Filtered Corpus Training (FiCT) Shows that Language Models can Generalize from Indirect Evidence
2405.15750
0
0
Abstract
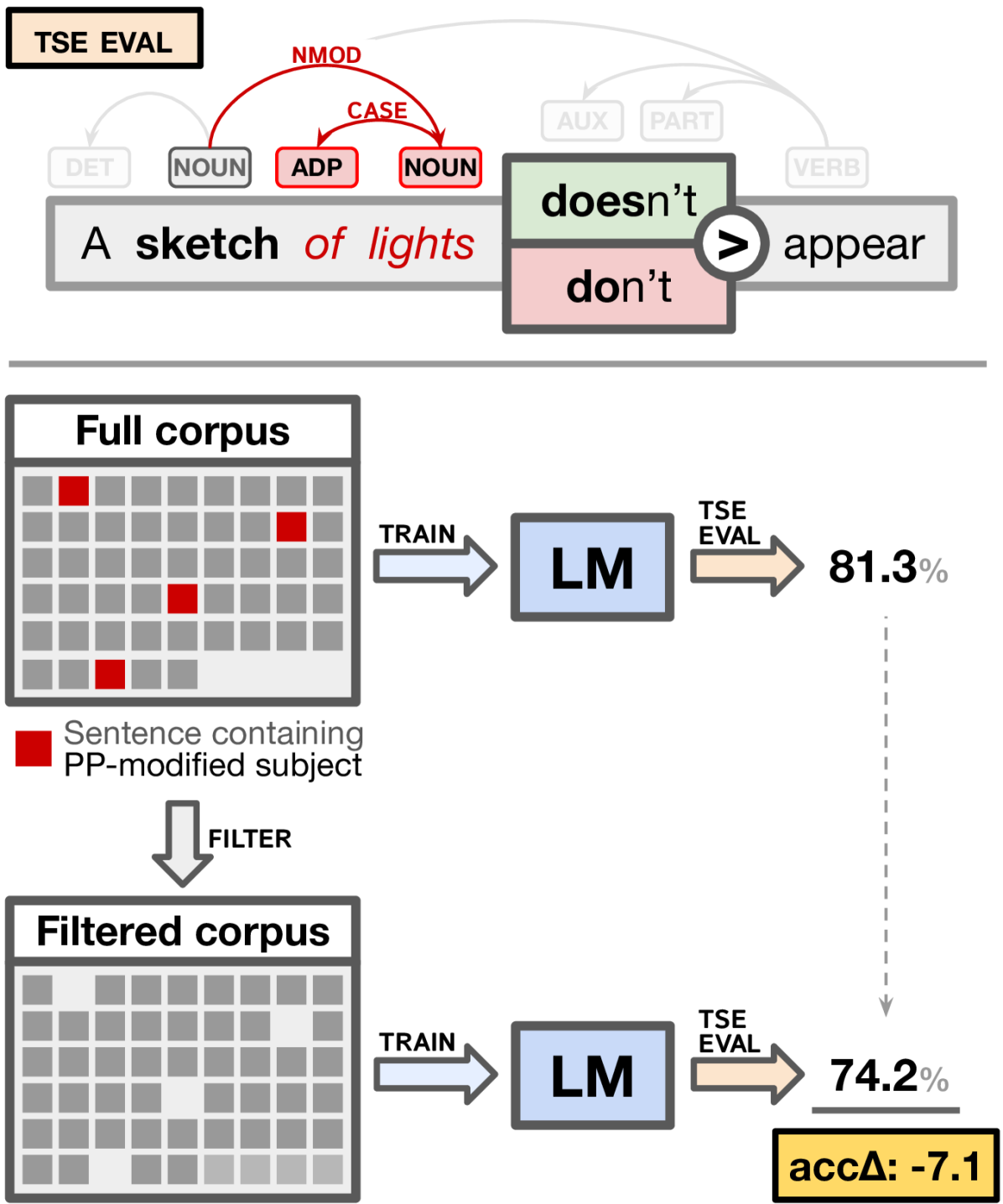
This paper introduces Filtered Corpus Training, a method that trains language models (LMs) on corpora with certain linguistic constructions filtered out from the training data, and uses it to measure the ability of LMs to perform linguistic generalization on the basis of indirect evidence. We apply the method to both LSTM and Transformer LMs (of roughly comparable size), developing filtered corpora that target a wide range of linguistic phenomena. Our results show that while transformers are better qua LMs (as measured by perplexity), both models perform equally and surprisingly well on linguistic generalization measures, suggesting that they are capable of generalizing from indirect evidence.
Create account to get full access
Overview
- This paper shows that language models can learn to generalize from indirect evidence in a training corpus, even when that evidence is filtered out.
- The researchers used a technique called Filtered Corpus Training (FiCT) to train language models on a corpus where certain types of information were deliberately removed.
- Despite this filtering, the models were still able to acquire knowledge about those filtered-out topics and generalize that knowledge to new contexts.
- This finding suggests that language models can learn abstract patterns and relationships from data, rather than just memorizing surface-level facts.
Plain English Explanation
Language models are artificial intelligence systems that are trained on large amounts of text data to learn the patterns and structures of human language. These models can then be used to generate, understand, and analyze text in powerful ways.
In this research paper, the authors explored a technique called Filtered Corpus Training (FiCT) to see how language models would perform when certain types of information were intentionally removed from their training data. The idea was to see if the models could still acquire relevant knowledge and generalize that knowledge, even when the direct evidence for it was filtered out.
For example, imagine training a language model on a corpus of text that had all references to "dogs" removed. You might expect the model to have a hard time understanding or discussing dogs afterwards. But the researchers found that the models were still able to learn about dogs and use that knowledge effectively, even without seeing direct mentions of dogs in the training data.
This suggests that language models don't just memorize individual facts and details. Instead, they are able to pick up on more abstract patterns and relationships in the data, and then apply that understanding to new situations and contexts. This is an important insight, as it means these models may be able to generalize their knowledge in powerful and unexpected ways.
The findings from this research have implications for how we think about training and deploying language models, particularly in sensitive domains where certain information needs to be filtered or obscured. It shows that even with such filtering, the models may still be able to acquire relevant knowledge and use it effectively.
Technical Explanation
The key innovation in this paper is the Filtered Corpus Training (FiCT) technique, which the authors used to train language models on a corpus where certain types of information had been deliberately removed or filtered out.
Specifically, the researchers took a standard training corpus for language models and modified it to remove all direct mentions of certain target concepts, like "dogs" or "politics." They then trained language models on this filtered corpus and evaluated how well the models were able to acquire knowledge about and reason about the filtered-out concepts.
Surprisingly, the authors found that despite the lack of direct evidence in the training data, the language models were still able to learn about and generalize the filtered-out concepts quite effectively. For example, even without seeing any explicit references to dogs in the training corpus, the models were still able to understand and discuss dogs when prompted.
The authors hypothesize that this is because language models are able to pick up on more abstract patterns and relationships in the training data, rather than just memorizing individual facts and details. By detecting indirect cues and connections in the remaining text, the models were able to construct a broader, more generalized understanding that allowed them to reason about the filtered-out topics.
This finding has important implications for how we think about the capabilities and limitations of language models. It suggests that these models may be able to acquire and apply knowledge in more flexible and powerful ways than previously thought, even when the direct evidence for that knowledge is obscured or removed from the training corpus.
The authors also discuss some potential caveats and limitations of their work, such as the specific types of filtering they explored and the potential for biases or blind spots to arise when important information is removed from the training data. They encourage further research to explore the boundaries and robustness of this generalization ability.
Critical Analysis
The findings presented in this paper are quite remarkable and raise interesting questions about the nature of language model learning and knowledge representation. The authors provide a well-designed set of experiments to systematically explore the ability of language models to generalize from indirect evidence, and their results are both surprising and compelling.
One potential limitation worth considering is the scope and nature of the filtering applied in this study. The authors focused on removing explicit mentions of certain target concepts, but it's possible that more subtle or distributed forms of information about those concepts remained in the training data. Further research could explore the limits of this generalization ability by considering more aggressive or multi-faceted forms of filtering.
Additionally, while the authors discuss potential biases or blind spots that could arise from filtering, it would be valuable to see a more in-depth analysis of these issues. For example, how might the specific choices of what to filter influence the types of knowledge that the models are able to acquire and apply? Are there certain kinds of information that are particularly vulnerable to being obscured or lost through filtering?
Overall, this paper makes an important contribution to our understanding of language model capabilities and highlights the need for continued careful study of these powerful AI systems. By exploring the boundaries of what language models can learn and how they represent knowledge, researchers can work towards developing more robust, transparent, and trustworthy AI systems.
Conclusion
This research paper presents a compelling case that language models can generalize and acquire knowledge even when that knowledge is deliberately obscured or filtered out of their training data. The Filtered Corpus Training (FiCT) technique allowed the authors to systematically explore the limits of language model learning, and their findings challenge some common assumptions about how these models work.
The ability of language models to construct abstract, generalized understandings from indirect evidence has significant implications for how we think about training and deploying these systems, particularly in sensitive domains where certain information may need to be filtered or obscured. It also raises intriguing questions about the nature of language model knowledge representation and the types of reasoning and generalization they are capable of.
Overall, this research represents an important advance in our understanding of the capabilities and limitations of large language models. By continuing to push the boundaries of what these systems can do, researchers can work towards developing more robust, reliable, and trustworthy AI technologies that can be responsibly applied to a wide range of real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Surprising Efficacy of Fine-Tuned Transformers for Fact-Checking over Larger Language Models
Vinay Setty
0
0
In this paper, we explore the challenges associated with establishing an end-to-end fact-checking pipeline in a real-world context, covering over 90 languages. Our real-world experimental benchmarks demonstrate that fine-tuning Transformer models specifically for fact-checking tasks, such as claim detection and veracity prediction, provide superior performance over large language models (LLMs) like GPT-4, GPT-3.5-Turbo, and Mistral-7b. However, we illustrate that LLMs excel in generative tasks such as question decomposition for evidence retrieval. Through extensive evaluation, we show the efficacy of fine-tuned models for fact-checking in a multilingual setting and complex claims that include numerical quantities.
5/1/2024
💬
Your Large Language Models Are Leaving Fingerprints
Hope McGovern, Rickard Stureborg, Yoshi Suhara, Dimitris Alikaniotis
0
0
It has been shown that finetuned transformers and other supervised detectors effectively distinguish between human and machine-generated text in some situations arXiv:2305.13242, but we find that even simple classifiers on top of n-gram and part-of-speech features can achieve very robust performance on both in- and out-of-domain data. To understand how this is possible, we analyze machine-generated output text in five datasets, finding that LLMs possess unique fingerprints that manifest as slight differences in the frequency of certain lexical and morphosyntactic features. We show how to visualize such fingerprints, describe how they can be used to detect machine-generated text and find that they are even robust across textual domains. We find that fingerprints are often persistent across models in the same model family (e.g. llama-13b vs. llama-65b) and that models fine-tuned for chat are easier to detect than standard language models, indicating that LLM fingerprints may be directly induced by the training data.
5/24/2024
Large Language Model-guided Document Selection
Xiang Kong, Tom Gunter, Ruoming Pang
0
0
Large Language Model (LLM) pre-training exhausts an ever growing compute budget, yet recent research has demonstrated that careful document selection enables comparable model quality with only a fraction of the FLOPs. Inspired by efforts suggesting that domain-specific training document selection is in fact an interpretable process [Gunasekar et al., 2023], as well as research showing that instruction-finetuned LLMs are adept zero-shot data labelers [Gilardi et al.,2023], we explore a promising direction for scalable general-domain document selection; employing a prompted LLM as a document grader, we distill quality labels into a classifier model, which is applied at scale to a large, and already heavily-filtered, web-crawl-derived corpus autonomously. Following the guidance of this classifier, we drop 75% of the corpus and train LLMs on the remaining data. Results across multiple benchmarks show that: 1. Filtering allows us to quality-match a model trained on the full corpus across diverse benchmarks with at most 70% of the FLOPs, 2. More capable LLM labelers and classifier models lead to better results that are less sensitive to the labeler's prompt, 3. In-context learning helps to boost the performance of less-capable labeling models. In all cases we use open-source datasets, models, recipes, and evaluation frameworks, so that results can be reproduced by the community.
6/10/2024
Literature Filtering for Systematic Reviews with Transformers
John Hawkins, David Tivey
0
0
Identifying critical research within the growing body of academic work is an essential element of quality research. Systematic review processes, used in evidence-based medicine, formalise this as a procedure that must be followed in a research program. However, it comes with an increasing burden in terms of the time required to identify the important articles of research for a given topic. In this work, we develop a method for building a general-purpose filtering system that matches a research question, posed as a natural language description of the required content, against a candidate set of articles obtained via the application of broad search terms. Our results demonstrate that transformer models, pre-trained on biomedical literature then fine tuned for the specific task, offer a promising solution to this problem. The model can remove large volumes of irrelevant articles for most research questions.
6/3/2024