Fluid Implicit Particle Simulation for CPU and GPU

0
🎲
Sign in to get full access
Overview
- This paper presents a fluid simulation technique called Fluid Implicit Particle (FLIP) that can be efficiently implemented on both CPUs and GPUs.
- FLIP combines the strengths of grid-based and particle-based fluid simulation methods, allowing for realistic and visually appealing fluid dynamics with reduced computational cost.
- The researchers demonstrate the performance and visual quality of their FLIP implementation on a variety of fluid simulation scenarios, showing its potential for real-time and interactive applications.
Plain English Explanation
Imagine you have a glass of water sitting on a table. When you tilt the glass, the water inside starts to move and slosh around. Simulating the complex motion of fluids like water is a challenging problem in computer graphics and animation.
Traditionally, there have been two main approaches to fluid simulation: grid-based methods and particle-based methods. Grid-based methods divide the space into a grid and calculate the fluid's motion using the properties at each grid cell. Particle-based methods model the fluid as a collection of individual particles that interact with each other.
The FLIP method in this paper combines the best of both approaches. It uses a grid to efficiently compute the overall fluid dynamics, but also tracks individual fluid particles to capture small-scale details and splashes. This hybrid approach allows FLIP to produce realistic fluid simulations while being computationally efficient enough to run in real-time, such as for interactive applications or video games.
The researchers show that their FLIP implementation can run well on both CPUs and GPUs, making it a flexible and versatile tool for fluid simulation. They demonstrate the technique on a variety of scenarios, from simple water sloshing to more complex fluid interactions, showcasing its ability to create visually appealing and physically plausible fluid dynamics.
Technical Explanation
The core of the FLIP method is to use a background grid to solve the Navier-Stokes equations that govern fluid motion, while also tracking individual fluid particles. This allows FLIP to efficiently compute the large-scale fluid behavior while still capturing small-scale details.
The algorithm works as follows:
- Initialize the fluid simulation by seeding the domain with fluid particles.
- Advect the fluid particles using a semi-Lagrangian scheme, which moves the particles along the velocity field.
- Compute the new velocity field on the background grid using the Navier-Stokes equations.
- Project the updated grid velocities back onto the fluid particles to maintain mass conservation.
- Repeat steps 2-4 for the next simulation timestep.
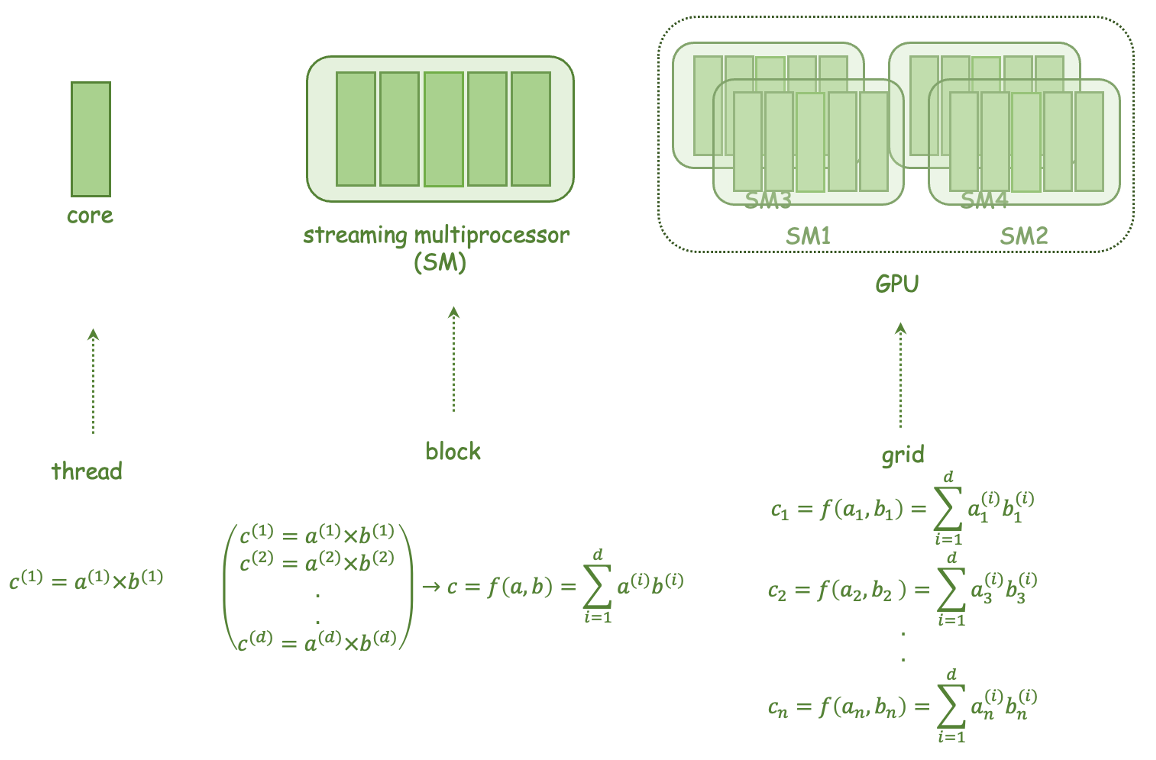
The researchers implemented FLIP using both CPU and GPU parallelization techniques, allowing the method to run efficiently on a variety of hardware. They evaluated the performance and visual quality of their FLIP implementation on several fluid simulation benchmarks, comparing it to other state-of-the-art methods.
Critical Analysis
The paper provides a thorough technical explanation of the FLIP fluid simulation technique and demonstrates its effectiveness across a range of scenarios. The hybrid grid-particle approach seems well-suited for real-time applications, as it can produce visually plausible fluid motion at a lower computational cost than pure grid-based or particle-based methods.
However, the paper does acknowledge some limitations of FLIP. For example, the method may struggle to handle complex topological changes in the fluid, such as the breakup of a water stream into droplets. Additionally, the particle-based component of FLIP can be sensitive to the initial particle distribution, which could impact the simulation's stability and accuracy.
The authors also note that their GPU implementation, while efficient, requires careful memory management and optimization to achieve the best performance. This may pose challenges for developers who are not familiar with GPU programming.
Further research could explore ways to address these limitations, such as incorporating more advanced particle handling techniques or developing adaptive grid refinement strategies. Exploring the application of FLIP to other types of fluids, such as smoke or lava, could also be an interesting avenue for future work.
Conclusion
The FLIP fluid simulation technique presented in this paper offers an attractive compromise between the realism of particle-based methods and the computational efficiency of grid-based approaches. By combining these two paradigms, the researchers have developed a flexible and versatile tool for creating visually compelling fluid simulations that can run in real-time on both CPUs and GPUs.
The paper's thorough technical explanation and performance evaluation demonstrate the potential of FLIP for a wide range of interactive applications, from video games to virtual reality experiences. While the method has some limitations, the researchers have made a valuable contribution to the field of fluid simulation, paving the way for further advancements in this important area of computer graphics and animation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
Fluid Implicit Particle Simulation for CPU and GPU
Pedro Centeno, Jo~ao Madeiras Pereira
One of the current challenges in physically-based simulations, and, more specifically, fluid simulations, is to produce visually appealing results at interactive rates, capable of being used in multiple forms of media. In recent times, a lot of effort has been made with regards to this with the use of multi-core architectures, as many of the computations involved in the algorithms for these simulations are very well suited for these architectures. Although there is a considerable amount of works regarding acceleration techniques in this field, there is yet room to further explore and analyze some of them. To investigate this problem, we surveyed the topic of fluid simulations and some of the recent contributions towards this field. Additionally, we implemented two versions of a fluid simulation algorithm, one on the CPU and the other on the GPU using NVIDIA's CUDA framework, with the intent of gaining a better understanding of the effort needed to move these simulations to a multi-core architecture and the performance gains that we get with it.
Read more4/3/2024

0
Speed, power and cost implications for GPU acceleration of Computational Fluid Dynamics on HPC systems
Zachary Cooper-Baldock, Brenda Vara Almirall, Kiao Inthavong
Computational Fluid Dynamics (CFD) is the simulation of fluid flow undertaken with the use of computational hardware. The underlying equations are computationally challenging to solve and necessitate high performance computing (HPC) to resolve in a practical timeframe when a reasonable level of fidelity is required. The simulations are memory intensive, having previously been limited to central processing unit (CPU) solvers, as graphics processing unit (GPU) video random access memory (VRAM) was insufficient. However, with recent developments in GPU design and increases to VRAM, GPU acceleration of CPU solved workflows is now possible. At HPC scale however, many operational details are still unknown. This paper utilizes ANSYS Fluent, a leading commercial code in CFD, to investigate the compute speed, power consumption and service unit (SU) cost considerations for the GPU acceleration of CFD workflows on HPC architectures. To provide a comprehensive analysis, different CPU architectures, and GPUs have been assessed. It is seen that GPU compute speed is faster, however, the initialisation speed, power and cost performance is less clear cut. Whilst the larger A100 cards perform well with respect to power consumption, this is not observed for the V100 cards. In situations where more than one GPU is required, their adoption may not be beneficial from a power or cost perspective.
Read more4/4/2024
0
A Preliminary Study on Accelerating Simulation Optimization with GPU Implementation
Jinghai He, Haoyu Liu, Yuhang Wu, Zeyu Zheng, Tingyu Zhu
We provide a preliminary study on utilizing GPU (Graphics Processing Unit) to accelerate computation for three simulation optimization tasks with either first-order or second-order algorithms. Compared to the implementation using only CPU (Central Processing Unit), the GPU implementation benefits from computational advantages of parallel processing for large-scale matrices and vectors operations. Numerical experiments demonstrate computational advantages of utilizing GPU implementation in simulation optimization problems, and show that such advantage comparatively further increase as the problem scale increases.
Read more4/19/2024

0
A GPU-ready pseudo-spectral method for direct numerical simulations of multiphase turbulence
Alessio Roccon
In this work, we detail the GPU-porting of an in-house pseudo-spectral solver tailored towards large-scale simulations of interface-resolved simulation of drop- and bubble-laden turbulent flows. The code relies on direct numerical simulation of the Navier-Stokes equations, used to describe the flow field, coupled with a phase-field method, used to describe the shape, deformation, and topological changes of the interface of the drops or bubbles. The governing equations -Navier-Stokes and Cahn-Hilliard equations-are solved using a pseudo-spectral method that relies on transforming the variables in the wavenumber space. The code targets large-scale simulations of drop- and bubble-laden turbulent flows and relies on a multilevel parallelism. The first level of parallelism relies on the message-passing interface (MPI) and is used on multi-core architectures in CPU-based infrastructures. A second level of parallelism relies on OpenACC directives and cuFFT libraries and is used to accelerate the code execution when GPU-based infrastructures are targeted. The resulting multiphase flow solver can be efficiently executed in heterogeneous computing infrastructures and exhibits a remarkable speed-up when GPUs are employed. Thanks to the modular structure of the code and the use of a directive-based strategy to offload code execution on GPUs, only minor code modifications are required when targeting different computing architectures. This improves code maintenance, version control and the implementation of additional modules or governing equations.
Read more6/4/2024