A Flexible and Scalable Approach for Collecting Wildlife Advertisements on the Web

0
Sign in to get full access
Overview
- A flexible and scalable approach for collecting wildlife advertisements on the web
- Leverages web scraping techniques to gather data on illegal wildlife trade
- Aims to support conservation efforts and law enforcement by providing insights into this illicit market
Plain English Explanation
The paper presents a method for efficiently collecting and analyzing online advertisements related to the illegal wildlife trade. This is an important problem, as wildlife trafficking poses a significant threat to many endangered species around the world.
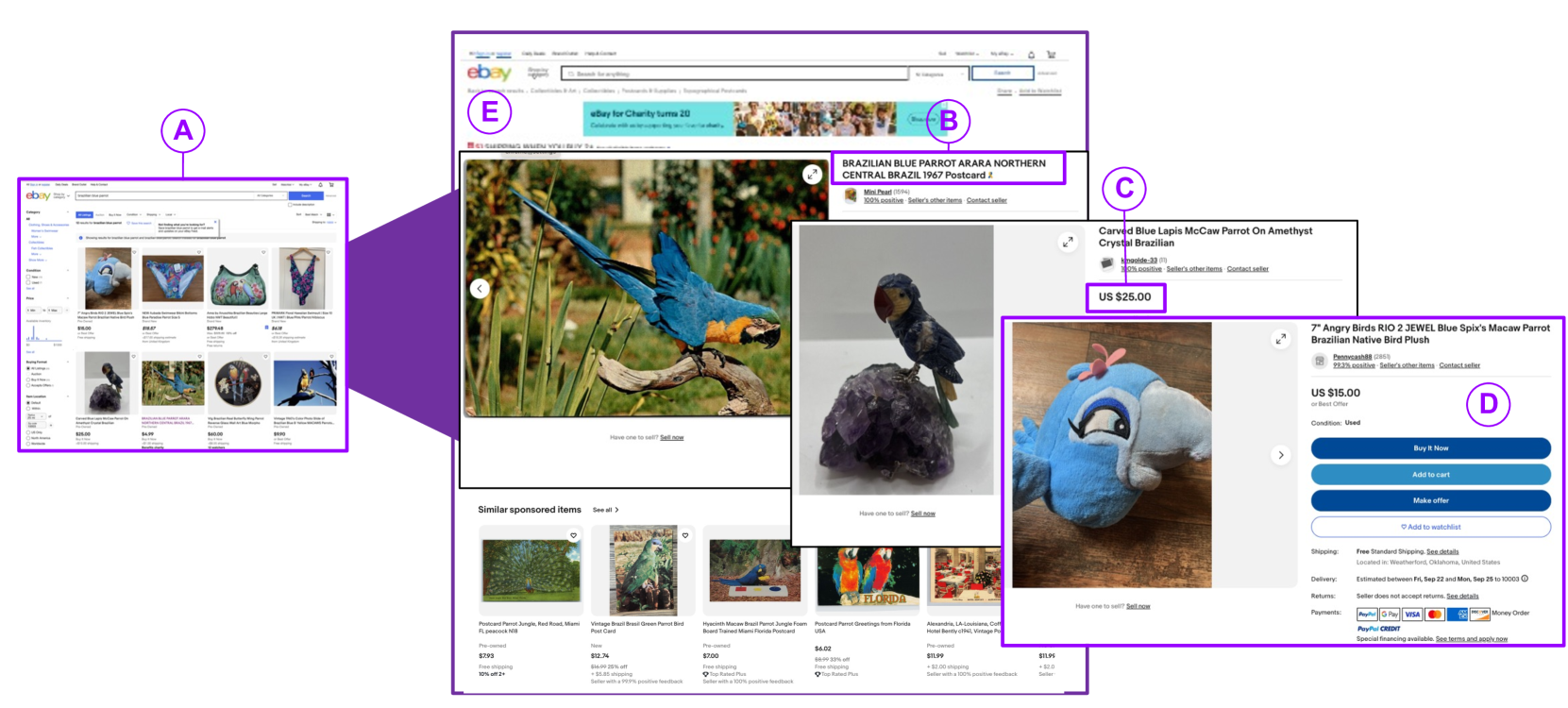
The approach involves using web scraping techniques to automatically gather data from various online platforms where these advertisements may appear. This includes parsing the text and images in the ads to extract relevant information, such as the species being sold, the location, and the contact details of the sellers.
By aggregating and analyzing this data, the researchers hope to provide valuable insights to conservation efforts and law enforcement agencies working to combat the illegal wildlife trade. The flexibility and scalability of the system allow it to be adapted to different regions and scenarios, making it a potentially powerful tool for tackling this global issue.
Technical Explanation
The paper outlines a data collection pipeline that leverages web scraping techniques to gather information on wildlife advertisements from various online platforms. The pipeline includes modules for web crawling, content extraction, and data storage, allowing it to efficiently collect and organize large amounts of relevant data.
The web crawling module uses a combination of targeted searches and broad web crawling to identify potential sources of wildlife advertisements. The content extraction module then processes the collected web pages to extract key details, such as the species, location, and contact information.
The researchers also developed techniques to handle challenges like dealing with dynamic web content, identifying relevant advertisements, and ensuring data quality. This includes using machine learning models to classify the content of web pages and advertisements.
The data collected through this pipeline is stored in a centralized database, allowing for further analysis and exploration of the illegal wildlife trade market. The researchers demonstrate the effectiveness of their approach through a case study focusing on the trade of primates in Southeast Asia.
Critical Analysis
The paper presents a compelling and well-designed approach for collecting data on the illegal wildlife trade. The flexibility and scalability of the system are its key strengths, as they allow the method to be adapted to different regions and scenarios.
However, the paper does acknowledge some limitations of the current implementation. For example, the web crawling and content extraction techniques may not always be able to identify all relevant advertisements, and there are challenges in verifying the accuracy of the extracted data.
Additionally, the paper does not address potential privacy and ethical concerns that may arise from collecting and analyzing data on illegal activities. It would be important to consider how to handle sensitive information and ensure that the research does not inadvertently enable or encourage the very activities it aims to combat.
Further research could also explore ways to integrate the system with other data sources, such as wildlife monitoring systems or law enforcement databases, to enhance the overall effectiveness and impact of the approach.
Conclusion
This paper presents a flexible and scalable approach for collecting data on the illegal wildlife trade by leveraging web scraping techniques. The data collection pipeline allows for the efficient gathering and organization of relevant information, which can then be used to support conservation efforts and law enforcement initiatives.
While the paper acknowledges some limitations, the overall approach appears to be a promising tool for tackling this global issue. By providing insights into the dynamics and patterns of the illegal wildlife trade, this research can contribute to more informed and effective strategies for protecting endangered species and disrupting illicit markets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Flexible and Scalable Approach for Collecting Wildlife Advertisements on the Web
Juliana Barbosa, Sunandan Chakraborty, Juliana Freire
Wildlife traffickers are increasingly carrying out their activities in cyberspace. As they advertise and sell wildlife products in online marketplaces, they leave digital traces of their activity. This creates a new opportunity: by analyzing these traces, we can obtain insights into how trafficking networks work as well as how they can be disrupted. However, collecting such information is difficult. Online marketplaces sell a very large number of products and identifying ads that actually involve wildlife is a complex task that is hard to automate. Furthermore, given that the volume of data is staggering, we need scalable mechanisms to acquire, filter, and store the ads, as well as to make them available for analysis. In this paper, we present a new approach to collect wildlife trafficking data at scale. We propose a data collection pipeline that combines scoped crawlers for data discovery and acquisition with foundational models and machine learning classifiers to identify relevant ads. We describe a dataset we created using this pipeline which is, to the best of our knowledge, the largest of its kind: it contains almost a million ads obtained from 41 marketplaces, covering 235 species and 20 languages. The source code is publicly available at url{https://github.com/VIDA-NYU/wildlife_pipeline}.
Read more7/29/2024
🌿
0
On the Challenges of Creating Datasets for Analyzing Commercial Sex Advertisements to Assess Human Trafficking Risk and Organized Activity
Pablo Rivas, Tomas Cerny, Alejandro Rodriguez Perez, Javier Turek, Laurie Giddens, Gisela Bichler, Stacie Petter
Our study addresses the challenges of building datasets to understand the risks associated with organized activities and human trafficking through commercial sex advertisements. These challenges include data scarcity, rapid obsolescence, and privacy concerns. Traditional approaches, which are not automated and are difficult to reproduce, fall short in addressing these issues. We have developed a reproducible and automated methodology to analyze five million advertisements. In the process, we identified further challenges in dataset creation within this sensitive domain. This paper presents a streamlined methodology to assist researchers in constructing effective datasets for combating organized crime, allowing them to focus on advancing detection technologies.
Read more5/24/2024

0
Automating the Analysis of Public Saliency and Attitudes towards Biodiversity from Digital Media
Noah Giebink, Amrita Gupta, Diogo Ver`issimo, Charlotte H. Chang, Tony Chang, Angela Brennan, Brett Dickson, Alex Bowmer, Jonathan Baillie
Measuring public attitudes toward wildlife provides crucial insights into our relationship with nature and helps monitor progress toward Global Biodiversity Framework targets. Yet, conducting such assessments at a global scale is challenging. Manually curating search terms for querying news and social media is tedious, costly, and can lead to biased results. Raw news and social media data returned from queries are often cluttered with irrelevant content and syndicated articles. We aim to overcome these challenges by leveraging modern Natural Language Processing (NLP) tools. We introduce a folk taxonomy approach for improved search term generation and employ cosine similarity on Term Frequency-Inverse Document Frequency vectors to filter syndicated articles. We also introduce an extensible relevance filtering pipeline which uses unsupervised learning to reveal common topics, followed by an open-source zero-shot Large Language Model (LLM) to assign topics to news article titles, which are then used to assign relevance. Finally, we conduct sentiment, topic, and volume analyses on resulting data. We illustrate our methodology with a case study of news and X (formerly Twitter) data before and during the COVID-19 pandemic for various mammal taxa, including bats, pangolins, elephants, and gorillas. During the data collection period, up to 62% of articles including keywords pertaining to bats were deemed irrelevant to biodiversity, underscoring the importance of relevance filtering. At the pandemic's onset, we observed increased volume and a significant sentiment shift toward horseshoe bats, which were implicated in the pandemic, but not for other focal taxa. The proposed methods open the door to conservation practitioners applying modern and emerging NLP tools, including LLMs out of the box, to analyze public perceptions of biodiversity during current events or campaigns.
Read more5/6/2024
🤿
0
Metadata augmented deep neural networks for wild animal classification
Aslak T{o}n, Ammar Ahmed, Ali Shariq Imran, Mohib Ullah, R. Muhammad Atif Azad
Camera trap imagery has become an invaluable asset in contemporary wildlife surveillance, enabling researchers to observe and investigate the behaviors of wild animals. While existing methods rely solely on image data for classification, this may not suffice in cases of suboptimal animal angles, lighting, or image quality. This study introduces a novel approach that enhances wild animal classification by combining specific metadata (temperature, location, time, etc) with image data. Using a dataset focused on the Norwegian climate, our models show an accuracy increase from 98.4% to 98.9% compared to existing methods. Notably, our approach also achieves high accuracy with metadata-only classification, highlighting its potential to reduce reliance on image quality. This work paves the way for integrated systems that advance wildlife classification technology.
Read more9/10/2024