Exploring the use of a Large Language Model for data extraction in systematic reviews: a rapid feasibility study
2405.14445
0
0
💬
Abstract
This paper describes a rapid feasibility study of using GPT-4, a large language model (LLM), to (semi)automate data extraction in systematic reviews. Despite the recent surge of interest in LLMs there is still a lack of understanding of how to design LLM-based automation tools and how to robustly evaluate their performance. During the 2023 Evidence Synthesis Hackathon we conducted two feasibility studies. Firstly, to automatically extract study characteristics from human clinical, animal, and social science domain studies. We used two studies from each category for prompt-development; and ten for evaluation. Secondly, we used the LLM to predict Participants, Interventions, Controls and Outcomes (PICOs) labelled within 100 abstracts in the EBM-NLP dataset. Overall, results indicated an accuracy of around 80%, with some variability between domains (82% for human clinical, 80% for animal, and 72% for studies of human social sciences). Causal inference methods and study design were the data extraction items with the most errors. In the PICO study, participants and intervention/control showed high accuracy (>80%), outcomes were more challenging. Evaluation was done manually; scoring methods such as BLEU and ROUGE showed limited value. We observed variability in the LLMs predictions and changes in response quality. This paper presents a template for future evaluations of LLMs in the context of data extraction for systematic review automation. Our results show that there might be value in using LLMs, for example as second or third reviewers. However, caution is advised when integrating models such as GPT-4 into tools. Further research on stability and reliability in practical settings is warranted for each type of data that is processed by the LLM.
Create account to get full access
Overview
- This paper explores the feasibility of using a large language model (LLM) like GPT-4 to automate data extraction for systematic reviews.
- The researchers conducted two studies: 1) extracting study characteristics from human clinical, animal, and social science papers, and 2) predicting Participants, Interventions, Controls, and Outcomes (PICOs) from abstracts.
- The results showed an overall accuracy of around 80%, with some variability between domains.
- The paper presents a template for evaluating LLMs in the context of systematic review data extraction and suggests that LLMs could be useful as second or third reviewers, but caution is advised when integrating them into tools.
Plain English Explanation
The researchers in this study wanted to see if a powerful AI language model, called GPT-4, could be used to help automate the process of extracting data from research papers for systematic reviews. Systematic reviews are studies that collect and analyze all the available evidence on a particular topic to answer a specific question.
In the first part of the study, the researchers used GPT-4 to try and automatically extract key details about the studies, such as the types of participants, what treatments were tested, and what outcomes were measured. They tested this on a small set of papers from three different research areas: human clinical studies, animal studies, and social science studies.
In the second part of the study, the researchers used GPT-4 to try and identify the specific elements of a systematic review (called PICO: Participants, Interventions, Comparisons, and Outcomes) in the abstracts of 100 research papers.
Overall, the results showed that GPT-4 was able to extract this information with an accuracy of around 80%. However, the accuracy varied depending on the type of information and the research area. For example, the model was better at identifying the participants and interventions compared to the outcomes.
The researchers suggest that language models like GPT-4 could be useful as a second or third reviewer to help with data extraction for systematic reviews. However, they also caution that more research is needed to understand the reliability and stability of these models before fully integrating them into tools.
Technical Explanation
The researchers conducted two feasibility studies to explore the use of the large language model (LLM) GPT-4 for automating data extraction in systematic reviews.
In the first study, they used GPT-4 to automatically extract study characteristics (e.g., study design, participants, interventions, outcomes) from a small set of human clinical, animal, and social science studies. They used two studies from each domain for prompt development and ten for evaluation.
In the second study, the researchers used GPT-4 to predict the Participants, Interventions, Controls, and Outcomes (PICOs) labeled within 100 abstracts from the EBM-NLP dataset.
The overall results showed an accuracy of around 80%, with some variability between domains (82% for human clinical, 80% for animal, and 72% for human social sciences studies). The data extraction items with the most errors were causal inference methods and study design.
For the PICO prediction task, the model performed well on participants and intervention/control (>80% accuracy), but had more difficulty with outcomes.
The researchers evaluated the model's performance manually, and found that automated scoring methods like BLEU and ROUGE had limited value. They also observed variability in the model's predictions and changes in response quality.
The paper presents a template for future evaluations of LLMs in the context of systematic review data extraction and suggests that LLMs could be useful as second or third reviewers. However, the researchers caution that further research is needed on the stability and reliability of these models when used in practical settings for different types of data.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in this feasibility study. Firstly, the sample sizes were small, with only two studies per domain used for prompt development and ten for evaluation. Larger-scale studies would be needed to more robustly assess the performance of the LLM.
Additionally, the researchers note that causal inference methods and study design were the most challenging data extraction items for the LLM. This suggests that the model may struggle with more complex, conceptual aspects of research papers, and that additional training or prompting strategies may be needed to improve performance in these areas.
The researchers also observed variability in the LLM's predictions and changes in response quality, which raises concerns about the reliability and stability of the model's performance. Further research is warranted on the consistency and robustness of LLMs when used for systematic review data extraction in practical settings.
While the researchers suggest that LLMs could be useful as second or third reviewers, they caution that care must be taken when integrating these models into tools. The potential for errors or biases in the LLM's outputs would need to be carefully managed to ensure the integrity of the systematic review process.
Conclusion
This feasibility study provides a valuable template for evaluating the use of large language models like GPT-4 for automating data extraction in systematic reviews. The results suggest that LLMs can achieve reasonably high accuracy, but also highlight the need for further research on the stability, reliability, and limitations of these models in practical settings.
While LLMs may have the potential to assist in the systematic review process, the researchers emphasize that caution is advised when integrating them into tools. Ongoing evaluation and careful monitoring would be essential to ensure the quality and integrity of the data extraction and synthesis.
Overall, this study contributes to the growing body of research on the applications of advanced AI models in the context of scientific literature and research synthesis, and provides a foundation for future work in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Use of a Structured Knowledge Base Enhances Metadata Curation by Large Language Models
Sowmya S. Sundaram, Benjamin Solomon, Avani Khatri, Anisha Laumas, Purvesh Khatri, Mark A. Musen
0
0
Metadata play a crucial role in ensuring the findability, accessibility, interoperability, and reusability of datasets. This paper investigates the potential of large language models (LLMs), specifically GPT-4, to improve adherence to metadata standards. We conducted experiments on 200 random data records describing human samples relating to lung cancer from the NCBI BioSample repository, evaluating GPT-4's ability to suggest edits for adherence to metadata standards. We computed the adherence accuracy of field name-field value pairs through a peer review process, and we observed a marginal average improvement in adherence to the standard data dictionary from 79% to 80% (p<0.01). We then prompted GPT-4 with domain information in the form of the textual descriptions of CEDAR templates and recorded a significant improvement to 97% from 79% (p<0.01). These results indicate that, while LLMs may not be able to correct legacy metadata to ensure satisfactory adherence to standards when unaided, they do show promise for use in automated metadata curation when integrated with a structured knowledge base.
4/10/2024
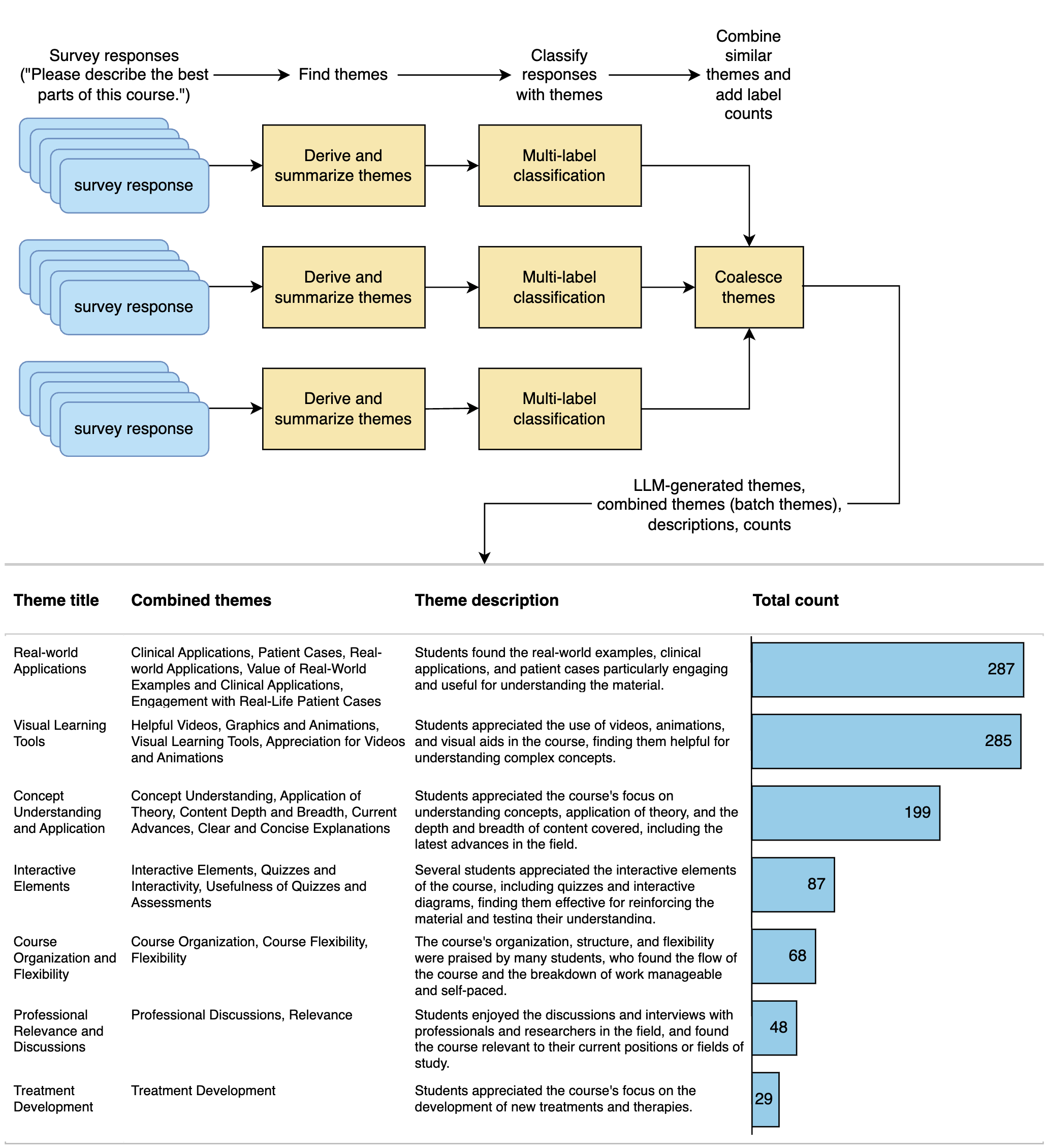
New!A Large Language Model Approach to Educational Survey Feedback Analysis
Michael J. Parker, Caitlin Anderson, Claire Stone, YeaRim Oh
0
0
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
6/28/2024
💬
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Fan Gao, Hang Jiang, Rui Yang, Qingcheng Zeng, Jinghui Lu, Moritz Blum, Dairui Liu, Tianwei She, Yuang Jiang, Irene Li
0
0
Educational materials such as survey articles in specialized fields like computer science traditionally require tremendous expert inputs and are therefore expensive to create and update. Recently, Large Language Models (LLMs) have achieved significant success across various general tasks. However, their effectiveness and limitations in the education domain are yet to be fully explored. In this work, we examine the proficiency of LLMs in generating succinct survey articles specific to the niche field of NLP in computer science, focusing on a curated list of 99 topics. Automated benchmarks reveal that GPT-4 surpasses its predecessors, inluding GPT-3.5, PaLM2, and LLaMa2 by margins ranging from 2% to 20% in comparison to the established ground truth. We compare both human and GPT-based evaluation scores and provide in-depth analysis. While our findings suggest that GPT-created surveys are more contemporary and accessible than human-authored ones, certain limitations were observed. Notably, GPT-4, despite often delivering outstanding content, occasionally exhibited lapses like missing details or factual errors. At last, we compared the rating behavior between humans and GPT-4 and found systematic bias in using GPT evaluation.
5/24/2024

Large Language Models Reflect Human Citation Patterns with a Heightened Citation Bias
Andres Algaba, Carmen Mazijn, Vincent Holst, Floriano Tori, Sylvia Wenmackers, Vincent Ginis
0
0
Citation practices are crucial in shaping the structure of scientific knowledge, yet they are often influenced by contemporary norms and biases. The emergence of Large Language Models (LLMs) like GPT-4 introduces a new dynamic to these practices. Interestingly, the characteristics and potential biases of references recommended by LLMs that entirely rely on their parametric knowledge, and not on search or retrieval-augmented generation, remain unexplored. Here, we analyze these characteristics in an experiment using a dataset of 166 papers from AAAI, NeurIPS, ICML, and ICLR, published after GPT-4's knowledge cut-off date, encompassing 3,066 references in total. In our experiment, GPT-4 was tasked with suggesting scholarly references for the anonymized in-text citations within these papers. Our findings reveal a remarkable similarity between human and LLM citation patterns, but with a more pronounced high citation bias in GPT-4, which persists even after controlling for publication year, title length, number of authors, and venue. Additionally, we observe a large consistency between the characteristics of GPT-4's existing and non-existent generated references, indicating the model's internalization of citation patterns. By analyzing citation graphs, we show that the references recommended by GPT-4 are embedded in the relevant citation context, suggesting an even deeper conceptual internalization of the citation networks. While LLMs can aid in citation generation, they may also amplify existing biases and introduce new ones, potentially skewing scientific knowledge dissemination. Our results underscore the need for identifying the model's biases and for developing balanced methods to interact with LLMs in general.
5/30/2024