Literature Filtering for Systematic Reviews with Transformers
2405.20354
0
0
Abstract
Identifying critical research within the growing body of academic work is an essential element of quality research. Systematic review processes, used in evidence-based medicine, formalise this as a procedure that must be followed in a research program. However, it comes with an increasing burden in terms of the time required to identify the important articles of research for a given topic. In this work, we develop a method for building a general-purpose filtering system that matches a research question, posed as a natural language description of the required content, against a candidate set of articles obtained via the application of broad search terms. Our results demonstrate that transformer models, pre-trained on biomedical literature then fine tuned for the specific task, offer a promising solution to this problem. The model can remove large volumes of irrelevant articles for most research questions.
Create account to get full access
Overview
- This paper explores the use of transformer-based language models, such as BERT, for automating the literature screening process in systematic reviews.
- The authors investigate how these advanced natural language processing (NLP) techniques can be leveraged to improve the efficiency and accuracy of identifying relevant studies from large, unstructured document corpora.
- The research aims to address the challenges faced in manual literature screening, which can be time-consuming and subjective, by developing machine learning-powered tools to assist systematic review authors.
Plain English Explanation
The process of conducting a systematic review, which involves comprehensively searching the literature to answer a specific research question, can be a laborious and time-consuming task. Researchers often have to sift through hundreds or thousands of research articles to identify the ones that are relevant to their review. This manual screening process can be prone to human bias and errors.
To address this issue, the authors of this paper explored the use of advanced natural language processing (NLP) techniques, specifically transformer-based language models like BERT, to automate the literature screening process. These models are capable of understanding the semantic meaning and context of text, which can be leveraged to accurately identify relevant studies from large document corpora.
The key idea is to train the language model on a set of previously screened articles, allowing it to learn the patterns and characteristics of relevant and irrelevant studies. The trained model can then be used to classify new, unseen articles, helping researchers quickly identify the most promising studies to include in their systematic review.
By automating this process, the authors aim to improve the efficiency and accuracy of systematic reviews, reducing the time and effort required for manual screening while maintaining the quality and reliability of the results.
Technical Explanation
The authors of this paper investigated the use of transformer-based language models, specifically BERT (Bidirectional Encoder Representations from Transformers), for automating the literature screening process in systematic reviews. They proposed a framework that leverages transfer learning to fine-tune a pre-trained BERT model on a dataset of previously screened articles, allowing the model to learn the patterns and characteristics of relevant and irrelevant studies.
The researchers conducted experiments using two publicly available datasets of systematic reviews, evaluating the performance of the BERT-based model against traditional machine learning approaches, such as logistic regression and support vector machines. The results demonstrated that the BERT-based model outperformed the baseline methods in terms of classification accuracy, F1-score, and area under the receiver operating characteristic (ROC) curve.
The authors further explored the impact of different training strategies, including the use of class weighting and data augmentation techniques, to address the class imbalance often encountered in systematic review datasets. Additionally, they investigated the transferability of the BERT-based model by evaluating its performance on a cross-domain task, where the model was trained on one domain and tested on another.
The findings of this research suggest that transformer-based language models, such as BERT, can be effectively leveraged to automate the literature screening process in systematic reviews, potentially reducing the time and effort required for manual screening while maintaining the quality and reliability of the results.
Critical Analysis
The authors have made a compelling case for the use of transformer-based language models, specifically BERT, in automating the literature screening process for systematic reviews. The experimental results demonstrate the superior performance of the BERT-based model compared to traditional machine learning approaches, highlighting the potential of advanced NLP techniques in this domain.
However, the paper acknowledges several limitations and areas for further research. First, the authors note that the performance of the BERT-based model may be influenced by the quality and size of the training dataset, which can be a challenge in the context of systematic reviews where the number of previously screened articles may be limited. Exploring strategies to address this, such as cross-domain transfer learning or data augmentation, could be an important area for future work.
Additionally, the paper does not delve into the interpretability of the BERT-based model's decision-making process, which could be crucial in maintaining the trust and transparency of the automated screening process. Providing more insights into the model's decision-making, perhaps through the use of explainable AI techniques, could help researchers better understand the model's reasoning and ensure its reliability in the context of systematic reviews.
Furthermore, the paper focuses on the binary classification task of identifying relevant and irrelevant studies, but in practice, systematic review authors may need to categorize studies into more nuanced levels of relevance. Exploring the feasibility of extending the proposed framework to handle more granular classification tasks could be a valuable direction for future research.
Overall, the authors have made a significant contribution to the field of automated literature screening for systematic reviews, demonstrating the potential of transformer-based language models to enhance the efficiency and accuracy of this critical process. However, further research and development are needed to address the identified limitations and fully realize the benefits of this approach in practical applications.
Conclusion
This paper presents a compelling exploration of the use of transformer-based language models, specifically BERT, for automating the literature screening process in systematic reviews. The research demonstrates the superior performance of the BERT-based model compared to traditional machine learning approaches, highlighting the potential of advanced NLP techniques to streamline the time-consuming and subjective task of manual literature screening.
The findings of this study have important implications for the field of systematic reviews, where the ability to efficiently and accurately identify relevant studies is crucial. By leveraging the semantic understanding and contextual awareness of transformer-based models, researchers can potentially reduce the time and effort required for manual screening while maintaining the quality and reliability of the results.
While the paper acknowledges several limitations and areas for further research, such as the impact of training data quality and the need for interpretable decision-making, the overall contribution of this work is significant. As the field of systematic reviews continues to evolve, the integration of advanced NLP techniques, like those explored in this paper, can play a vital role in enhancing the efficiency and effectiveness of the literature screening process, ultimately leading to more robust and comprehensive systematic reviews.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Automated Text Mining of Experimental Methodologies from Biomedical Literature
Ziqing Guo
0
0
Biomedical literature is a rapidly expanding field of science and technology. Classification of biomedical texts is an essential part of biomedicine research, especially in the field of biology. This work proposes the fine-tuned DistilBERT, a methodology-specific, pre-trained generative classification language model for mining biomedicine texts. The model has proven its effectiveness in linguistic understanding capabilities and has reduced the size of BERT models by 40% but by 60% faster. The main objective of this project is to improve the model and assess the performance of the model compared to the non-fine-tuned model. We used DistilBert as a support model and pre-trained on a corpus of 32,000 abstracts and complete text articles; our results were impressive and surpassed those of traditional literature classification methods by using RNN or LSTM. Our aim is to integrate this highly specialised and specific model into different research industries.
4/23/2024
Automating Research Synthesis with Domain-Specific Large Language Model Fine-Tuning
Teo Susnjak, Peter Hwang, Napoleon H. Reyes, Andre L. C. Barczak, Timothy R. McIntosh, Surangika Ranathunga
0
0
This research pioneers the use of fine-tuned Large Language Models (LLMs) to automate Systematic Literature Reviews (SLRs), presenting a significant and novel contribution in integrating AI to enhance academic research methodologies. Our study employed the latest fine-tuning methodologies together with open-sourced LLMs, and demonstrated a practical and efficient approach to automating the final execution stages of an SLR process that involves knowledge synthesis. The results maintained high fidelity in factual accuracy in LLM responses, and were validated through the replication of an existing PRISMA-conforming SLR. Our research proposed solutions for mitigating LLM hallucination and proposed mechanisms for tracking LLM responses to their sources of information, thus demonstrating how this approach can meet the rigorous demands of scholarly research. The findings ultimately confirmed the potential of fine-tuned LLMs in streamlining various labor-intensive processes of conducting literature reviews. Given the potential of this approach and its applicability across all research domains, this foundational study also advocated for updating PRISMA reporting guidelines to incorporate AI-driven processes, ensuring methodological transparency and reliability in future SLRs. This study broadens the appeal of AI-enhanced tools across various academic and research fields, setting a new standard for conducting comprehensive and accurate literature reviews with more efficiency in the face of ever-increasing volumes of academic studies.
4/16/2024
🐍
SyROCCo: Enhancing Systematic Reviews using Machine Learning
Zheng Fang, Miguel Arana-Catania, Felix-Anselm van Lier, Juliana Outes Velarde, Harry Bregazzi, Mara Airoldi, Eleanor Carter, Rob Procter
0
0
The sheer number of research outputs published every year makes systematic reviewing increasingly time- and resource-intensive. This paper explores the use of machine learning techniques to help navigate the systematic review process. ML has previously been used to reliably 'screen' articles for review - that is, identify relevant articles based on reviewers' inclusion criteria. The application of ML techniques to subsequent stages of a review, however, such as data extraction and evidence mapping, is in its infancy. We therefore set out to develop a series of tools that would assist in the profiling and analysis of 1,952 publications on the theme of 'outcomes-based contracting'. Tools were developed for the following tasks: assign publications into 'policy area' categories; identify and extract key information for evidence mapping, such as organisations, laws, and geographical information; connect the evidence base to an existing dataset on the same topic; and identify subgroups of articles that may share thematic content. An interactive tool using these techniques and a public dataset with their outputs have been released. Our results demonstrate the utility of ML techniques to enhance evidence accessibility and analysis within the systematic review processes. These efforts show promise in potentially yielding substantial efficiencies for future systematic reviewing and for broadening their analytical scope. Our work suggests that there may be implications for the ease with which policymakers and practitioners can access evidence. While ML techniques seem poised to play a significant role in bridging the gap between research and policy by offering innovative ways of gathering, accessing, and analysing data from systematic reviews, we also highlight their current limitations and the need to exercise caution in their application, particularly given the potential for errors and biases.
6/26/2024
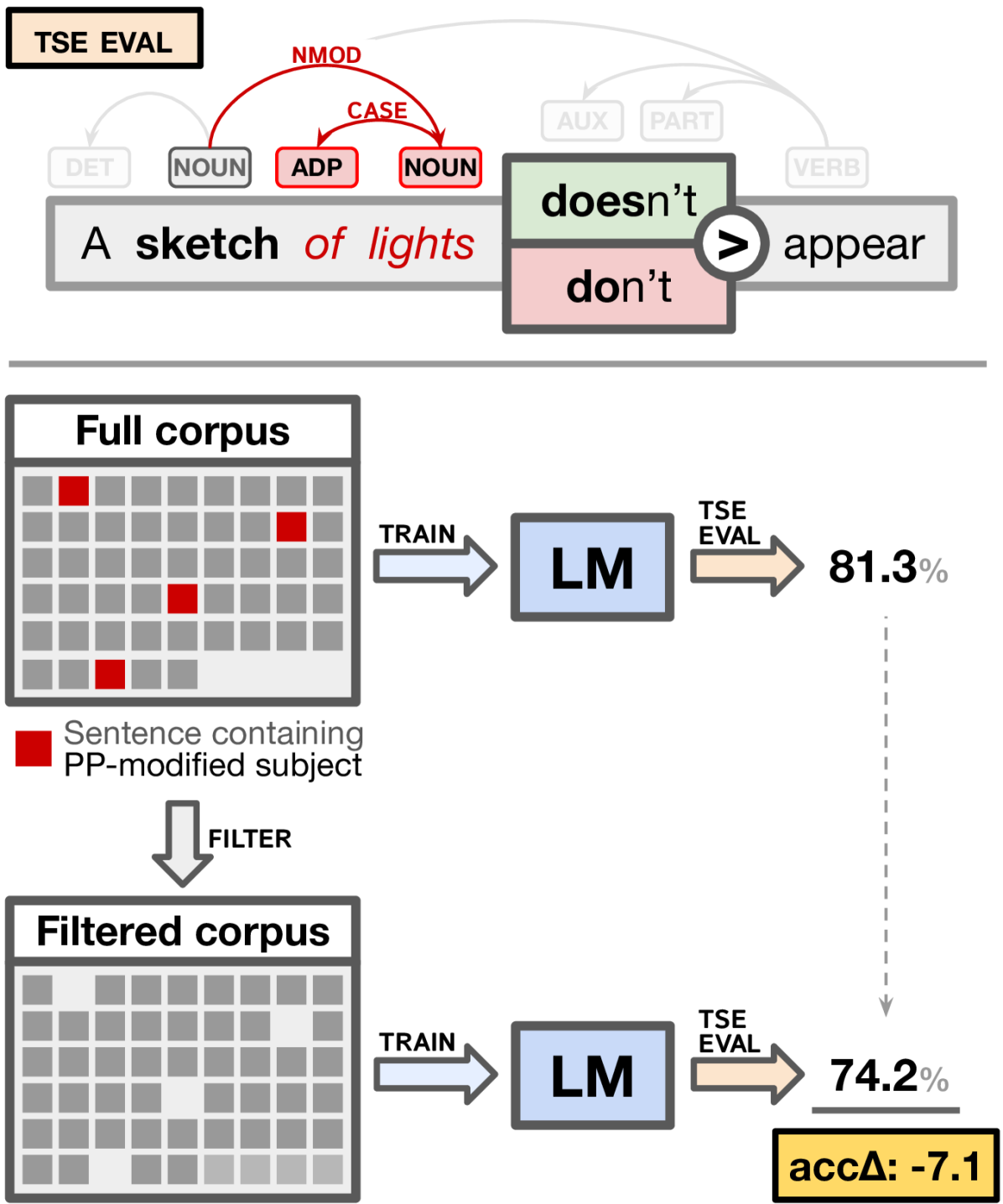
Filtered Corpus Training (FiCT) Shows that Language Models can Generalize from Indirect Evidence
Abhinav Patil, Jaap Jumelet, Yu Ying Chiu, Andy Lapastora, Peter Shen, Lexie Wang, Clevis Willrich, Shane Steinert-Threlkeld
0
0
This paper introduces Filtered Corpus Training, a method that trains language models (LMs) on corpora with certain linguistic constructions filtered out from the training data, and uses it to measure the ability of LMs to perform linguistic generalization on the basis of indirect evidence. We apply the method to both LSTM and Transformer LMs (of roughly comparable size), developing filtered corpora that target a wide range of linguistic phenomena. Our results show that while transformers are better qua LMs (as measured by perplexity), both models perform equally and surprisingly well on linguistic generalization measures, suggesting that they are capable of generalizing from indirect evidence.
5/27/2024