Fine-Tuning Medical Language Models for Enhanced Long-Contextual Understanding and Domain Expertise

0

Sign in to get full access
Overview
- This paper explores the potential of fine-tuning large language models to enhance their understanding and expertise in the medical domain.
- The researchers investigate techniques to improve the performance of language models on medical tasks that require long-contextual understanding and domain-specific knowledge.
- They aim to address limitations of existing medical language models and provide insights for effectively leveraging large language models for healthcare applications.
Plain English Explanation
Large language models, such as GPT-3, have shown impressive capabilities in a wide range of natural language processing tasks. However, their performance can be limited when applied to specialized domains like healthcare, where in-depth knowledge and understanding of medical concepts are required.
This paper explores ways to fine-tune these powerful language models to better handle medical tasks that involve long-form text and require specialized domain expertise. The researchers introduce techniques to adapt the language models to the unique characteristics of medical data, such as the use of technical terminology, the importance of context, and the need for accurate and reliable predictions.
By incorporating domain-specific training and leveraging insights from medical language model evaluations, the researchers aim to enhance the models' understanding of medical concepts and their ability to tackle complex healthcare-related tasks. This could lead to improved performance in areas such as clinical decision support, patient care, and medical research.
Technical Explanation
The paper presents a novel approach for fine-tuning large language models to enhance their long-contextual understanding and domain expertise in the medical field. The researchers first conduct a comprehensive review of the existing literature on the use of large language models in healthcare and medical applications. They identify key challenges and limitations of current medical language models, such as their inability to effectively handle long-form text and their lack of specialized medical knowledge.
To address these issues, the researchers propose a multi-stage fine-tuning process. First, they pre-train the language model on a large corpus of general text to establish a strong foundation of language understanding. They then fine-tune the model on a curated dataset of medical literature, including clinical notes, research papers, and other domain-specific sources. This fine-tuning step aims to imbue the model with the necessary medical knowledge and terminology.
Finally, the researchers further fine-tune the model on tasks that require long-contextual understanding, such as medical question answering and clinical decision support. This additional fine-tuning step helps the model develop the ability to maintain coherence and make informed decisions based on the broader context of a given medical scenario.
The paper presents extensive experiments and evaluations to validate the effectiveness of their approach. The results demonstrate significant improvements in the model's performance on a range of medical tasks, particularly in areas where long-form text and domain expertise are critical.
Critical Analysis
The researchers have made a compelling case for the importance of fine-tuning large language models to enhance their capabilities in the medical domain. The proposed multi-stage fine-tuning approach, with its focus on domain-specific training and long-contextual understanding, addresses important limitations of existing medical language models.
One potential limitation of the study is the reliance on curated datasets for fine-tuning. While the researchers have made efforts to ensure the representativeness and quality of the data, there may be inherent biases or gaps in the available medical literature that could impact the model's performance in real-world scenarios. Further research could explore techniques to mitigate these biases, such as incorporating diverse data sources or leveraging synthetic data generation.
Additionally, the study does not delve deeply into the interpretability and explainability of the fine-tuned models. As these models are deployed in sensitive healthcare settings, it is crucial to understand the reasoning behind their predictions and decisions. Future work could explore methods to enhance the interpretability of the models, enabling healthcare professionals to better understand and trust the model's outputs.
Overall, this paper provides valuable insights into the effective leveraging of large language models for medical applications. The proposed fine-tuning approach offers a promising direction for researchers and practitioners seeking to harness the power of these models to improve healthcare outcomes and patient care.
Conclusion
This paper presents a compelling approach for fine-tuning large language models to enhance their understanding and expertise in the medical domain. By incorporating domain-specific training and focusing on long-contextual understanding, the researchers have demonstrated significant improvements in the models' performance on a range of medical tasks.
The findings of this study have the potential to pave the way for more effective use of large language models in healthcare applications, such as clinical decision support, patient care, and medical research. As these models continue to advance, the ability to fine-tune them for specialized domains like medicine will become increasingly important in unlocking their full potential for societal benefit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fine-Tuning Medical Language Models for Enhanced Long-Contextual Understanding and Domain Expertise
Qimin Yang, Rongsheng Wang, Jiexin Chen, Runqi Su, Tao Tan
Large Language Models (LLMs) have been widely applied in various professional fields. By fine-tuning the models using domain specific question and answer datasets, the professional domain knowledge and Q&A abilities of these models have significantly improved, for example, medical professional LLMs that use fine-tuning of doctor-patient Q&A data exhibit extraordinary disease diagnostic abilities. However, we observed that despite improvements in specific domain knowledge, the performance of medical LLM in long-context understanding has significantly declined, especially compared to general language models with similar parameters. The purpose of this study is to investigate the phenomenon of reduced performance in understanding long-context in medical LLM. We designed a series of experiments to conduct open-book professional knowledge exams on all models to evaluate their ability to read long-context. By adjusting the proportion and quantity of general data and medical data in the process of fine-tuning, we can determine the best data composition to optimize the professional model and achieve a balance between long-context performance and specific domain knowledge.
Read more7/17/2024
0
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
Felix J. Dorfner, Amin Dada, Felix Busch, Marcus R. Makowski, Tianyu Han, Daniel Truhn, Jens Kleesiek, Madhumita Sushil, Jacqueline Lammert, Lisa C. Adams, Keno K. Bressem
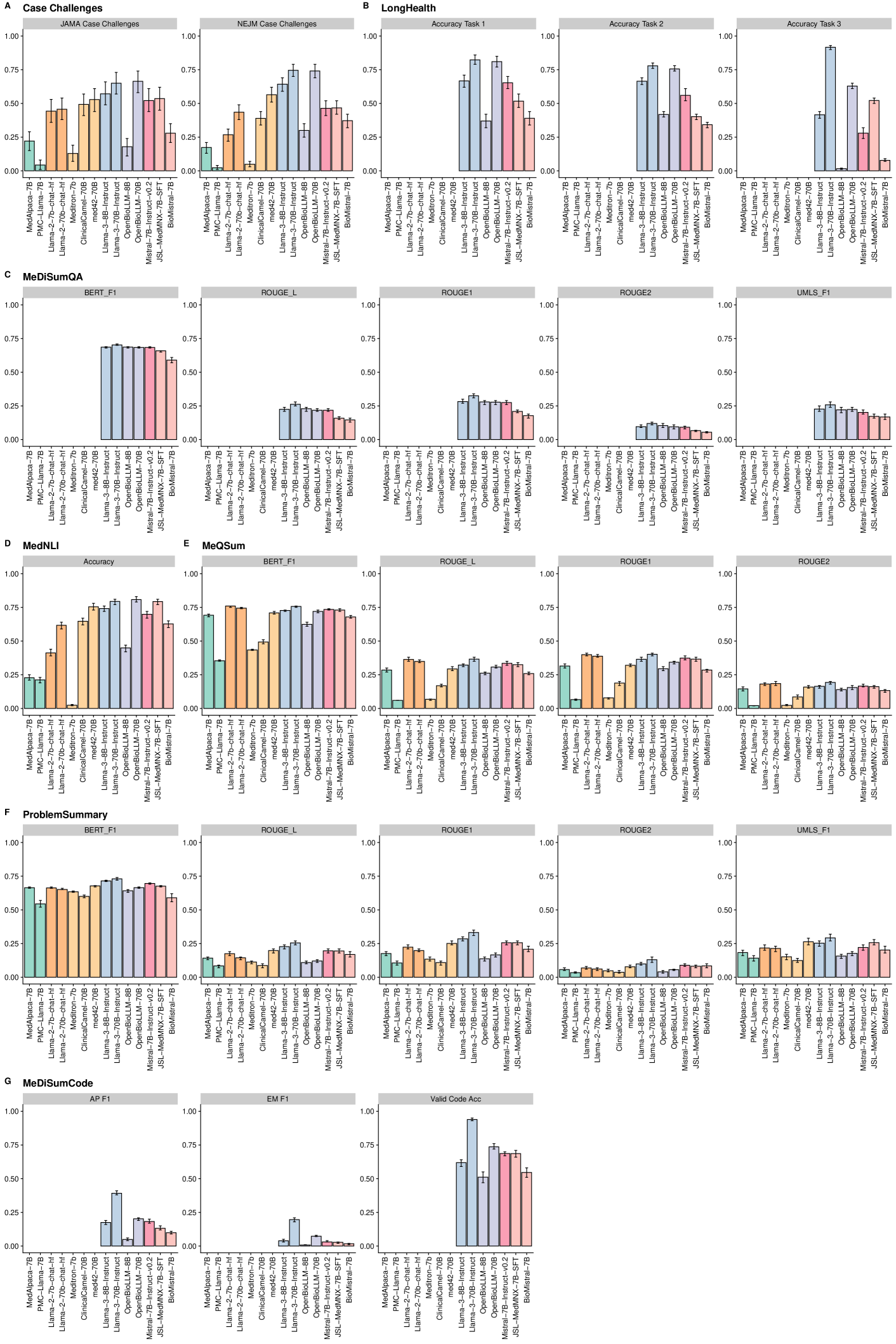
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
Read more8/27/2024

0
A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
Read more6/18/2024
💬
0
Instruction-tuned Large Language Models for Machine Translation in the Medical Domain
Miguel Rios
Large Language Models (LLMs) have shown promising results on machine translation for high resource language pairs and domains. However, in specialised domains (e.g. medical) LLMs have shown lower performance compared to standard neural machine translation models. The consistency in the machine translation of terminology is crucial for users, researchers, and translators in specialised domains. In this study, we compare the performance between baseline LLMs and instruction-tuned LLMs in the medical domain. In addition, we introduce terminology from specialised medical dictionaries into the instruction formatted datasets for fine-tuning LLMs. The instruction-tuned LLMs significantly outperform the baseline models with automatic metrics.
Read more8/30/2024