Do Large Language Models Mirror Cognitive Language Processing?
2402.18023
0
0
Abstract
Large Language Models (LLMs) have demonstrated remarkable abilities in text comprehension and logical reasoning, indicating that the text representations learned by LLMs can facilitate their language processing capabilities. In cognitive science, brain cognitive processing signals are typically utilized to study human language processing. Therefore, it is natural to ask how well the text embeddings from LLMs align with the brain cognitive processing signals, and how training strategies affect the LLM-brain alignment? In this paper, we employ Representational Similarity Analysis (RSA) to measure the alignment between 23 mainstream LLMs and fMRI signals of the brain to evaluate how effectively LLMs simulate cognitive language processing. We empirically investigate the impact of various factors (e.g., pre-training data size, model scaling, alignment training, and prompts) on such LLM-brain alignment. Experimental results indicate that pre-training data size and model scaling are positively correlated with LLM-brain similarity, and alignment training can significantly improve LLM-brain similarity. Explicit prompts contribute to the consistency of LLMs with brain cognitive language processing, while nonsensical noisy prompts may attenuate such alignment. Additionally, the performance of a wide range of LLM evaluations (e.g., MMLU, Chatbot Arena) is highly correlated with the LLM-brain similarity.
Create account to get full access
Overview
- This paper examines whether large language models (LLMs) like GPT-3 mirror the cognitive processes involved in human language understanding.
- The researchers conducted a series of experiments to compare the performance of LLMs on various language tasks to human cognitive abilities.
- The findings provide insights into the similarities and differences between artificial and human language processing.
Plain English Explanation
The paper investigates whether the way large language models (LLMs) like GPT-3 process and understand language is similar to how humans do it. LLMs are AI systems that can generate human-like text, but it's not clear if they truly "understand" language the way people do.
The researchers designed experiments to compare the performance of LLMs and humans on different language-related tasks. For example, they looked at how well the models and people could understand the meaning of sentences, recognize patterns in language, and draw inferences from text.
By analyzing the results, the researchers aimed to determine how closely LLMs mimic the cognitive processes involved in human language processing. This could help us understand the strengths and limitations of these AI systems compared to the human mind.
Technical Explanation
The paper examines the relationship between the language processing capabilities of large language models (LLMs) and human cognitive language processing. The researchers conducted a series of experiments to probe the similarities and differences between LLMs and human language understanding.
The experiments involved testing LLMs like GPT-3 on a variety of language tasks, such as understanding sentence meaning, recognizing linguistic patterns, and drawing inferences from text. The researchers then compared the performance of the LLMs to human participants on the same tasks.
The results suggest that while LLMs can achieve impressive performance on many language-related benchmarks, they do not fully mirror the cognitive processes underlying human language understanding. For example, the shape of the "brain scores" of LLMs - a measure of how well the model aligns with human brain activity - differs from the patterns observed in the human brain.
Additionally, the paper explores how LLMs handle multilingual language processing, an important aspect of human cognition that is not yet fully captured by current LLM architectures.
Critical Analysis
The paper provides a valuable contribution to the ongoing debate about the extent to which LLMs can truly be said to "understand" language in the same way humans do. While the results suggest that LLMs fall short of fully mirroring human cognitive language processing, the researchers acknowledge that there may be aspects of human language understanding that are not yet well-captured by the experimental paradigms employed.
One potential limitation of the study is the reliance on relatively narrow language tasks, which may not fully capture the breadth and flexibility of human language use. Additionally, the paper does not delve deeply into the architectural differences between LLMs and the human brain that may underlie the observed discrepancies in performance.
Further research is needed to more precisely characterize the relationship between LLMs and human cognition, particularly as these systems continue to grow in complexity and capability. Comparative studies that explore the strengths and weaknesses of both artificial and human language processing could help guide the development of more sophisticated and human-like AI language models.
Conclusion
This paper provides an in-depth examination of the relationship between large language models (LLMs) and human cognitive language processing. While the findings suggest that LLMs do not fully mirror the cognitive mechanisms underlying human language understanding, the research offers valuable insights into the similarities and differences between artificial and human language processing.
The results underscore the importance of continued research into the cognitive and neural underpinnings of language, as well as the development of more sophisticated AI language models that can better capture the richness and flexibility of human language use. As LLMs become increasingly advanced, understanding their relationship to human cognition will be crucial for ensuring that these systems are designed and deployed in a way that aligns with our own language abilities and needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
What Are Large Language Models Mapping to in the Brain? A Case Against Over-Reliance on Brain Scores
Ebrahim Feghhi, Nima Hadidi, Bryan Song, Idan A. Blank, Jonathan C. Kao
0
0
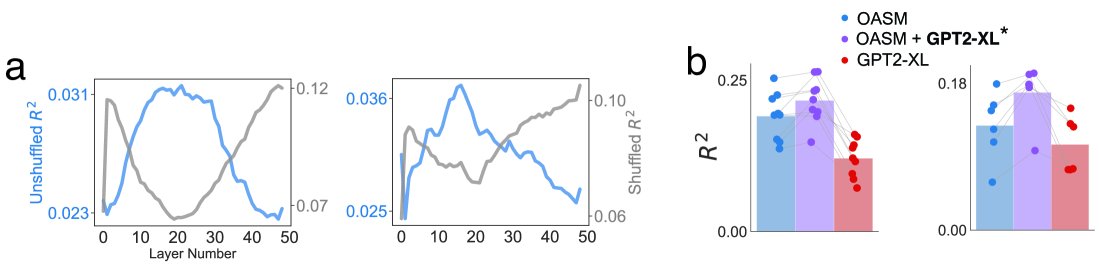
Given the remarkable capabilities of large language models (LLMs), there has been a growing interest in evaluating their similarity to the human brain. One approach towards quantifying this similarity is by measuring how well a model predicts neural signals, also called brain score. Internal representations from LLMs achieve state-of-the-art brain scores, leading to speculation that they share computational principles with human language processing. This inference is only valid if the subset of neural activity predicted by LLMs reflects core elements of language processing. Here, we question this assumption by analyzing three neural datasets used in an impactful study on LLM-to-brain mappings, with a particular focus on an fMRI dataset where participants read short passages. We first find that when using shuffled train-test splits, as done in previous studies with these datasets, a trivial feature that encodes temporal autocorrelation not only outperforms LLMs but also accounts for the majority of neural variance that LLMs explain. We therefore use contiguous splits moving forward. Second, we explain the surprisingly high brain scores of untrained LLMs by showing they do not account for additional neural variance beyond two simple features: sentence length and sentence position. This undermines evidence used to claim that the transformer architecture biases computations to be more brain-like. Third, we find that brain scores of trained LLMs on this dataset can largely be explained by sentence length, position, and pronoun-dereferenced static word embeddings; a small, additional amount is explained by sense-specific embeddings and contextual representations of sentence structure. We conclude that over-reliance on brain scores can lead to over-interpretations of similarity between LLMs and brains, and emphasize the importance of deconstructing what LLMs are mapping to in neural signals.
6/24/2024
💬
Do Language Models Exhibit the Same Cognitive Biases in Problem Solving as Human Learners?
Andreas Opedal, Alessandro Stolfo, Haruki Shirakami, Ying Jiao, Ryan Cotterell, Bernhard Scholkopf, Abulhair Saparov, Mrinmaya Sachan
0
0
There is increasing interest in employing large language models (LLMs) as cognitive models. For such purposes, it is central to understand which properties of human cognition are well-modeled by LLMs, and which are not. In this work, we study the biases of LLMs in relation to those known in children when solving arithmetic word problems. Surveying the learning science literature, we posit that the problem-solving process can be split into three distinct steps: text comprehension, solution planning and solution execution. We construct tests for each one in order to understand whether current LLMs display the same cognitive biases as children in these steps. We generate a novel set of word problems for each of these tests, using a neuro-symbolic approach that enables fine-grained control over the problem features. We find evidence that LLMs, with and without instruction-tuning, exhibit human-like biases in both the text-comprehension and the solution-planning steps of the solving process, but not in the final step, in which the arithmetic expressions are executed to obtain the answer.
6/18/2024
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, Martin Schrimpf
0
0
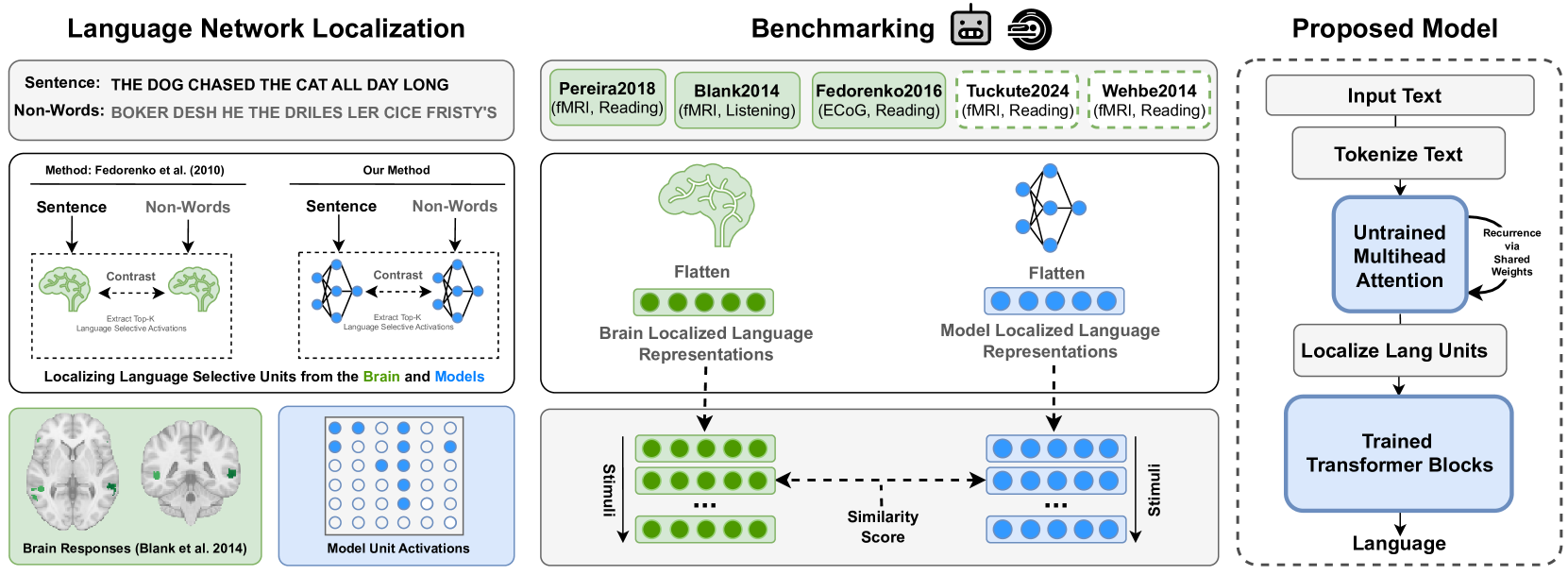
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
6/24/2024
💬
Aspects of human memory and Large Language Models
Romuald A. Janik
0
0
Large Language Models (LLMs) are huge artificial neural networks which primarily serve to generate text, but also provide a very sophisticated probabilistic model of language use. Since generating a semantically consistent text requires a form of effective memory, we investigate the memory properties of LLMs and find surprising similarities with key characteristics of human memory. We argue that the human-like memory properties of the Large Language Model do not follow automatically from the LLM architecture but are rather learned from the statistics of the training textual data. These results strongly suggest that the biological features of human memory leave an imprint on the way that we structure our textual narratives.
4/9/2024