Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
2404.12674
0
0
Abstract
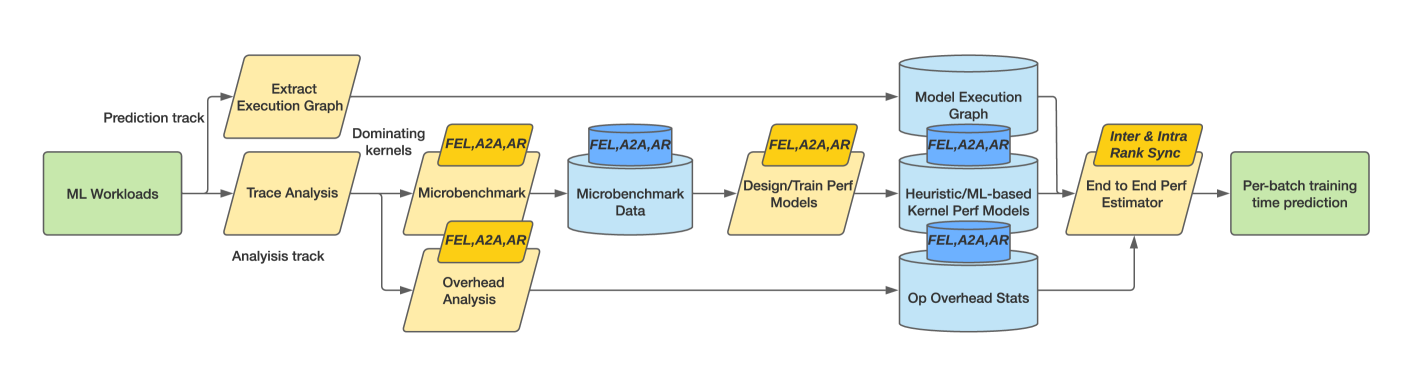
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a performance modeling approach for training machine learning models on multi-GPU platforms.
- The proposed method aims to provide a universal model that can accurately predict the training time across different deep learning architectures and hardware configurations.
- The authors evaluate their approach on three diverse machine learning tasks: Deep Learning Recommendation Model (DLRM), natural language processing (NLP), and computer vision.
Plain English Explanation
The researchers in this paper have developed a way to predict how long it will take to train different machine learning models on computers with multiple graphics processing units (GPUs). Training large, complex machine learning models can be a very time-consuming process, so being able to accurately estimate the training time in advance is valuable.
The researchers' approach is designed to work for a wide variety of machine learning tasks, from recommender systems to natural language processing to computer vision. Rather than creating a separate performance model for each task, they've developed a single "universal" model that can be applied more broadly.
The key idea is to identify the important factors that influence training time, such as the model architecture, the number of GPUs, the amount of data being processed, and so on. By understanding how these factors interact, the researchers can build a mathematical model to predict the training time for a given set of conditions.
Technical Explanation
The authors propose a "universal" performance modeling approach that can accurately predict the training time for machine learning models across different deep learning architectures and hardware configurations.
The core of their method is a mathematical model that captures the key factors influencing training performance, including:
- Model architecture and hyperparameters
- Hardware configuration (number and types of GPUs)
- Dataset size and characteristics
- Training dynamics (e.g. convergence rate)
By incorporating these variables, the authors claim their model can provide accurate training time estimates for a wide range of deep learning tasks, including DLRM for recommender systems, NLP models, and computer vision.
The authors validate their performance modeling approach through extensive experiments on diverse machine learning workloads and hardware configurations. They demonstrate that their model can predict training times within 10-15% of the actual observed values, outperforming previous performance modeling techniques.
Critical Analysis
The authors have put forth a compelling approach to tackle the challenge of performance modeling for machine learning training on multi-GPU systems. A key strength of their work is the focus on developing a "universal" model that can work across a wide range of deep learning tasks and architectures, rather than relying on task-specific models.
However, the paper does not deeply explore the limitations of their approach. For example, it's unclear how well the model would generalize to entirely new types of machine learning problems or hardware configurations beyond those evaluated in the experiments. Further research may be needed to understand the broader applicability and potential blind spots of this performance modeling technique.
Additionally, the paper does not provide much insight into the practical implications of their work. While accurate training time estimation is valuable, the authors could have discussed how this capability could be leveraged to improve model development workflows or resource allocation in production environments.
Overall, this is a technically solid piece of work that takes an important step towards more universal and accurate performance modeling for deep learning. But there remain opportunities to further expand the scope and practical impact of this research.
Conclusion
This paper presents a novel performance modeling approach that can accurately predict the training time for a wide variety of machine learning workloads on multi-GPU platforms. By incorporating key factors like model architecture, hardware configuration, and dataset characteristics, the authors have developed a "universal" model that outperforms previous task-specific techniques.
The validation of this approach across diverse deep learning tasks, from recommender systems to natural language processing to computer vision, demonstrates its broad applicability. While there are still some open questions around the model's generalization capabilities, this work represents an important advance in enabling more efficient and informed machine learning development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
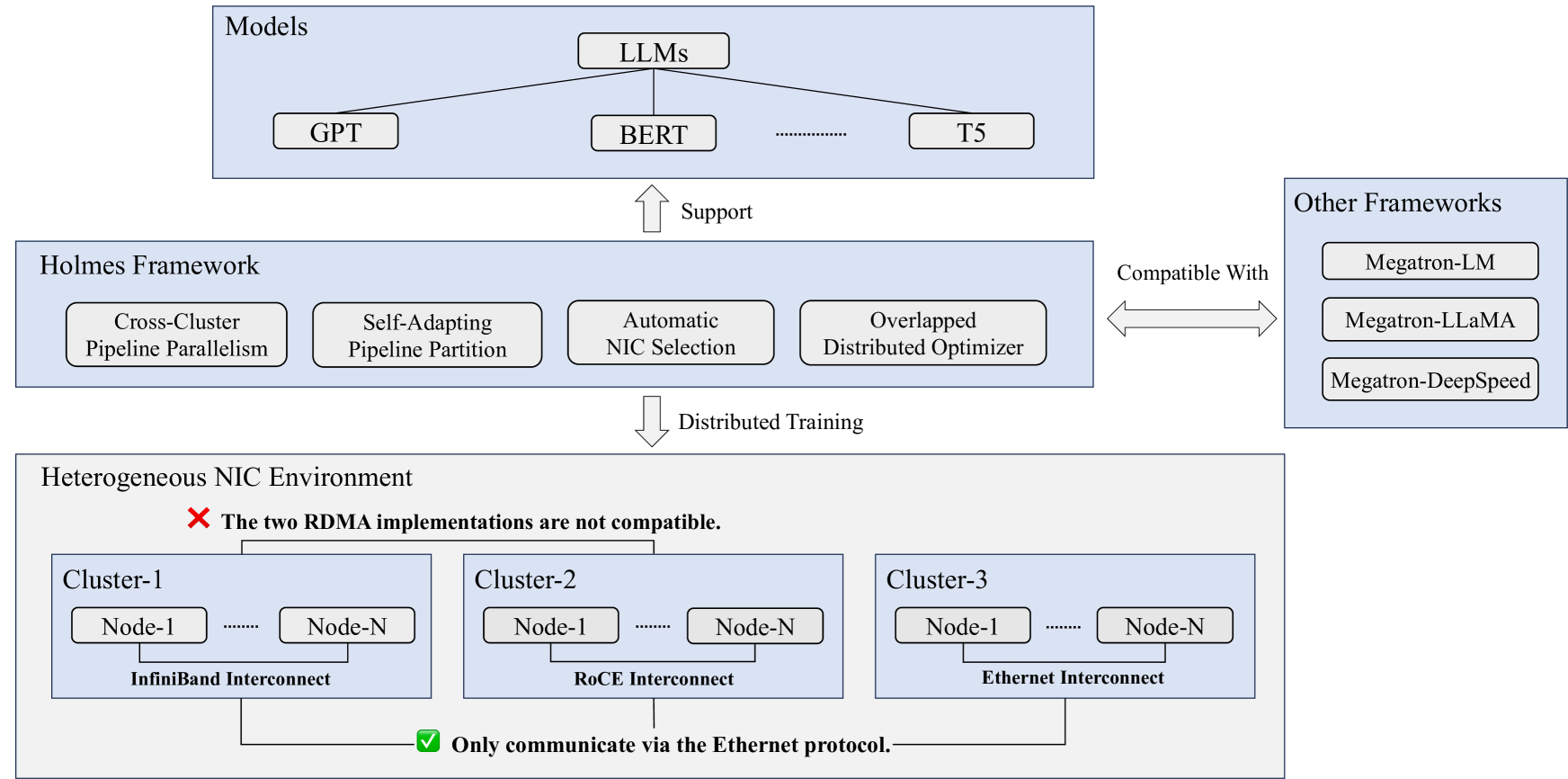
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Fei Yang, Shuang Peng, Ning Sun, Fangyu Wang, Yuanyuan Wang, Fu Wu, Jiezhong Qiu, Aimin Pan
0
0
Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
4/30/2024
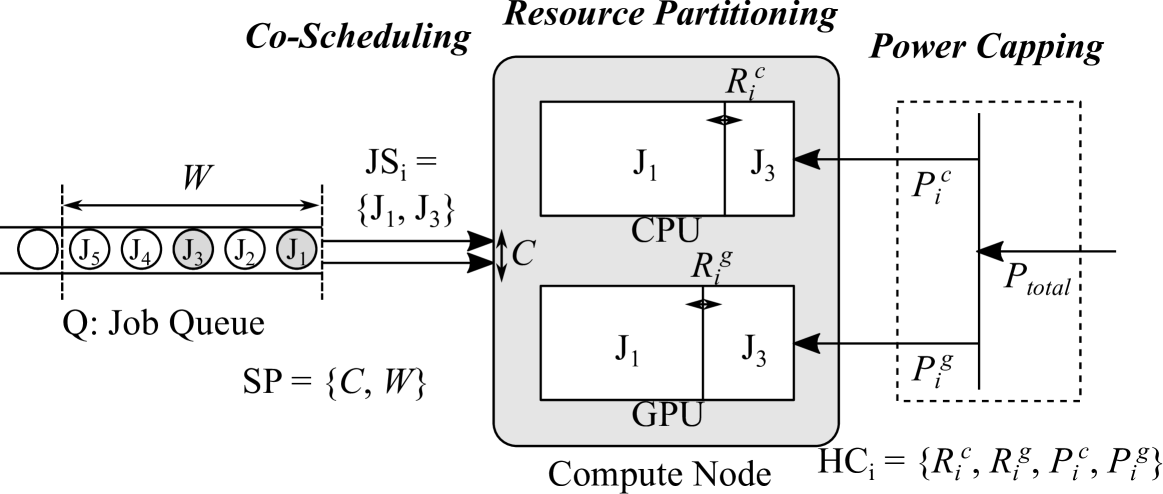
Orchestrated Co-scheduling, Resource Partitioning, and Power Capping on CPU-GPU Heterogeneous Systems via Machine Learning
Issa Saba, Eishi Arima, Dai Liu, Martin Schulz
0
0
CPU-GPU heterogeneous architectures are now commonly used in a wide variety of computing systems from mobile devices to supercomputers. Maximizing the throughput for multi-programmed workloads on such systems is indispensable as one single program typically cannot fully exploit all available resources. At the same time, power consumption is a key issue and often requires optimizing power allocations to the CPU and GPU while enforcing a total power constraint, in particular when the power/thermal requirements are strict. The result is a system-wide optimization problem with several knobs. In particular we focus on (1) co-scheduling decisions, i.e., selecting programs to co-locate in a space sharing manner; (2) resource partitioning on both CPUs and GPUs; and (3) power capping on both CPUs and GPUs. We solve this problem using predictive performance modeling using machine learning in order to coordinately optimize the above knob setups. Our experiential results using a real system show that our approach achieves up to 67% of speedup compared to a time-sharing-based scheduling with a naive power capping that evenly distributes power budgets across components.
5/8/2024
🔍
A 4D Hybrid Algorithm to Scale Parallel Training to Thousands of GPUs
Siddharth Singh, Prajwal Singhania, Aditya K. Ranjan, Zack Sating, Abhinav Bhatele
0
0
Heavy communication, in particular, collective operations, can become a critical performance bottleneck in scaling the training of billion-parameter neural networks to large-scale parallel systems. This paper introduces a four-dimensional (4D) approach to optimize communication in parallel training. This 4D approach is a hybrid of 3D tensor and data parallelism, and is implemented in the AxoNN framework. In addition, we employ two key strategies to further minimize communication overheads. First, we aggressively overlap expensive collective operations (reduce-scatter, all-gather, and all-reduce) with computation. Second, we develop an analytical model to identify high-performing configurations within the large search space defined by our 4D algorithm. This model empowers practitioners by simplifying the tuning process for their specific training workloads. When training an 80-billion parameter GPT on 1024 GPUs of Perlmutter, AxoNN surpasses Megatron-LM, a state-of-the-art framework, by a significant 26%. Additionally, it achieves a significantly high 57% of the theoretical peak FLOP/s or 182 PFLOP/s in total.
5/15/2024
🤿
Deep Learning Inference on Heterogeneous Mobile Processors: Potentials and Pitfalls
Sicong Liu, Wentao Zhou, Zimu Zhou, Bin Guo, Minfan Wang, Cheng Fang, Zheng Lin, Zhiwen Yu
0
0
There is a growing demand to deploy computation-intensive deep learning (DL) models on resource-constrained mobile devices for real-time intelligent applications. Equipped with a variety of processing units such as CPUs, GPUs, and NPUs, the mobile devices hold potential to accelerate DL inference via parallel execution across heterogeneous processors. Various efficient parallel methods have been explored to optimize computation distribution, achieve load balance, and minimize communication cost across processors. Yet their practical effectiveness in the dynamic and diverse real-world mobile environment is less explored. This paper presents a holistic empirical study to assess the capabilities and challenges associated with parallel DL inference on heterogeneous mobile processors. Through carefully designed experiments covering various DL models, mobile software/hardware environments, workload patterns, and resource availability, we identify limitations of existing techniques and highlight opportunities for cross-level optimization.
5/6/2024