FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion
2406.06858
0
0

Abstract
Large deep learning models have demonstrated strong ability to solve many tasks across a wide range of applications. Those large models typically require training and inference to be distributed. Tensor parallelism is a common technique partitioning computation of an operation or layer across devices to overcome the memory capacity limitation of a single processor, and/or to accelerate computation to meet a certain latency requirement. However, this kind of parallelism introduces additional communication that might contribute a significant portion of overall runtime. Thus limits scalability of this technique within a group of devices with high speed interconnects, such as GPUs with NVLinks in a node. This paper proposes a novel method, Flux, to significantly hide communication latencies with dependent computations for GPUs. Flux over-decomposes communication and computation operations into much finer-grained operations and further fuses them into a larger kernel to effectively hide communication without compromising kernel efficiency. Flux can potentially overlap up to 96% of communication given a fused kernel. Overall, it can achieve up to 1.24x speedups for training over Megatron-LM on a cluster of 128 GPUs with various GPU generations and interconnects, and up to 1.66x and 1.30x speedups for prefill and decoding inference over vLLM on a cluster with 8 GPUs with various GPU generations and interconnects.
Create account to get full access
Overview
• This research paper introduces Flux, a new technique for improving communication overlap on GPUs in distributed machine learning workloads.
• Flux leverages kernel fusion, a method of combining multiple GPU kernel launches into a single launch, to reduce the overhead of communication operations and allow them to be overlapped with computation.
• The key idea is to fuse the communication kernels with the computation kernels, enabling the communication to be executed concurrently with the computation and reducing the overall execution time.
Plain English Explanation
Flux is a new approach to speed up distributed machine learning on GPUs. In distributed machine learning, different parts of a neural network are trained on separate computers. These computers need to communicate with each other to share the results of their computations. This communication can be slow and can slow down the entire training process.
Flux tries to solve this problem by combining the communication and computation steps into a single step. Instead of doing the communication and computation separately, Flux fuses them together. This allows the communication to happen at the same time as the computation, which reduces the overall time needed for training.
The key insight behind Flux is that modern GPUs can execute multiple operations at the same time. By carefully orchestrating the communication and computation kernels, Flux can take advantage of this parallelism to overlap the communication and computation, speeding up the overall training process.
Technical Explanation
Flux builds on the concept of tensor parallelism and communication-computation overlap. Tensor parallelism is a distributed training technique where different parts of the neural network are assigned to different GPUs. Communication is required to share the results of these computations across GPUs.
Traditionally, this communication has been performed as a separate step from the computation, which can lead to inefficiencies. Distrifusion and Pipefusion have explored techniques to overlap communication and computation, but they rely on specialized hardware or complex scheduling algorithms.
Flux takes a different approach by utilizing kernel fusion, a technique where multiple GPU kernel launches are combined into a single launch. This allows the communication kernels to be fused with the computation kernels, enabling the communication to be executed concurrently with the computation.
The paper presents a detailed analysis of the performance characteristics of Flux and compares it to state-of-the-art techniques for communication overlap. The results demonstrate that Flux can achieve significantly faster training times by effectively overlapping communication and computation on GPUs.
Critical Analysis
The paper provides a thorough evaluation of Flux and compares it to other techniques for communication overlap in distributed machine learning. The experimental results seem robust and the authors have made a strong case for the effectiveness of their approach.
One potential limitation of Flux is that it relies on the ability to fuse communication and computation kernels. This may not be possible in all scenarios, particularly when the communication patterns are complex or the computation kernels are not amenable to fusion. The paper does not address these edge cases in detail.
Additionally, the paper focuses on tensor parallelism, but it would be interesting to see how Flux performs in other distributed training scenarios, such as data parallelism or pipeline parallelism. Towards Universal Performance Modeling of Machine Learning Training has explored some of these tradeoffs, and it could provide useful insights for further evaluating Flux.
Overall, Flux is a promising technique that could have significant impact on the performance of distributed machine learning workloads on GPUs. The paper provides a solid technical foundation and demonstrates the potential of kernel fusion for overlapping communication and computation.
Conclusion
Flux is a novel technique that leverages kernel fusion to enable fast, software-based communication overlap on GPUs for distributed machine learning workloads. By fusing communication and computation kernels, Flux can effectively overlap these operations and achieve significant performance improvements compared to existing approaches.
The paper provides a comprehensive evaluation of Flux and demonstrates its effectiveness across a range of benchmarks. While there are some potential limitations, Flux represents an important step forward in optimizing the performance of distributed machine learning on GPUs.
As the demand for larger and more complex neural networks continues to grow, techniques like Flux will become increasingly important for enabling efficient and scalable distributed training. This research contributes to the ongoing effort to push the boundaries of what is possible in distributed machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Optimizing Distributed ML Communication with Fused Computation-Collective Operations
Kishore Punniyamurthy, Khaled Hamidouche, Bradford M. Beckmann
0
0
In order to satisfy their ever increasing capacity and compute requirements, machine learning models are distributed across multiple nodes using numerous parallelism strategies. As a result, collective communications are often on the critical path, and hiding their latency by overlapping kernel-granular communication and computation is difficult due to the absence of independent computation. In this work, we propose fusing computation with dependent collective communication by leveraging GPUs' massive parallelism and GPU-initiated communication. We have developed self-contained GPU kernels where workgroups (WGs) immediately communicate their results to remote GPUs when they complete their computation. Meanwhile, other WGs within the same kernel perform overlapping computation, maintaining high ALU utilization. We demonstrate our approach by creating three prototype fused operators (embedding + All-to-All, GEMV + AllReduce, and GEMM + All-to-All) to address the pervasive communication overheads observed in DLRM, Transformers and MoE model architectures. In order to demonstrate that our approach can be integrated into ML frameworks for wide adoption in production environments, we expose our fused operators as new PyTorch operators as well as extend the Triton framework to enable them. Our evaluations show that our approach can effectively overlap communication with computations, subsequently reducing their combined execution time than the current collective library-based approaches. Our scale-up GEMV + AllReduce and GEMM + All-to-All implementations achieve up to 22% and 20% lower execution time, while our fused embedding + All-to-All reduces execution time by 20% and 31% for intra-node and inter-node configurations. Large scale-out simulations indicate that our approach reduces DLRM execution time by 21% for 128 node system.
4/24/2024
🔍
A 4D Hybrid Algorithm to Scale Parallel Training to Thousands of GPUs
Siddharth Singh, Prajwal Singhania, Aditya K. Ranjan, Zack Sating, Abhinav Bhatele
0
0
Heavy communication, in particular, collective operations, can become a critical performance bottleneck in scaling the training of billion-parameter neural networks to large-scale parallel systems. This paper introduces a four-dimensional (4D) approach to optimize communication in parallel training. This 4D approach is a hybrid of 3D tensor and data parallelism, and is implemented in the AxoNN framework. In addition, we employ two key strategies to further minimize communication overheads. First, we aggressively overlap expensive collective operations (reduce-scatter, all-gather, and all-reduce) with computation. Second, we develop an analytical model to identify high-performing configurations within the large search space defined by our 4D algorithm. This model empowers practitioners by simplifying the tuning process for their specific training workloads. When training an 80-billion parameter GPT on 1024 GPUs of Perlmutter, AxoNN surpasses Megatron-LM, a state-of-the-art framework, by a significant 26%. Additionally, it achieves a significantly high 57% of the theoretical peak FLOP/s or 182 PFLOP/s in total.
5/15/2024

DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Muyang Li, Tianle Cai, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li, Song Han
0
0
Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
4/17/2024
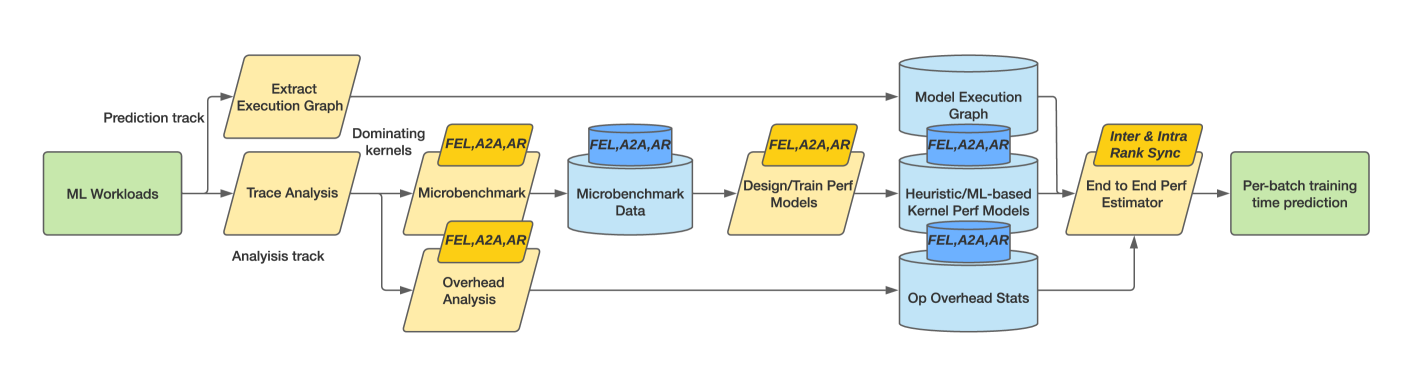
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
0
0
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
4/30/2024