FinLangNet: A Novel Deep Learning Framework for Credit Risk Prediction Using Linguistic Analogy in Financial Data
2404.13004
0
0

Abstract
Recent industrial applications in risk prediction still heavily rely on extensively manually-tuned, statistical learning methods. Real-world financial data, characterized by its high-dimensionality, sparsity, high noise levels, and significant imbalance, poses unique challenges for the effective application of deep neural network models. In this work, we introduce a novel deep learning risk prediction framework, FinLangNet, which conceptualizes credit loan trajectories in a structure that mirrors linguistic constructs. This framework is tailored for credit risk prediction using real-world financial data, drawing on structural similarities to language by adapting natural language processing techniques. It focuses on analyzing the evolution and predictability of credit histories through detailed financial event sequences. Our research demonstrates that FinLangNet surpasses traditional statistical methods in predicting credit risk and that its integration with these methods enhances credit card fraud prediction models, achieving a significant improvement of over 1.5 points in the Kolmogorov-Smirnov metric.
Create account to get full access
Overview
- Proposes a novel deep learning framework called FinLangNet for credit risk prediction using linguistic analogy in financial data
- Aims to leverage the relationship between natural language and financial data to improve credit risk forecasting
- Introduces a hierarchical architecture that combines natural language processing and financial time series modeling
Plain English Explanation
FinLangNet: A Novel Deep Learning Framework for Credit Risk Prediction Using Linguistic Analogy in Financial Data is a research paper that presents a new deep learning approach for forecasting credit risk. The key idea is to use the relationship between natural language and financial data to make more accurate predictions about the risk of loan defaults or other financial events.
The researchers hypothesize that the way people communicate about financial topics, such as in news articles or earnings reports, contains valuable information that can be used to supplement traditional financial modeling techniques. By training a neural network to understand these linguistic patterns and how they relate to loan trajectories, the FinLangNet framework aims to generate more reliable credit risk predictions.
The paper introduces a hierarchical architecture that combines natural language processing and financial time series modeling. This allows the model to simultaneously analyze textual data and numerical data, capturing the interplay between language and financial outcomes. The researchers use this approach to forecast the credit risk of borrowers, which is an important problem in banking and lending.
Technical Explanation
FinLangNet: A Novel Deep Learning Framework for Credit Risk Prediction Using Linguistic Analogy in Financial Data presents a novel deep learning framework that leverages linguistic constructs to improve credit risk prediction. The key innovation is the incorporation of natural language processing (NLP) techniques within a deep learning architecture to capture the relationship between textual data and financial time series.
The proposed FinLangNet framework has a hierarchical structure that consists of two main components: a language model and a financial time series model. The language model uses transformer-based architectures, such as BERT, to extract semantic and syntactic features from financial text data, such as news articles and earnings reports. These linguistic features are then fed into the financial time series model, which uses recurrent neural networks to learn the temporal dynamics of loan trajectories and credit risk.
The researchers hypothesize that the linguistic patterns found in financial discourse can provide valuable insights to complement traditional numerical data sources, leading to more accurate credit risk predictions. They evaluate the performance of FinLangNet on several real-world credit risk datasets and compare it to various baseline models, including those that use only numerical data or traditional statistical methods.
Critical Analysis
FinLangNet: A Novel Deep Learning Framework for Credit Risk Prediction Using Linguistic Analogy in Financial Data presents a promising approach for leveraging linguistic information to improve credit risk forecasting. The integration of natural language processing and financial time series modeling is a novel concept that has the potential to capture more nuanced relationships between textual and numerical data sources.
However, the paper also acknowledges several limitations and areas for further research. For example, the performance of the FinLangNet framework may be sensitive to the quality and quantity of the textual data used for training, as well as the specific financial domain and risk prediction task. Additionally, the paper does not explore the interpretability of the FinLangNet model, which is an important consideration for many real-world financial applications where transparency and explainability are crucial.
Future research could investigate ways to improve the robustness and generalizability of the FinLangNet approach, such as by exploring alternative neural network architectures or incorporating domain-specific linguistic knowledge. Additionally, comparisons to other state-of-the-art credit risk modeling techniques, including those that leverage large language models or other advanced data mining methods, would provide a more comprehensive evaluation of the FinLangNet framework's performance and potential advantages.
Conclusion
The FinLangNet framework presented in this paper represents a novel and promising approach for leveraging linguistic constructs to improve credit risk prediction. By combining natural language processing and financial time series modeling, the framework aims to capture the interplay between textual and numerical data sources, leading to more accurate forecasts of loan trajectories and credit risk.
While the paper acknowledges several limitations and areas for further research, the core idea of using linguistic analogies to enhance financial risk modeling is compelling and could have significant implications for the banking and lending industries, as well as other domains where accurate forecasting of financial events is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
RiskLabs: Predicting Financial Risk Using Large Language Model Based on Multi-Sources Data
Yupeng Cao, Zhi Chen, Qingyun Pei, Fabrizio Dimino, Lorenzo Ausiello, Prashant Kumar, K. P. Subbalakshmi, Papa Momar Ndiaye
0
0
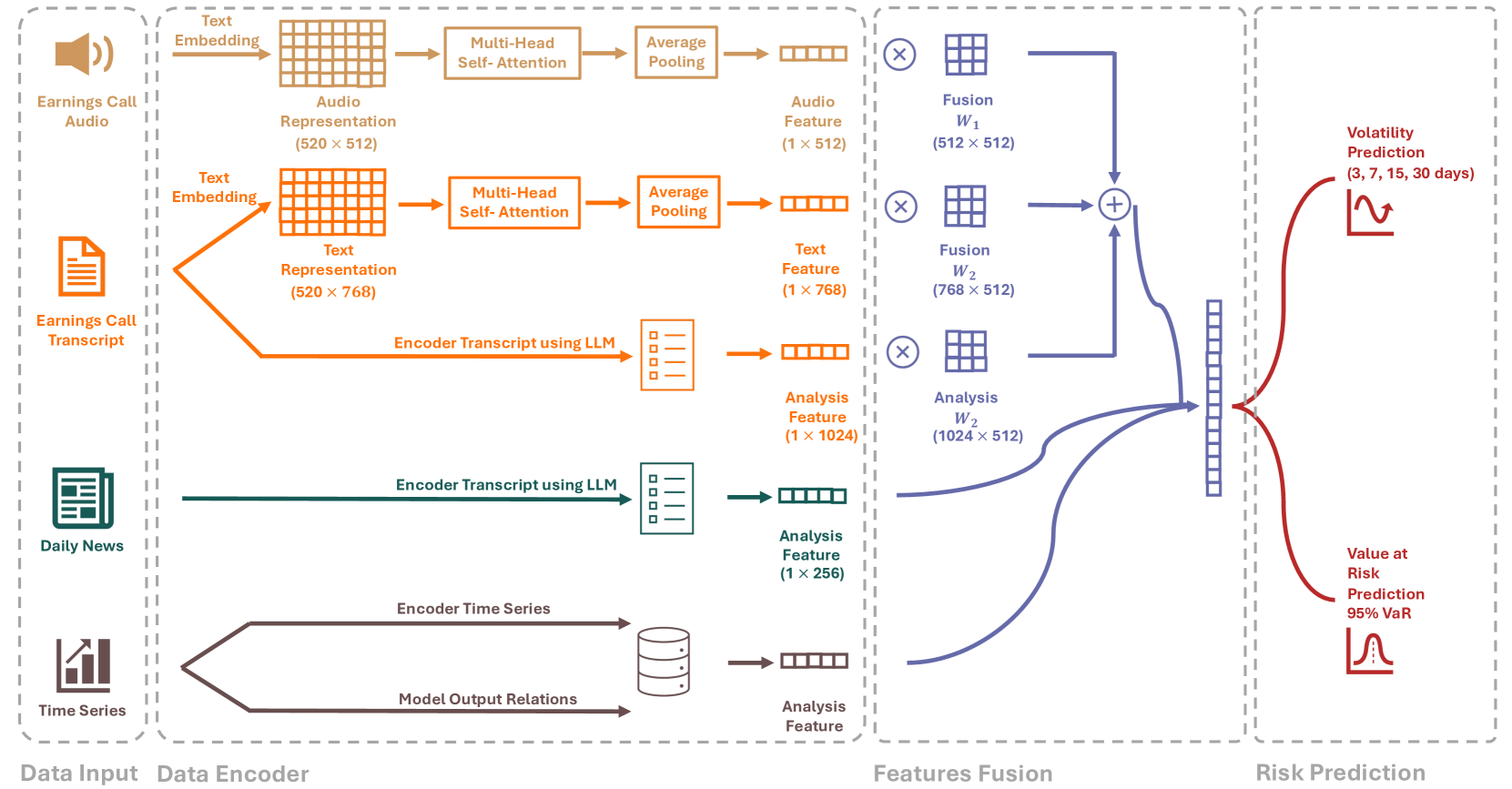
The integration of Artificial Intelligence (AI) techniques, particularly large language models (LLMs), in finance has garnered increasing academic attention. Despite progress, existing studies predominantly focus on tasks like financial text summarization, question-answering (Q$&$A), and stock movement prediction (binary classification), with a notable gap in the application of LLMs for financial risk prediction. Addressing this gap, in this paper, we introduce textbf{RiskLabs}, a novel framework that leverages LLMs to analyze and predict financial risks. RiskLabs uniquely combines different types of financial data, including textual and vocal information from Earnings Conference Calls (ECCs), market-related time series data, and contextual news data surrounding ECC release dates. Our approach involves a multi-stage process: initially extracting and analyzing ECC data using LLMs, followed by gathering and processing time-series data before the ECC dates to model and understand risk over different timeframes. Using multimodal fusion techniques, RiskLabs amalgamates these varied data features for comprehensive multi-task financial risk prediction. Empirical experiment results demonstrate RiskLab's effectiveness in forecasting both volatility and variance in financial markets. Through comparative experiments, we demonstrate how different data sources contribute to financial risk assessment and discuss the critical role of LLMs in this context. Our findings not only contribute to the AI in finance application but also open new avenues for applying LLMs in financial risk assessment.
4/12/2024
A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges
Yuqi Nie, Yaxuan Kong, Xiaowen Dong, John M. Mulvey, H. Vincent Poor, Qingsong Wen, Stefan Zohren
0
0
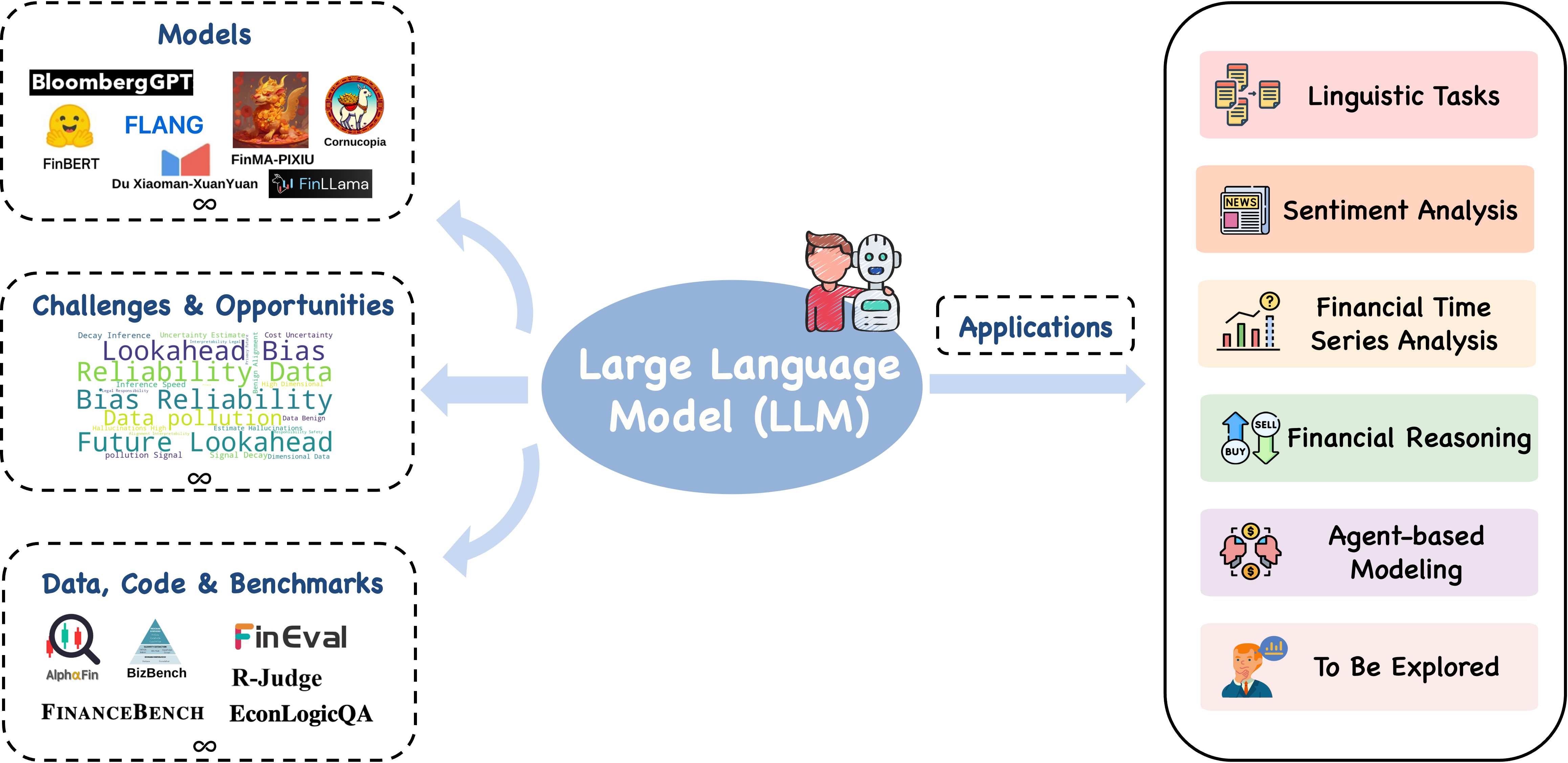
Recent advances in large language models (LLMs) have unlocked novel opportunities for machine learning applications in the financial domain. These models have demonstrated remarkable capabilities in understanding context, processing vast amounts of data, and generating human-preferred contents. In this survey, we explore the application of LLMs on various financial tasks, focusing on their potential to transform traditional practices and drive innovation. We provide a discussion of the progress and advantages of LLMs in financial contexts, analyzing their advanced technologies as well as prospective capabilities in contextual understanding, transfer learning flexibility, complex emotion detection, etc. We then highlight this survey for categorizing the existing literature into key application areas, including linguistic tasks, sentiment analysis, financial time series, financial reasoning, agent-based modeling, and other applications. For each application area, we delve into specific methodologies, such as textual analysis, knowledge-based analysis, forecasting, data augmentation, planning, decision support, and simulations. Furthermore, a comprehensive collection of datasets, model assets, and useful codes associated with mainstream applications are presented as resources for the researchers and practitioners. Finally, we outline the challenges and opportunities for future research, particularly emphasizing a number of distinctive aspects in this field. We hope our work can help facilitate the adoption and further development of LLMs in the financial sector.
6/19/2024
🌿
Application of Natural Language Processing in Financial Risk Detection
Liyang Wang, Yu Cheng, Ao Xiang, Jingyu Zhang, Haowei Yang
0
0
This paper explores the application of Natural Language Processing (NLP) in financial risk detection. By constructing an NLP-based financial risk detection model, this study aims to identify and predict potential risks in financial documents and communications. First, the fundamental concepts of NLP and its theoretical foundation, including text mining methods, NLP model design principles, and machine learning algorithms, are introduced. Second, the process of text data preprocessing and feature extraction is described. Finally, the effectiveness and predictive performance of the model are validated through empirical research. The results show that the NLP-based financial risk detection model performs excellently in risk identification and prediction, providing effective risk management tools for financial institutions. This study offers valuable references for the field of financial risk management, utilizing advanced NLP techniques to improve the accuracy and efficiency of financial risk detection.
6/21/2024
🔎
Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no, Enrique Costa-Montenegro
0
0
Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (NLP) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (LDA) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. We created an experimental data set composed of 2,158 financial news items that were manually labelled by NLP researchers to evaluate our solution. The ROUGE-L values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with LDA to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text.
4/3/2024