FORESEE: Multimodal and Multi-view Representation Learning for Robust Prediction of Cancer Survival
2405.07702
0
0
🔮
Abstract
Integrating the different data modalities of cancer patients can significantly improve the predictive performance of patient survival. However, most existing methods ignore the simultaneous utilization of rich semantic features at different scales in pathology images. When collecting multimodal data and extracting features, there is a likelihood of encountering intra-modality missing data, introducing noise into the multimodal data. To address these challenges, this paper proposes a new end-to-end framework, FORESEE, for robustly predicting patient survival by mining multimodal information. Specifically, the cross-fusion transformer effectively utilizes features at the cellular level, tissue level, and tumor heterogeneity level to correlate prognosis through a cross-scale feature cross-fusion method. This enhances the ability of pathological image feature representation. Secondly, the hybrid attention encoder (HAE) uses the denoising contextual attention module to obtain the contextual relationship features and local detail features of the molecular data. HAE's channel attention module obtains global features of molecular data. Furthermore, to address the issue of missing information within modalities, we propose an asymmetrically masked triplet masked autoencoder to reconstruct lost information within modalities. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods on four benchmark datasets in both complete and missing settings.
Create account to get full access
Overview
- The paper proposes a new framework called FORESEE for predicting cancer patient survival using multimodal data, including pathology images and molecular data.
- The key innovations are:
- A cross-fusion transformer that extracts features at different scales in pathology images to better represent tumor heterogeneity.
- A hybrid attention encoder that uses denoising contextual attention and channel attention to obtain both local and global features from molecular data.
- An asymmetrically masked triplet masked autoencoder to address missing data within modalities.
Plain English Explanation
When treating cancer patients, doctors can use a variety of data sources to try to predict how long a patient might survive. This includes information from pathology images, which show details of the tumor, as well as molecular data, which provides information about the genetic makeup of the cancer. Integrating the different data modalities of cancer patients can significantly improve the predictive performance of patient survival.
However, existing methods often struggle to fully leverage all the information available in these different data sources. This paper proposes a new approach called FORESEE that aims to address this challenge. The key idea is to extract features from the pathology images at multiple scales - from the cellular level, to the tissue level, to the overall tumor heterogeneity. This cross-scale feature cross-fusion allows the model to get a richer understanding of the tumor.
For the molecular data, the model uses a "hybrid attention encoder" to capture both local details and global patterns in the data. This helps the model learn meaningful relationships between the genetic markers and the patient's prognosis.
One challenge with multimodal data is that sometimes information is missing from one or more of the data sources. To address this, the FORESEE framework uses a specialized autoencoder to reconstruct the missing information, rather than just ignoring the incomplete data.
Overall, this framework demonstrates how carefully integrating diverse data sources, while addressing challenges like missing information, can lead to significantly improved predictions of cancer patient survival.
Technical Explanation
The proposed FORESEE framework consists of three key components:
-
Cross-Fusion Transformer: This module extracts features from pathology images at multiple scales, including the cellular level, tissue level, and overall tumor heterogeneity. It uses a cross-scale feature cross-fusion method to effectively integrate these multi-scale representations and enhance the pathological image feature extraction.
-
Hybrid Attention Encoder (HAE): The HAE module processes the molecular data, using a denoising contextual attention mechanism to capture local details and relationships. It also employs a channel attention module to extract global features from the molecular data.
-
Asymmetrically Masked Triplet Masked Autoencoder: To handle missing data within the modalities, this component uses a specialized autoencoder architecture to reconstruct the lost information. It employs an asymmetric masking strategy to better model the missing patterns.
The authors conduct extensive experiments on four benchmark datasets, evaluating the framework's performance in both complete and missing data settings. The results demonstrate the superiority of FORESEE over state-of-the-art methods for predicting cancer patient survival using multimodal data.
Critical Analysis
The paper presents a comprehensive approach to integrating multimodal data for cancer prognosis, addressing several key challenges in this domain. The cross-scale feature fusion and the hybrid attention mechanism for molecular data are novel and well-justified strategies.
However, the paper could have provided more details on the specific architectures and hyperparameters used for the various components of the FORESEE framework. Additionally, while the experiments demonstrate the framework's effectiveness, the authors could have explored the model's generalizability by evaluating it on a broader range of cancer types or datasets.
Furthermore, the paper does not delve into the clinical interpretability of the model's predictions. Understanding the specific features or biomarkers that drive the survival predictions could be valuable for guiding treatment decisions and further research.
Overall, the FORESEE framework represents a promising approach to multimodal data integration in the oncology domain, and the authors have made a significant contribution to the field. However, there are opportunities for further refinement and exploration of the model's clinical implications.
Conclusion
This paper presents a novel framework called FORESEE for predicting cancer patient survival using multimodal data, including pathology images and molecular information. The key innovations are a cross-fusion transformer to extract multi-scale features from the images, a hybrid attention encoder to process the molecular data, and an autoencoder-based approach to handle missing information within the modalities.
The extensive experiments demonstrate the effectiveness of this framework, which outperforms state-of-the-art methods on benchmark datasets. This work highlights the importance of carefully integrating diverse data sources and addressing challenging issues like missing data to improve the predictive performance of medical models. The insights from this research could help advance the field of multimodal cancer survival prediction and potentially lead to more personalized and effective cancer treatment strategies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Embedding-based Multimodal Learning on Pan-Squamous Cell Carcinomas for Improved Survival Outcomes
Asim Waqas, Aakash Tripathi, Paul Stewart, Mia Naeini, Ghulam Rasool
0
0
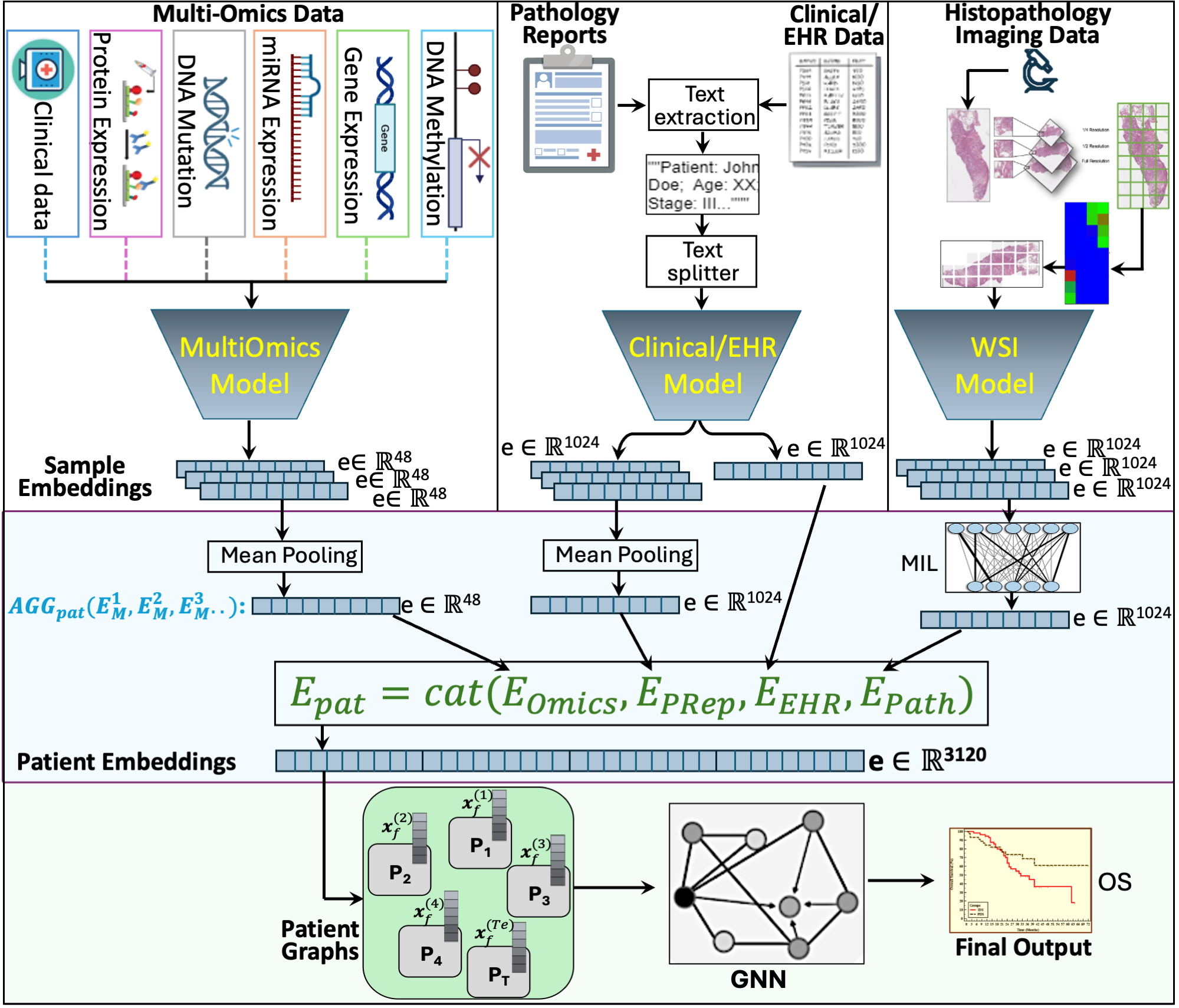
Cancer clinics capture disease data at various scales, from genetic to organ level. Current bioinformatic methods struggle to handle the heterogeneous nature of this data, especially with missing modalities. We propose PARADIGM, a Graph Neural Network (GNN) framework that learns from multimodal, heterogeneous datasets to improve clinical outcome prediction. PARADIGM generates embeddings from multi-resolution data using foundation models, aggregates them into patient-level representations, fuses them into a unified graph, and enhances performance for tasks like survival analysis. We train GNNs on pan-Squamous Cell Carcinomas and validate our approach on Moffitt Cancer Center lung SCC data. Multimodal GNN outperforms other models in patient survival prediction. Converging individual data modalities across varying scales provides a more insightful disease view. Our solution aims to understand the patient's circumstances comprehensively, offering insights on heterogeneous data integration and the benefits of converging maximum data views.
6/14/2024
MoME: Mixture of Multimodal Experts for Cancer Survival Prediction
Conghao Xiong, Hao Chen, Hao Zheng, Dong Wei, Yefeng Zheng, Joseph J. Y. Sung, Irwin King
0
0
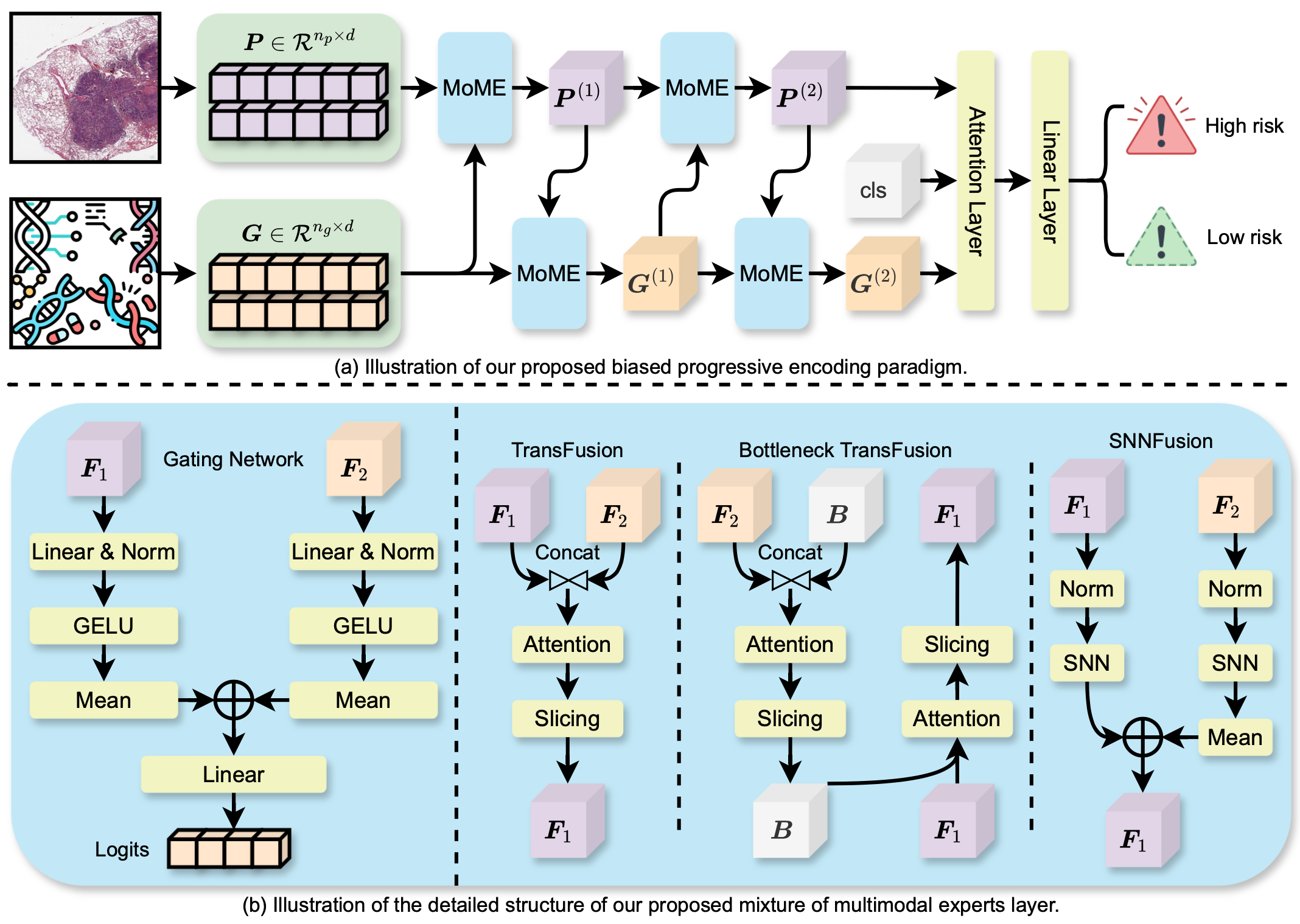
Survival analysis, as a challenging task, requires integrating Whole Slide Images (WSIs) and genomic data for comprehensive decision-making. There are two main challenges in this task: significant heterogeneity and complex inter- and intra-modal interactions between the two modalities. Previous approaches utilize co-attention methods, which fuse features from both modalities only once after separate encoding. However, these approaches are insufficient for modeling the complex task due to the heterogeneous nature between the modalities. To address these issues, we propose a Biased Progressive Encoding (BPE) paradigm, performing encoding and fusion simultaneously. This paradigm uses one modality as a reference when encoding the other. It enables deep fusion of the modalities through multiple alternating iterations, progressively reducing the cross-modal disparities and facilitating complementary interactions. Besides modality heterogeneity, survival analysis involves various biomarkers from WSIs, genomics, and their combinations. The critical biomarkers may exist in different modalities under individual variations, necessitating flexible adaptation of the models to specific scenarios. Therefore, we further propose a Mixture of Multimodal Experts (MoME) layer to dynamically selects tailored experts in each stage of the BPE paradigm. Experts incorporate reference information from another modality to varying degrees, enabling a balanced or biased focus on different modalities during the encoding process. Extensive experimental results demonstrate the superior performance of our method on various datasets, including TCGA-BLCA, TCGA-UCEC and TCGA-LUAD. Codes are available at https://github.com/BearCleverProud/MoME.
6/17/2024
🤿
Comprehensive Multimodal Deep Learning Survival Prediction Enabled by a Transformer Architecture: A Multicenter Study in Glioblastoma
Ahmed Gomaa, Yixing Huang, Amr Hagag, Charlotte Schmitter, Daniel Hofler, Thomas Weissmann, Katharina Breininger, Manuel Schmidt, Jenny Stritzelberger, Daniel Delev, Roland Coras, Arnd Dorfler, Oliver Schnell, Benjamin Frey, Udo S. Gaipl, Sabine Semrau, Christoph Bert, Rainer Fietkau, Florian Putz
0
0
Background: This research aims to improve glioblastoma survival prediction by integrating MR images, clinical and molecular-pathologic data in a transformer-based deep learning model, addressing data heterogeneity and performance generalizability. Method: We propose and evaluate a transformer-based non-linear and non-proportional survival prediction model. The model employs self-supervised learning techniques to effectively encode the high-dimensional MRI input for integration with non-imaging data using cross-attention. To demonstrate model generalizability, the model is assessed with the time-dependent concordance index (Cdt) in two training setups using three independent public test sets: UPenn-GBM, UCSF-PDGM, and RHUH-GBM, each comprising 378, 366, and 36 cases, respectively. Results: The proposed transformer model achieved promising performance for imaging as well as non-imaging data, effectively integrating both modalities for enhanced performance (UPenn-GBM test-set, imaging Cdt 0.645, multimodal Cdt 0.707) while outperforming state-of-the-art late-fusion 3D-CNN-based models. Consistent performance was observed across the three independent multicenter test sets with Cdt values of 0.707 (UPenn-GBM, internal test set), 0.672 (UCSF-PDGM, first external test set) and 0.618 (RHUH-GBM, second external test set). The model achieved significant discrimination between patients with favorable and unfavorable survival for all three datasets (logrank p 1.9times{10}^{-8}, 9.7times{10}^{-3}, and 1.2times{10}^{-2}). Conclusions: The proposed transformer-based survival prediction model integrates complementary information from diverse input modalities, contributing to improved glioblastoma survival prediction compared to state-of-the-art methods. Consistent performance was observed across institutions supporting model generalizability.
5/22/2024
🤿
BioFusionNet: Deep Learning-Based Survival Risk Stratification in ER+ Breast Cancer Through Multifeature and Multimodal Data Fusion
Raktim Kumar Mondol, Ewan K. A. Millar, Arcot Sowmya, Erik Meijering
0
0
Breast cancer is a significant health concern affecting millions of women worldwide. Accurate survival risk stratification plays a crucial role in guiding personalised treatment decisions and improving patient outcomes. Here we present BioFusionNet, a deep learning framework that fuses image-derived features with genetic and clinical data to obtain a holistic profile and achieve survival risk stratification of ER+ breast cancer patients. We employ multiple self-supervised feature extractors (DINO and MoCoV3) pretrained on histopathological patches to capture detailed image features. These features are then fused by a variational autoencoder and fed to a self-attention network generating patient-level features. A co-dual-cross-attention mechanism combines the histopathological features with genetic data, enabling the model to capture the interplay between them. Additionally, clinical data is incorporated using a feed-forward network, further enhancing predictive performance and achieving comprehensive multimodal feature integration. Furthermore, we introduce a weighted Cox loss function, specifically designed to handle imbalanced survival data, which is a common challenge. Our model achieves a mean concordance index of 0.77 and a time-dependent area under the curve of 0.84, outperforming state-of-the-art methods. It predicts risk (high versus low) with prognostic significance for overall survival in univariate analysis (HR=2.99, 95% CI: 1.88--4.78, p<0.005), and maintains independent significance in multivariate analysis incorporating standard clinicopathological variables (HR=2.91, 95% CI: 1.80--4.68, p<0.005).
6/4/2024