 3D Gaussian model. Finally, motion noise of points is mitigated through static constraints and motion consistency constraints. Experimental results demonstrate that our method surpasses existing approaches in rendering quality and speed, while significantly reducing the memory usage associated with 3D-GS, making it highly suitable for various tasks such as novel view synthesis, and dynamic mapping.
5/29/2024

Bootstrap 3D Reconstructed Scenes from 3D Gaussian Splatting
Yifei Gao, Jie Ou, Lei Wang, Jun Cheng
0
0
Recent developments in neural rendering techniques have greatly enhanced the rendering of photo-realistic 3D scenes across both academic and commercial fields. The latest method, known as 3D Gaussian Splatting (3D-GS), has set new benchmarks for rendering quality and speed. Nevertheless, the limitations of 3D-GS become pronounced in synthesizing new viewpoints, especially for views that greatly deviate from those seen during training. Additionally, issues such as dilation and aliasing arise when zooming in or out. These challenges can all be traced back to a single underlying issue: insufficient sampling. In our paper, we present a bootstrapping method that significantly addresses this problem. This approach employs a diffusion model to enhance the rendering of novel views using trained 3D-GS, thereby streamlining the training process. Our results indicate that bootstrapping effectively reduces artifacts, as well as clear enhancements on the evaluation metrics. Furthermore, we show that our method is versatile and can be easily integrated, allowing various 3D reconstruction projects to benefit from our approach.
5/14/2024
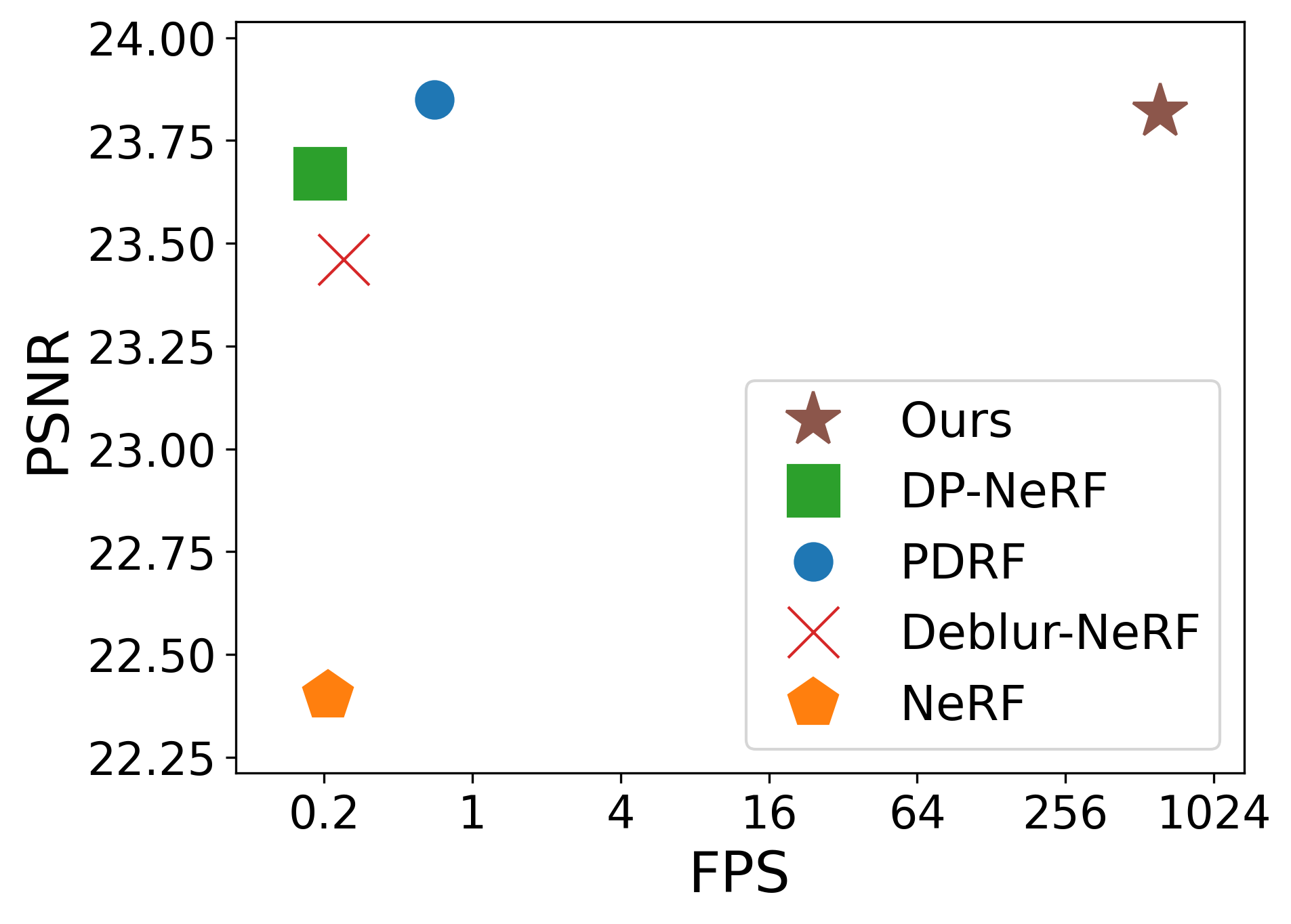
Deblurring 3D Gaussian Splatting
Byeonghyeon Lee, Howoong Lee, Xiangyu Sun, Usman Ali, Eunbyung Park
0
0
Recent studies in Radiance Fields have paved the robust way for novel view synthesis with their photorealistic rendering quality. Nevertheless, they usually employ neural networks and volumetric rendering, which are costly to train and impede their broad use in various real-time applications due to the lengthy rendering time. Lately 3D Gaussians splatting-based approach has been proposed to model the 3D scene, and it achieves remarkable visual quality while rendering the images in real-time. However, it suffers from severe degradation in the rendering quality if the training images are blurry. Blurriness commonly occurs due to the lens defocusing, object motion, and camera shake, and it inevitably intervenes in clean image acquisition. Several previous studies have attempted to render clean and sharp images from blurry input images using neural fields. The majority of those works, however, are designed only for volumetric rendering-based neural radiance fields and are not straightforwardly applicable to rasterization-based 3D Gaussian splatting methods. Thus, we propose a novel real-time deblurring framework, Deblurring 3D Gaussian Splatting, using a small Multi-Layer Perceptron (MLP) that manipulates the covariance of each 3D Gaussian to model the scene blurriness. While Deblurring 3D Gaussian Splatting can still enjoy real-time rendering, it can reconstruct fine and sharp details from blurry images. A variety of experiments have been conducted on the benchmark, and the results have revealed the effectiveness of our approach for deblurring. Qualitative results are available at https://benhenryl.github.io/Deblurring-3D-Gaussian-Splatting/
5/28/2024