FootBots: A Transformer-based Architecture for Motion Prediction in Soccer

0

Sign in to get full access
Overview
- The paper proposes a new Transformer-based architecture called "FootBots" for motion prediction in soccer.
- FootBots aims to accurately predict the future movements of players on a soccer field.
- The model uses a Transformer-based approach to capture the complex interactions and dependencies between players.
- Experiments on real-world soccer datasets demonstrate the effectiveness of the FootBots architecture compared to other state-of-the-art methods.
Plain English Explanation
The paper introduces a new model called "FootBots" that is designed to predict the future movements of players on a soccer field. Soccer is a complex sport with many players constantly moving and interacting with each other, which makes it challenging to accurately forecast their future positions.
The FootBots model uses a Transformer-based architecture, which is a type of neural network that has been successful at capturing the intricate relationships and dependencies between elements in data. By applying this Transformer-based approach to soccer player movement data, the FootBots model is able to better understand the complex dynamics on the field and make more accurate predictions about where players will move next.
The researchers tested the FootBots model on real-world soccer datasets and found that it outperformed other state-of-the-art methods for motion prediction. This suggests that the Transformer-based architecture is well-suited for this task and could have applications in areas like analyzing soccer matches, generating realistic player movements for simulations, and even assisting coaches and scouts in evaluating player performance.
Technical Explanation
The FootBots architecture proposed in the paper is based on the Transformer model, which has shown great success in a variety of sequential data tasks. The Transformer's ability to capture long-range dependencies and model complex interactions makes it well-suited for the soccer motion prediction problem.
The key components of the FootBots model include:
- Encoder: The encoder takes the current and past positions of all players on the field as input and generates a set of contextual representations for each player.
- Decoder: The decoder uses these contextual representations to predict the future positions of each player over a specified time horizon.
- Attention Mechanism: The Transformer's attention mechanism allows the model to focus on the most relevant players and interactions when making predictions.
The researchers trained and evaluated the FootBots model on several publicly available soccer datasets, including the Robust Human Motion Forecasting using Transformer-based Dataset and the Transfer Learning Study on Motion Transformer-based Trajectory Dataset. The results showed that FootBots outperformed other state-of-the-art motion prediction models, demonstrating the effectiveness of the Transformer-based architecture for this task.
Critical Analysis
The paper provides a strong technical foundation for the FootBots model and presents convincing experimental results. However, there are a few potential limitations and areas for further research that could be addressed:
-
Generalization to Diverse Gameplay: The experiments were conducted on a limited set of soccer datasets, which may not capture the full range of gameplay styles and strategies found in the real world. Further testing on more diverse datasets could help assess the model's ability to generalize to different soccer environments.
-
Interpretability and Explainability: As with many deep learning models, the inner workings of the FootBots Transformer can be difficult to interpret. Incorporating more explainable AI techniques could help provide insights into how the model is making its predictions and identify the key factors driving its performance.
-
Real-Time Deployment: For practical applications, such as in-game analysis or player scouting, the FootBots model would need to operate in real-time, which may require further optimization and engineering efforts.
-
Ethical Considerations: The use of advanced motion prediction models in sports could raise ethical concerns, such as privacy, fairness, and the potential for misuse. The authors could discuss these implications and how they might be addressed.
Conclusion
The FootBots paper presents a novel Transformer-based architecture for motion prediction in soccer, which has the potential to significantly improve our understanding and analysis of the sport. By accurately forecasting player movements, FootBots could aid in areas like tactical analysis, player evaluation, and the creation of more realistic soccer simulations.
While the initial results are promising, further research is needed to address the model's generalization, interpretability, and real-world deployment challenges. As the field of AI continues to advance, tools like FootBots could become increasingly valuable for coaches, analysts, and fans alike, enhancing our appreciation and understanding of the beautiful game of soccer.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FootBots: A Transformer-based Architecture for Motion Prediction in Soccer
Guillem Capellera, Luis Ferraz, Antonio Rubio, Antonio Agudo, Francesc Moreno-Noguer
Motion prediction in soccer involves capturing complex dynamics from player and ball interactions. We present FootBots, an encoder-decoder transformer-based architecture addressing motion prediction and conditioned motion prediction through equivariance properties. FootBots captures temporal and social dynamics using set attention blocks and multi-attention block decoder. Our evaluation utilizes two datasets: a real soccer dataset and a tailored synthetic one. Insights from the synthetic dataset highlight the effectiveness of FootBots' social attention mechanism and the significance of conditioned motion prediction. Empirical results on real soccer data demonstrate that FootBots outperforms baselines in motion prediction and excels in conditioned tasks, such as predicting the players based on the ball position, predicting the offensive (defensive) team based on the ball and the defensive (offensive) team, and predicting the ball position based on all players. Our evaluation connects quantitative and qualitative findings. https://youtu.be/9kaEkfzG3L8
Read more7/1/2024

0
A Foundation Model for Soccer
Ethan Baron, Daniel Hocevar, Zach Salehe
We propose a foundation model for soccer, which is able to predict subsequent actions in a soccer match from a given input sequence of actions. As a proof of concept, we train a transformer architecture on three seasons of data from a professional soccer league. We quantitatively and qualitatively compare the performance of this transformer architecture to two baseline models: a Markov model and a multi-layer perceptron. Additionally, we discuss potential applications of our model. We provide an open-source implementation of our methods at https://github.com/danielhocevar/Foundation-Model-for-Soccer.
Read more7/23/2024
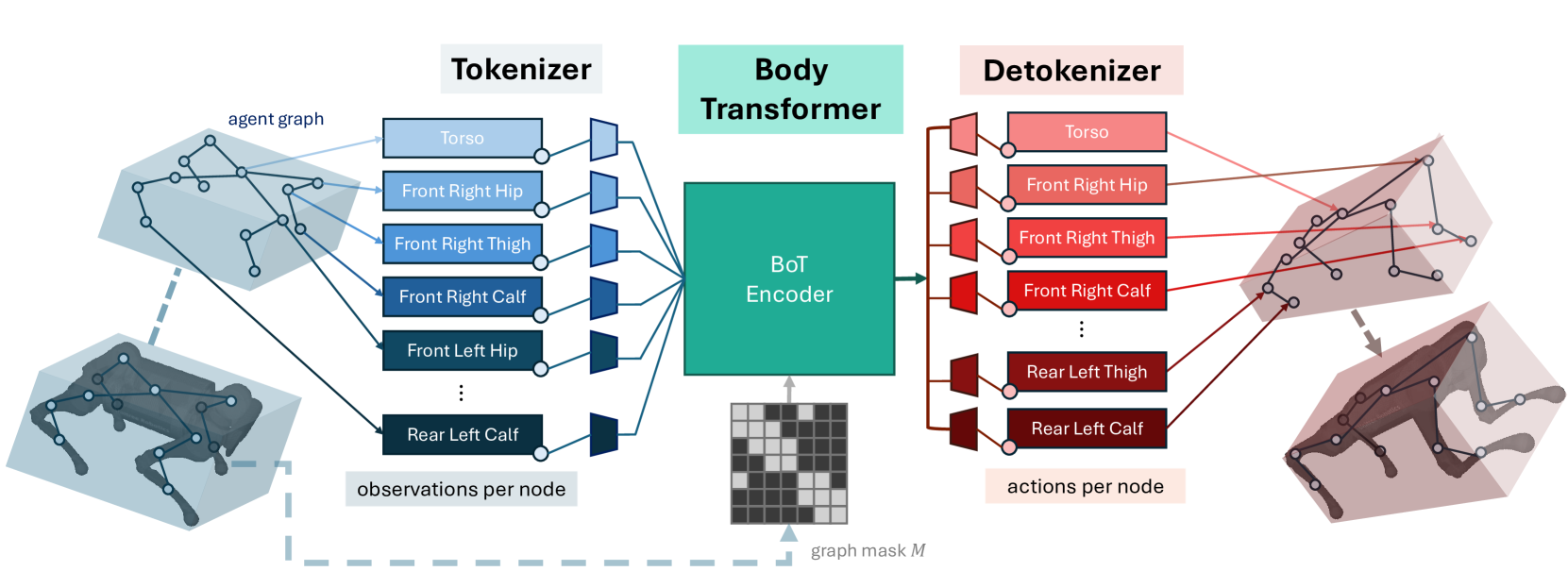
0
Body Transformer: Leveraging Robot Embodiment for Policy Learning
Carmelo Sferrazza, Dun-Ming Huang, Fangchen Liu, Jongmin Lee, Pieter Abbeel
In recent years, the transformer architecture has become the de facto standard for machine learning algorithms applied to natural language processing and computer vision. Despite notable evidence of successful deployment of this architecture in the context of robot learning, we claim that vanilla transformers do not fully exploit the structure of the robot learning problem. Therefore, we propose Body Transformer (BoT), an architecture that leverages the robot embodiment by providing an inductive bias that guides the learning process. We represent the robot body as a graph of sensors and actuators, and rely on masked attention to pool information throughout the architecture. The resulting architecture outperforms the vanilla transformer, as well as the classical multilayer perceptron, in terms of task completion, scaling properties, and computational efficiency when representing either imitation or reinforcement learning policies. Additional material including the open-source code is available at https://sferrazza.cc/bot_site.
Read more8/13/2024
🛸
0
Robot Interaction Behavior Generation based on Social Motion Forecasting for Human-Robot Interaction
Esteve Valls Mascaro, Yashuai Yan, Dongheui Lee
Integrating robots into populated environments is a complex challenge that requires an understanding of human social dynamics. In this work, we propose to model social motion forecasting in a shared human-robot representation space, which facilitates us to synthesize robot motions that interact with humans in social scenarios despite not observing any robot in the motion training. We develop a transformer-based architecture called ECHO, which operates in the aforementioned shared space to predict the future motions of the agents encountered in social scenarios. Contrary to prior works, we reformulate the social motion problem as the refinement of the predicted individual motions based on the surrounding agents, which facilitates the training while allowing for single-motion forecasting when only one human is in the scene. We evaluate our model in multi-person and human-robot motion forecasting tasks and obtain state-of-the-art performance by a large margin while being efficient and performing in real-time. Additionally, our qualitative results showcase the effectiveness of our approach in generating human-robot interaction behaviors that can be controlled via text commands. Webpage: https://evm7.github.io/ECHO/
Read more4/9/2024