fMRI predictors based on language models of increasing complexity recover brain left lateralization
2405.17992
0
0

Abstract
Over the past decade, studies of naturalistic language processing where participants are scanned while listening to continuous text have flourished. Using word embeddings at first, then large language models, researchers have created encoding models to analyze the brain signals. Presenting these models with the same text as the participants allows to identify brain areas where there is a significant correlation between the functional magnetic resonance imaging (fMRI) time series and the ones predicted by the models' artificial neurons. One intriguing finding from these studies is that they have revealed highly symmetric bilateral activation patterns, somewhat at odds with the well-known left lateralization of language processing. Here, we report analyses of an fMRI dataset where we manipulate the complexity of large language models, testing 28 pretrained models from 8 different families, ranging from 124M to 14.2B parameters. First, we observe that the performance of models in predicting brain responses follows a scaling law, where the fit with brain activity increases linearly with the logarithm of the number of parameters of the model (and its performance on natural language processing tasks). Second, we show that a left-right asymmetry gradually appears as model size increases, and that the difference in left-right brain correlations also follows a scaling law. Whereas the smallest models show no asymmetry, larger models fit better and better left hemispheric activations than right hemispheric ones. This finding reconciles computational analyses of brain activity using large language models with the classic observation from aphasic patients showing left hemisphere dominance for language.
Create account to get full access
Overview
- The paper investigates the ability of language models of increasing complexity to predict brain activity patterns associated with language processing.
- The researchers used functional magnetic resonance imaging (fMRI) data to examine how well different language models can recover the left-lateralized brain response to language.
- The study explores the relationship between the representations learned by large language models and the neural representations of language in the human brain.
Plain English Explanation
The researchers in this study wanted to understand how well different language models can predict the patterns of brain activity associated with processing language. They used a neuroimaging technique called functional magnetic resonance imaging (fMRI) to measure brain activity while people were reading or listening to language.
The researchers then tested how well different language models, from simple to more complex, could "predict" the patterns of brain activity they had observed. The idea was that if a language model could accurately predict the brain activity patterns, it would suggest that the model's representation of language is similar to how the brain represents language.
The key finding was that even simple language models were able to recover the well-known left-lateralization of language processing in the brain, meaning that language-related activity is mostly concentrated in the left side of the brain. This suggests that even basic language models capture some fundamental aspects of how the brain processes language.
By using language models of increasing complexity, the researchers were able to explore how the sophistication of the language model affects its ability to predict brain activity patterns. This provides insights into the relationship between the representations learned by large language models and the neural representations of language in the human brain.
Technical Explanation
The researchers used fMRI data collected from participants as they read and listened to language. They then tested how well different language models, ranging from a simple bag-of-words model to more complex contextual models like BERT and GPT-2, could predict the fMRI brain activity patterns.
The language models were used to generate predicted brain activity patterns, which were then compared to the actual fMRI data. The researchers found that even the simplest bag-of-words model was able to recover the well-known left-lateralization of language processing in the brain. As the complexity of the language models increased, their ability to predict brain activity patterns also improved.
The results suggest that language models, even relatively simple ones, are able to capture fundamental aspects of how the human brain represents and processes language. This provides insights into the relationship between the representations learned by large language models and the neural representations of language in the brain.
Critical Analysis
The paper provides a valuable contribution to our understanding of the relationship between language models and brain activity patterns. By using language models of increasing complexity, the researchers were able to explore how the sophistication of the model affects its ability to predict brain activity.
One potential limitation of the study is that it only examined language processing in a reading and listening context. It would be interesting to see how the language models perform in predicting brain activity patterns for other language-related tasks, such as language production or more complex language comprehension.
Additionally, the study focused on the left-lateralization of language processing, which is a well-established finding in the literature. It would be valuable to investigate how language models perform in predicting more nuanced and specific aspects of language-related brain activity patterns.
Overall, the research presented in this paper lays the groundwork for further exploration of the relationship between language models and the neural representations of language in the human brain. By continuing to investigate these connections, we may gain deeper insights into the nature of language processing and how it is implemented in the brain.
Conclusion
This study demonstrates that language models of increasing complexity are able to recover the well-known left-lateralization of language processing in the brain, as observed through fMRI data. This suggests that even relatively simple language models can capture fundamental aspects of how the human brain represents and processes language.
By exploring the relationship between language models and brain activity patterns, the researchers provide insights into the nature of the representations learned by large language models and how they relate to the neural representations of language in the brain. This has important implications for our understanding of language processing and the potential applications of language models in cognitive neuroscience and related fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Speech language models lack important brain-relevant semantics
Subba Reddy Oota, Emin c{C}elik, Fatma Deniz, Mariya Toneva
0
0
Despite known differences between reading and listening in the brain, recent work has shown that text-based language models predict both text-evoked and speech-evoked brain activity to an impressive degree. This poses the question of what types of information language models truly predict in the brain. We investigate this question via a direct approach, in which we systematically remove specific low-level stimulus features (textual, speech, and visual) from language model representations to assess their impact on alignment with fMRI brain recordings during reading and listening. Comparing these findings with speech-based language models reveals starkly different effects of low-level features on brain alignment. While text-based models show reduced alignment in early sensory regions post-removal, they retain significant predictive power in late language regions. In contrast, speech-based models maintain strong alignment in early auditory regions even after feature removal but lose all predictive power in late language regions. These results suggest that speech-based models provide insights into additional information processed by early auditory regions, but caution is needed when using them to model processing in late language regions. We make our code publicly available. [https://github.com/subbareddy248/speech-llm-brain]
6/18/2024
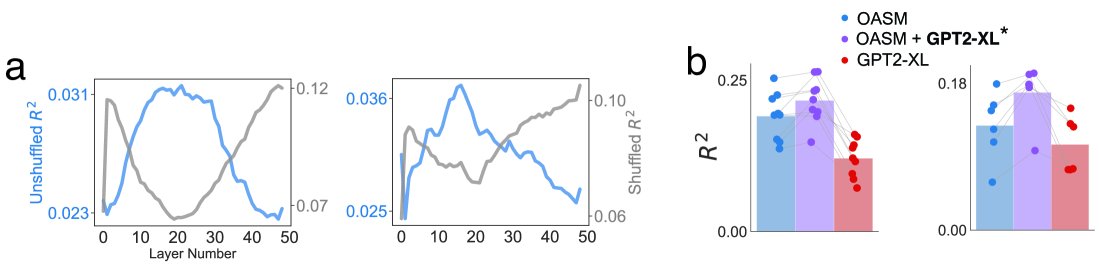
What Are Large Language Models Mapping to in the Brain? A Case Against Over-Reliance on Brain Scores
Ebrahim Feghhi, Nima Hadidi, Bryan Song, Idan A. Blank, Jonathan C. Kao
0
0
Given the remarkable capabilities of large language models (LLMs), there has been a growing interest in evaluating their similarity to the human brain. One approach towards quantifying this similarity is by measuring how well a model predicts neural signals, also called brain score. Internal representations from LLMs achieve state-of-the-art brain scores, leading to speculation that they share computational principles with human language processing. This inference is only valid if the subset of neural activity predicted by LLMs reflects core elements of language processing. Here, we question this assumption by analyzing three neural datasets used in an impactful study on LLM-to-brain mappings, with a particular focus on an fMRI dataset where participants read short passages. We first find that when using shuffled train-test splits, as done in previous studies with these datasets, a trivial feature that encodes temporal autocorrelation not only outperforms LLMs but also accounts for the majority of neural variance that LLMs explain. We therefore use contiguous splits moving forward. Second, we explain the surprisingly high brain scores of untrained LLMs by showing they do not account for additional neural variance beyond two simple features: sentence length and sentence position. This undermines evidence used to claim that the transformer architecture biases computations to be more brain-like. Third, we find that brain scores of trained LLMs on this dataset can largely be explained by sentence length, position, and pronoun-dereferenced static word embeddings; a small, additional amount is explained by sense-specific embeddings and contextual representations of sentence structure. We conclude that over-reliance on brain scores can lead to over-interpretations of similarity between LLMs and brains, and emphasize the importance of deconstructing what LLMs are mapping to in neural signals.
6/24/2024
Do Large Language Models Mirror Cognitive Language Processing?
Yuqi Ren, Renren Jin, Tongxuan Zhang, Deyi Xiong
0
0
Large Language Models (LLMs) have demonstrated remarkable abilities in text comprehension and logical reasoning, indicating that the text representations learned by LLMs can facilitate their language processing capabilities. In cognitive science, brain cognitive processing signals are typically utilized to study human language processing. Therefore, it is natural to ask how well the text embeddings from LLMs align with the brain cognitive processing signals, and how training strategies affect the LLM-brain alignment? In this paper, we employ Representational Similarity Analysis (RSA) to measure the alignment between 23 mainstream LLMs and fMRI signals of the brain to evaluate how effectively LLMs simulate cognitive language processing. We empirically investigate the impact of various factors (e.g., pre-training data size, model scaling, alignment training, and prompts) on such LLM-brain alignment. Experimental results indicate that pre-training data size and model scaling are positively correlated with LLM-brain similarity, and alignment training can significantly improve LLM-brain similarity. Explicit prompts contribute to the consistency of LLMs with brain cognitive language processing, while nonsensical noisy prompts may attenuate such alignment. Additionally, the performance of a wide range of LLM evaluations (e.g., MMLU, Chatbot Arena) is highly correlated with the LLM-brain similarity.
5/29/2024

Navigating Brain Language Representations: A Comparative Analysis of Neural Language Models and Psychologically Plausible Models
Yunhao Zhang, Shaonan Wang, Xinyi Dong, Jiajun Yu, Chengqing Zong
0
0
Neural language models, particularly large-scale ones, have been consistently proven to be most effective in predicting brain neural activity across a range of studies. However, previous research overlooked the comparison of these models with psychologically plausible ones. Moreover, evaluations were reliant on limited, single-modality, and English cognitive datasets. To address these questions, we conducted an analysis comparing encoding performance of various neural language models and psychologically plausible models. Our study utilized extensive multi-modal cognitive datasets, examining bilingual word and discourse levels. Surprisingly, our findings revealed that psychologically plausible models outperformed neural language models across diverse contexts, encompassing different modalities such as fMRI and eye-tracking, and spanning languages from English to Chinese. Among psychologically plausible models, the one incorporating embodied information emerged as particularly exceptional. This model demonstrated superior performance at both word and discourse levels, exhibiting robust prediction of brain activation across numerous regions in both English and Chinese.
5/1/2024