Fitness Approximation through Machine Learning
2309.03318
0
0
🛸
Abstract
We present a novel approach to performing fitness approximation in genetic algorithms (GAs) using machine-learning (ML) models, through dynamic adaptation to the evolutionary state. Maintaining a dataset of sampled individuals along with their actual fitness scores, we continually update a fitness-approximation ML model throughout an evolutionary run. We compare different methods for: 1) switching between actual and approximate fitness, 2) sampling the population, and 3) weighting the samples. Experimental findings demonstrate significant improvement in evolutionary runtimes, with fitness scores that are either identical or slightly lower than that of the fully run GA -- depending on the ratio of approximate-to-actual-fitness computation. Although we focus on evolutionary agents in Gymnasium (game) simulators -- where fitness computation is costly -- our approach is generic and can be easily applied to many different domains.
Create account to get full access
Overview
- The paper proposes a novel approach to improve the efficiency of genetic algorithms (GAs) by incorporating machine learning (ML) models to approximate fitness functions.
- The key idea is to maintain a dataset of sampled individuals and their actual fitness scores, and continuously update an ML-based fitness approximation model during the evolutionary process.
- The paper explores different methods for switching between actual and approximate fitness, sampling the population, and weighting the samples.
- The focus is on evolutionary agents in Gymnasium (game) simulators, where fitness computation is costly, but the approach is generic and can be applied to various domains.
Plain English Explanation
The researchers have developed a new way to make genetic algorithms (GAs) run more efficiently. GAs are a type of optimization technique that mimics the process of natural selection to find the best solution to a problem. However, evaluating the "fitness" of each potential solution can be computationally expensive, especially in certain applications like video game simulations.
To address this, the researchers propose using machine learning models to approximate the fitness of solutions, rather than always calculating it from scratch. They maintain a dataset of previous solutions and their actual fitness scores, and continuously update the machine learning model to make better approximations over time.
The paper explores different strategies for deciding when to use the approximate fitness versus the actual fitness, how to sample the population to update the model, and how to weight the importance of different samples. The key finding is that this approach can significantly reduce the runtime of genetic algorithms, while still achieving very similar final results to a traditional GA.
Although the researchers focus on applications in video game simulations, where fitness calculations are particularly costly, they believe this technique could be broadly applied to many other domains that use genetic algorithms.
Technical Explanation
The paper presents a framework for dynamically adapting the fitness approximation in genetic algorithms using machine learning models. The researchers maintain a dataset of sampled individuals and their actual fitness scores, and continuously update a fitness approximation model throughout the evolutionary run.
Three key aspects are investigated:
-
Switching between actual and approximate fitness: The paper explores different strategies for deciding when to use the approximate fitness versus the actual fitness, such as using approximate fitness early in the run and switching to actual fitness later.
-
Sampling the population: The researchers experiment with different methods for selecting which individuals to sample and add to the training dataset, such as sampling the entire population or only the top-performing individuals.
-
Weighting the samples: The paper also looks at weighting the importance of different samples in the training dataset, for example, giving more weight to higher-performing individuals.
Experiments were conducted using evolutionary agents in Gymnasium (game) simulators, where fitness computation is costly. The results show significant improvements in evolutionary runtime compared to a traditional GA, with final fitness scores that are either identical or slightly lower depending on the ratio of approximate-to-actual-fitness computation.
The proposed approach is designed to be generic and applicable to a wide range of domains that use genetic algorithms, not just the game simulation use case.
Critical Analysis
The paper provides a thorough and well-designed study on improving the efficiency of genetic algorithms through the use of machine learning-based fitness approximation. The researchers have thoughtfully considered various aspects of the problem, such as the trade-offs between using approximate versus actual fitness, sampling strategies, and sample weighting.
One potential limitation is that the experiments were conducted solely in the context of game simulations, which may limit the generalizability of the findings. While the authors claim the approach is generic, it would be valuable to see it applied and evaluated in other domains that use genetic algorithms, such as feature selection, multi-objective optimization, or complex system simulations.
Additionally, the paper does not address the potential for the machine learning model to introduce additional bias or errors into the fitness approximation, which could negatively impact the overall performance of the genetic algorithm. The authors could have explored this issue in more depth, perhaps by comparing the performance of different machine learning models or investigating the stability and reliability of the fitness approximations over time.
Overall, the research presents a promising approach to improving the efficiency of genetic algorithms, and the findings could have significant implications for the broader field of evolutionary computing. However, further investigation and validation across a wider range of applications would help strengthen the generalizability and robustness of the proposed techniques.
Conclusion
This paper introduces a novel framework for dynamically adapting the fitness approximation in genetic algorithms using machine learning models. By maintaining a dataset of sampled individuals and their actual fitness scores, and continually updating an ML-based fitness approximation model, the researchers were able to achieve significant improvements in evolutionary runtime compared to a traditional GA, with only a slight reduction in final fitness scores.
The key contributions of this work include the exploration of different strategies for switching between actual and approximate fitness, sampling the population, and weighting the samples. While the focus was on evolutionary agents in game simulations, the authors believe the approach is generic and can be applied to a wide range of domains that use genetic algorithms.
This research represents an important step forward in enhancing the efficiency and practicality of genetic algorithms, which have numerous applications in optimization, design, and decision-making problems. The insights and techniques presented in this paper could pave the way for more widespread adoption and deployment of genetic algorithms in real-world scenarios where computational resources are limited.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
Fast Genetic Algorithm for feature selection -- A qualitative approximation approach
Mohammed Ghaith Altarabichi, S{l}awomir Nowaczyk, Sepideh Pashami, Peyman Sheikholharam Mashhadi
0
0
Evolutionary Algorithms (EAs) are often challenging to apply in real-world settings since evolutionary computations involve a large number of evaluations of a typically expensive fitness function. For example, an evaluation could involve training a new machine learning model. An approximation (also known as meta-model or a surrogate) of the true function can be used in such applications to alleviate the computation cost. In this paper, we propose a two-stage surrogate-assisted evolutionary approach to address the computational issues arising from using Genetic Algorithm (GA) for feature selection in a wrapper setting for large datasets. We define 'Approximation Usefulness' to capture the necessary conditions to ensure correctness of the EA computations when an approximation is used. Based on this definition, we propose a procedure to construct a lightweight qualitative meta-model by the active selection of data instances. We then use a meta-model to carry out the feature selection task. We apply this procedure to the GA-based algorithm CHC (Cross generational elitist selection, Heterogeneous recombination and Cataclysmic mutation) to create a Qualitative approXimations variant, CHCQX. We show that CHCQX converges faster to feature subset solutions of significantly higher accuracy (as compared to CHC), particularly for large datasets with over 100K instances. We also demonstrate the applicability of the thinking behind our approach more broadly to Swarm Intelligence (SI), another branch of the Evolutionary Computation (EC) paradigm with results of PSOQX, a qualitative approximation adaptation of the Particle Swarm Optimization (PSO) method. A GitHub repository with the complete implementation is available.
4/8/2024

NeuroLGP-SM: Scalable Surrogate-Assisted Neuroevolution for Deep Neural Networks
Fergal Stapleton, Edgar Galv'an
0
0
Evolutionary Algorithms (EAs) play a crucial role in the architectural configuration and training of Artificial Deep Neural Networks (DNNs), a process known as neuroevolution. However, neuroevolution is hindered by its inherent computational expense, requiring multiple generations, a large population, and numerous epochs. The most computationally intensive aspect lies in evaluating the fitness function of a single candidate solution. To address this challenge, we employ Surrogate-assisted EAs (SAEAs). While a few SAEAs approaches have been proposed in neuroevolution, none have been applied to truly large DNNs due to issues like intractable information usage. In this work, drawing inspiration from Genetic Programming semantics, we use phenotypic distance vectors, outputted from DNNs, alongside Kriging Partial Least Squares (KPLS), an approach that is effective in handling these large vectors, making them suitable for search. Our proposed approach, named Neuro-Linear Genetic Programming surrogate model (NeuroLGP-SM), efficiently and accurately estimates DNN fitness without the need for complete evaluations. NeuroLGP-SM demonstrates competitive or superior results compared to 12 other methods, including NeuroLGP without SM, convolutional neural networks, support vector machines, and autoencoders. Additionally, it is worth noting that NeuroLGP-SM is 25% more energy-efficient than its NeuroLGP counterpart. This efficiency advantage adds to the overall appeal of our proposed NeuroLGP-SM in optimising the configuration of large DNNs.
5/3/2024
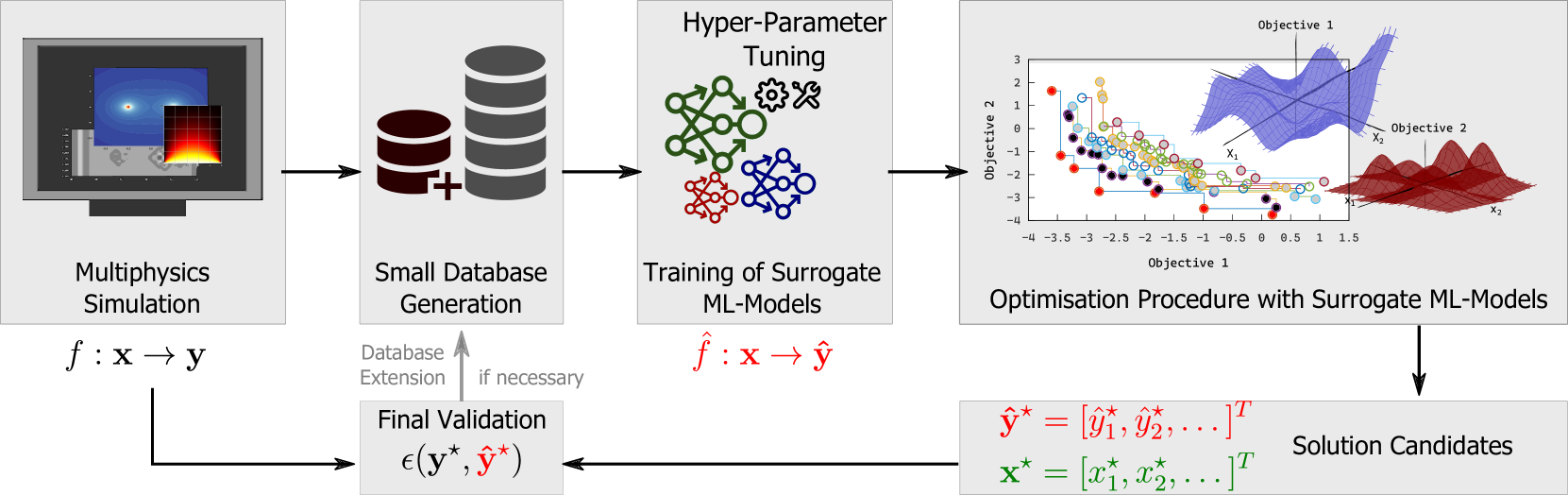
Enhancing Multi-Objective Optimization through Machine Learning-Supported Multiphysics Simulation
Diego Botache, Jens Decke, Winfried Ripken, Abhinay Dornipati, Franz Gotz-Hahn, Mohamed Ayeb, Bernhard Sick
0
0
This paper presents a methodological framework for training, self-optimising, and self-organising surrogate models to approximate and speed up multiobjective optimisation of technical systems based on multiphysics simulations. At the hand of two real-world datasets, we illustrate that surrogate models can be trained on relatively small amounts of data to approximate the underlying simulations accurately. Including explainable AI techniques allow for highlighting feature relevancy or dependencies and supporting the possible extension of the used datasets. One of the datasets was created for this paper and is made publicly available for the broader scientific community. Extensive experiments combine four machine learning and deep learning algorithms with an evolutionary optimisation algorithm. The performance of the combined training and optimisation pipeline is evaluated by verifying the generated Pareto-optimal results using the ground truth simulations. The results from our pipeline and a comprehensive evaluation strategy show the potential for efficiently acquiring solution candidates in multiobjective optimisation tasks by reducing the number of simulations and conserving a higher prediction accuracy, i.e., with a MAPE score under 5% for one of the presented use cases.
4/4/2024
🛠️
Robust Model-Based Optimization for Challenging Fitness Landscapes
Saba Ghaffari, Ehsan Saleh, Alexander G. Schwing, Yu-Xiong Wang, Martin D. Burke, Saurabh Sinha
0
0
Protein design, a grand challenge of the day, involves optimization on a fitness landscape, and leading methods adopt a model-based approach where a model is trained on a training set (protein sequences and fitness) and proposes candidates to explore next. These methods are challenged by sparsity of high-fitness samples in the training set, a problem that has been in the literature. A less recognized but equally important problem stems from the distribution of training samples in the design space: leading methods are not designed for scenarios where the desired optimum is in a region that is not only poorly represented in training data, but also relatively far from the highly represented low-fitness regions. We show that this problem of separation in the design space is a significant bottleneck in existing model-based optimization tools and propose a new approach that uses a novel VAE as its search model to overcome the problem. We demonstrate its advantage over prior methods in robustly finding improved samples, regardless of the imbalance and separation between low- and high-fitness samples. Our comprehensive benchmark on real and semi-synthetic protein datasets as well as solution design for physics-informed neural networks, showcases the generality of our approach in discrete and continuous design spaces. Our implementation is available at https://github.com/sabagh1994/PGVAE.
7/1/2024