Flexible, Model-Agnostic Method for Materials Data Extraction from Text Using General Purpose Language Models
2302.04914
0
0
📊
Abstract
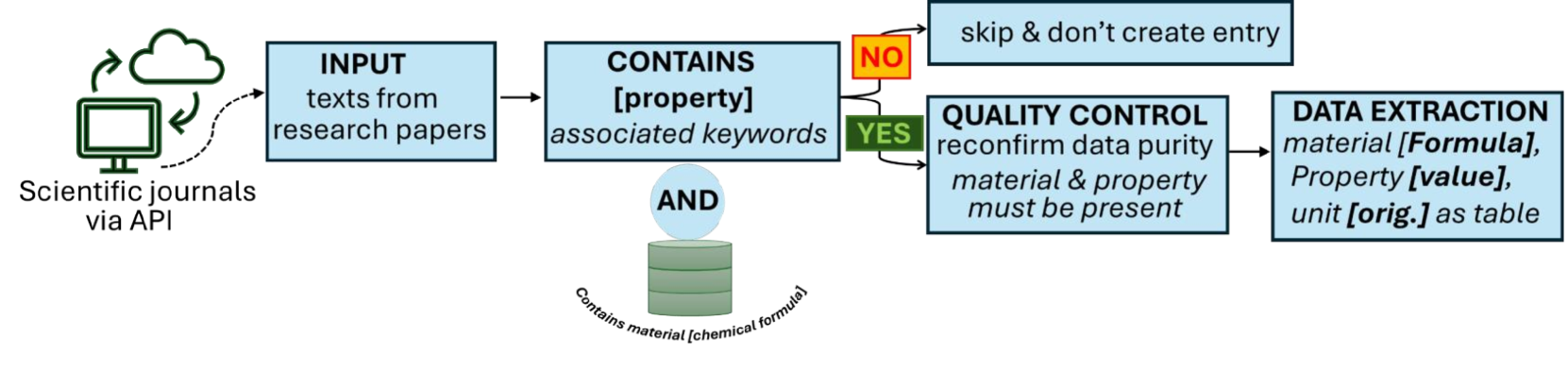
Accurate and comprehensive material databases extracted from research papers are crucial for materials science and engineering, but their development requires significant human effort. With large language models (LLMs) transforming the way humans interact with text, LLMs provide an opportunity to revolutionize data extraction. In this study, we demonstrate a simple and efficient method for extracting materials data from full-text research papers leveraging the capabilities of LLMs combined with human supervision. This approach is particularly suitable for mid-sized databases and requires minimal to no coding or prior knowledge about the extracted property. It offers high recall and nearly perfect precision in the resulting database. The method is easily adaptable to new and superior language models, ensuring continued utility. We show this by evaluating and comparing its performance on GPT-3 and GPT-3.5/4 (which underlie ChatGPT), as well as free alternatives such as BART and DeBERTaV3. We provide a detailed analysis of the method's performance in extracting sentences containing bulk modulus data, achieving up to 90% precision at 96% recall, depending on the amount of human effort involved. We further demonstrate the method's broader effectiveness by developing a database of critical cooling rates for metallic glasses over twice the size of previous human curated databases.
Create account to get full access
Overview
- This paper presents a simple and efficient method for extracting materials data from research papers using large language models (LLMs) combined with human supervision.
- The method is particularly suitable for mid-sized databases and requires minimal to no coding or prior knowledge about the extracted property.
- The approach offers high recall and nearly perfect precision in the resulting database, and is easily adaptable to new and superior language models.
- The authors demonstrate the method's performance by extracting sentences containing bulk modulus data and developing a database of critical cooling rates for metallic glasses.
Plain English Explanation
Building comprehensive materials databases is crucial for materials science and engineering, but it requires significant human effort. However, the rise of large language models (LLMs) provides an opportunity to revolutionize this process.
The researchers in this study show a straightforward and efficient way to extract materials data from research papers using LLMs and a small amount of human oversight. This approach works well for mid-sized databases and doesn't require specialized coding skills or prior knowledge about the property being extracted.
The method is able to retrieve relevant information with high accuracy, capturing up to 96% of the relevant sentences while making very few mistakes (up to 90% precision). Importantly, the technique can be easily adapted to take advantage of newer and more capable language models as they become available, ensuring its continued usefulness.
To demonstrate the method, the researchers used it to extract data on bulk modulus and critical cooling rates for metallic glasses, building significantly larger databases than previous human-curated efforts.
Technical Explanation
The authors present a simple and efficient method for extracting materials data from full-text research papers using the capabilities of large language models (LLMs) combined with human supervision.
The process involves:
- Identifying relevant research papers
- Prompting an LLM (such as GPT-3 or GPT-3.5/4) to extract sentences containing the desired material property
- Reviewing the extracted sentences for accuracy and completeness
This approach is particularly well-suited for mid-sized databases, as it requires minimal to no coding or prior knowledge about the target property. The authors demonstrate the method's performance by extracting sentences containing bulk modulus data, achieving up to 90% precision at 96% recall, depending on the amount of human effort involved.
The researchers further showcase the broader effectiveness of the technique by developing a database of critical cooling rates for metallic glasses, more than doubling the size of previous human-curated efforts. Importantly, the method is easily adaptable to new and superior language models as they become available, ensuring its continued utility.
Critical Analysis
The authors present a compelling approach to streamlining the process of building materials databases from research literature, leveraging the power of large language models while maintaining human oversight for quality control.
One potential limitation of the study is the focus on mid-sized databases. It would be interesting to see how the method scales for larger-scale data extraction efforts, where the trade-off between human effort and model performance may become more critical.
Additionally, the paper does not delve deeply into the specific challenges or failure modes encountered during the data extraction process. A more detailed analysis of the types of errors made by the language models and the strategies employed to mitigate them could provide valuable insights for future researchers in this area.
That said, the authors' emphasis on adaptability to new language models is a key strength, as it ensures the longevity and continued relevance of the proposed approach. As large language models continue to evolve, this method can be readily updated to take advantage of the latest advancements.
Overall, this study offers a promising step towards more efficient and scalable materials data extraction, with the potential to significantly accelerate progress in materials science and engineering.
Conclusion
This paper presents a simple and effective method for extracting materials data from research literature using large language models and human supervision. The approach is particularly well-suited for mid-sized databases, offering high recall and precision while requiring minimal coding or prior domain knowledge.
By demonstrating the method's ability to build larger databases of key materials properties, such as bulk modulus and critical cooling rates for metallic glasses, the researchers highlight its potential to revolutionize the way materials science data is curated and maintained. Importantly, the method's adaptability to new language models ensures its continued usefulness as the field of natural language processing continues to advance.
This work represents an important step towards streamlining the data extraction process in materials science, paving the way for more comprehensive and up-to-date materials databases to support critical research and engineering efforts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Mining experimental data from Materials Science literature with Large Language Models: an evaluation study
Luca Foppiano, Guillaume Lambard, Toshiyuki Amagasa, Masashi Ishii
0
0
This study is dedicated to assessing the capabilities of large language models (LLMs) such as GPT-3.5-Turbo, GPT-4, and GPT-4-Turbo in extracting structured information from scientific documents in materials science. To this end, we primarily focus on two critical tasks of information extraction: (i) a named entity recognition (NER) of studied materials and physical properties and (ii) a relation extraction (RE) between these entities. Due to the evident lack of datasets within Materials Informatics (MI), we evaluated using SuperMat, based on superconductor research, and MeasEval, a generic measurement evaluation corpus. The performance of LLMs in executing these tasks is benchmarked against traditional models based on the BERT architecture and rule-based approaches (baseline). We introduce a novel methodology for the comparative analysis of intricate material expressions, emphasising the standardisation of chemical formulas to tackle the complexities inherent in materials science information assessment. For NER, LLMs fail to outperform the baseline with zero-shot prompting and exhibit only limited improvement with few-shot prompting. However, a GPT-3.5-Turbo fine-tuned with the appropriate strategy for RE outperforms all models, including the baseline. Without any fine-tuning, GPT-4 and GPT-4-Turbo display remarkable reasoning and relationship extraction capabilities after being provided with merely a couple of examples, surpassing the baseline. Overall, the results suggest that although LLMs demonstrate relevant reasoning skills in connecting concepts, specialised models are currently a better choice for tasks requiring extracting complex domain-specific entities like materials. These insights provide initial guidance applicable to other materials science sub-domains in future work.
6/3/2024
Dynamic In-context Learning with Conversational Models for Data Extraction and Materials Property Prediction
Chinedu Ekuma
0
0
The advent of natural language processing and large language models (LLMs) has revolutionized the extraction of data from unstructured scholarly papers. However, ensuring data trustworthiness remains a significant challenge. In this paper, we introduce PropertyExtractor, an open-source tool that leverages advanced conversational LLMs like Google Gemini-Pro and OpenAI GPT-4, blends zero-shot with few-shot in-context learning, and employs engineered prompts for the dynamic refinement of structured information hierarchies, enabling autonomous, efficient, scalable, and accurate identification, extraction, and verification of material property data. Our tests on material data demonstrate precision and recall exceeding 93% with an error rate of approximately 10%, highlighting the effectiveness and versatility of the toolkit. We apply PropertyExtractor to generate a database of 2D material thicknesses, a critical parameter for device integration. The rapid evolution of the field has outpaced both experimental measurements and computational methods, creating a significant data gap. Our work addresses this gap and showcases the potential of PropertyExtractor as a reliable and efficient tool for the autonomous generation of diverse material property databases, advancing the field.
5/20/2024

Toward Reliable Ad-hoc Scientific Information Extraction: A Case Study on Two Materials Datasets
Satanu Ghosh, Neal R. Brodnik, Carolina Frey, Collin Holgate, Tresa M. Pollock, Samantha Daly, Samuel Carton
0
0
We explore the ability of GPT-4 to perform ad-hoc schema based information extraction from scientific literature. We assess specifically whether it can, with a basic prompting approach, replicate two existing material science datasets, given the manuscripts from which they were originally manually extracted. We employ materials scientists to perform a detailed manual error analysis to assess where the model struggles to faithfully extract the desired information, and draw on their insights to suggest research directions to address this broadly important task.
6/11/2024
💬
Exploring the use of a Large Language Model for data extraction in systematic reviews: a rapid feasibility study
Lena Schmidt, Kaitlyn Hair, Sergio Graziozi, Fiona Campbell, Claudia Kapp, Alireza Khanteymoori, Dawn Craig, Mark Engelbert, James Thomas
0
0
This paper describes a rapid feasibility study of using GPT-4, a large language model (LLM), to (semi)automate data extraction in systematic reviews. Despite the recent surge of interest in LLMs there is still a lack of understanding of how to design LLM-based automation tools and how to robustly evaluate their performance. During the 2023 Evidence Synthesis Hackathon we conducted two feasibility studies. Firstly, to automatically extract study characteristics from human clinical, animal, and social science domain studies. We used two studies from each category for prompt-development; and ten for evaluation. Secondly, we used the LLM to predict Participants, Interventions, Controls and Outcomes (PICOs) labelled within 100 abstracts in the EBM-NLP dataset. Overall, results indicated an accuracy of around 80%, with some variability between domains (82% for human clinical, 80% for animal, and 72% for studies of human social sciences). Causal inference methods and study design were the data extraction items with the most errors. In the PICO study, participants and intervention/control showed high accuracy (>80%), outcomes were more challenging. Evaluation was done manually; scoring methods such as BLEU and ROUGE showed limited value. We observed variability in the LLMs predictions and changes in response quality. This paper presents a template for future evaluations of LLMs in the context of data extraction for systematic review automation. Our results show that there might be value in using LLMs, for example as second or third reviewers. However, caution is advised when integrating models such as GPT-4 into tools. Further research on stability and reliability in practical settings is warranted for each type of data that is processed by the LLM.
5/24/2024