MoME: Mixture of Multimodal Experts for Cancer Survival Prediction
2406.09696
0
0
Abstract
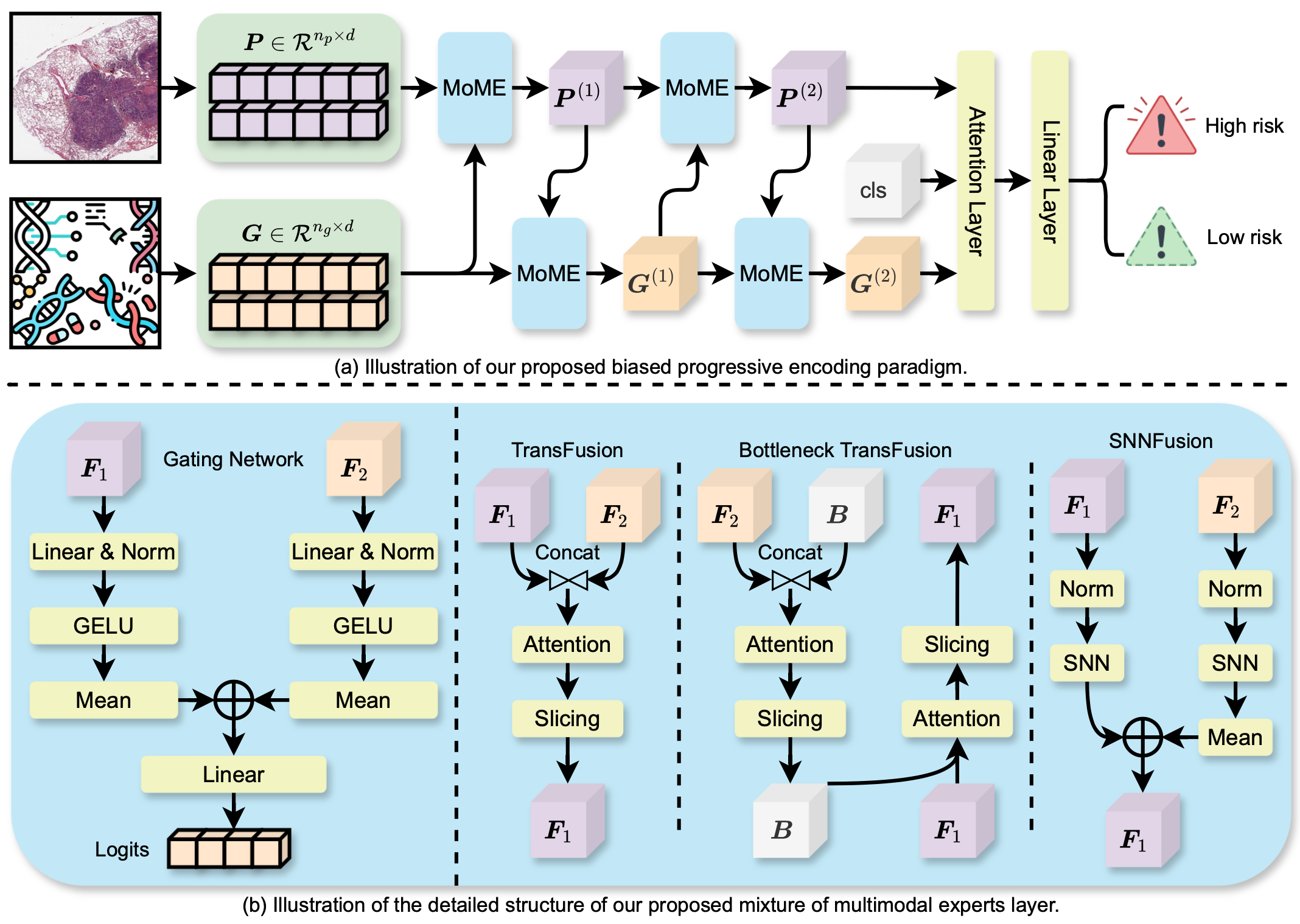
Survival analysis, as a challenging task, requires integrating Whole Slide Images (WSIs) and genomic data for comprehensive decision-making. There are two main challenges in this task: significant heterogeneity and complex inter- and intra-modal interactions between the two modalities. Previous approaches utilize co-attention methods, which fuse features from both modalities only once after separate encoding. However, these approaches are insufficient for modeling the complex task due to the heterogeneous nature between the modalities. To address these issues, we propose a Biased Progressive Encoding (BPE) paradigm, performing encoding and fusion simultaneously. This paradigm uses one modality as a reference when encoding the other. It enables deep fusion of the modalities through multiple alternating iterations, progressively reducing the cross-modal disparities and facilitating complementary interactions. Besides modality heterogeneity, survival analysis involves various biomarkers from WSIs, genomics, and their combinations. The critical biomarkers may exist in different modalities under individual variations, necessitating flexible adaptation of the models to specific scenarios. Therefore, we further propose a Mixture of Multimodal Experts (MoME) layer to dynamically selects tailored experts in each stage of the BPE paradigm. Experts incorporate reference information from another modality to varying degrees, enabling a balanced or biased focus on different modalities during the encoding process. Extensive experimental results demonstrate the superior performance of our method on various datasets, including TCGA-BLCA, TCGA-UCEC and TCGA-LUAD. Codes are available at https://github.com/BearCleverProud/MoME.
Create account to get full access
Overview
- This paper proposes a novel multimodal deep learning model called MoME (Mixture of Multimodal Experts) for predicting cancer survival outcomes.
- MoME leverages multiple modalities, such as clinical data, pathology images, and genomic data, to improve the accuracy of survival prediction.
- The model employs a mixture-of-experts architecture, where each expert is responsible for a specific modality, and a gating network dynamically combines the experts' outputs.
Plain English Explanation
MoME is a machine learning model that aims to predict how long a cancer patient will survive. It does this by using different types of data about the patient, such as their medical history, images of their tumor, and genetic information.
The key idea behind MoME is that it has separate "expert" models, each of which focuses on a specific type of data. For example, one expert might specialize in analyzing the medical history, while another focuses on the pathology images. A "gating" system then combines the outputs of these experts to make the final survival prediction.
This approach is designed to take advantage of the strengths of each data type, rather than relying on a single type of data. By using a mixture of experts, the model can learn to weigh the different types of information in the most effective way for each individual patient.
The researchers who developed MoME believe that this multimodal approach can lead to more accurate and personalized cancer survival predictions, which could ultimately help doctors provide better care for their patients.
Technical Explanation
The MoME architecture ^1 consists of several key components:
-
Modality-specific Experts: MoME has a set of expert networks, each of which is responsible for processing a specific data modality, such as clinical data, pathology images, or genomic information.
-
Gating Network: A gating network dynamically combines the outputs of the expert networks based on the input data. This allows MoME to adaptively weigh the different modalities for each patient, rather than using a fixed combination.
-
Multimodal Fusion: The gating network fuses the outputs of the expert networks using a weighted sum, where the weights are determined by the gating network.
-
Training: MoME is trained end-to-end using a combination of supervised and unsupervised learning techniques. The expert networks are trained on their respective modalities, while the gating network is trained to optimize the overall survival prediction performance.
The researchers evaluated MoME on several cancer survival prediction datasets, ^2, ^3, ^4 and found that it outperformed both unimodal and other multimodal approaches. The mixture-of-experts architecture allowed MoME to effectively leverage the complementary information in the different data modalities, leading to more accurate survival predictions.
Critical Analysis
The researchers acknowledge several limitations of their work:
- The model's performance may be sensitive to the quality and availability of the input data across modalities. In real-world settings, data may be incomplete or unbalanced across modalities.
- The interpretability of the gating network's decisions is not fully explored. Understanding how the model weighs the different modalities could provide valuable insights for clinicians.
- The study was conducted on a relatively small number of datasets, and further validation on larger, more diverse cohorts would be beneficial to establish the model's generalizability.
Additionally, the paper does not discuss potential ethical considerations, such as the impact of bias in the data or the responsible deployment of such a model in clinical practice. These are important aspects that should be addressed in future work.
Conclusion
The MoME model proposed in this paper represents a promising approach to leveraging multimodal data for improved cancer survival prediction. By combining multiple experts, each focused on a specific data modality, and using a dynamic gating mechanism to fuse their outputs, MoME demonstrates superior performance compared to existing methods.
This research highlights the potential of multimodal learning techniques to enhance clinical decision-making and personalized cancer care. As the availability and integration of diverse biomedical data continue to grow, models like MoME could play a crucial role in translating these rich data sources into actionable insights for clinicians and patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multimodal Cross-Task Interaction for Survival Analysis in Whole Slide Pathological Images
Songhan Jiang, Zhengyu Gan, Linghan Cai, Yifeng Wang, Yongbing Zhang
0
0
Survival prediction, utilizing pathological images and genomic profiles, is increasingly important in cancer analysis and prognosis. Despite significant progress, precise survival analysis still faces two main challenges: (1) The massive pixels contained in whole slide images (WSIs) complicate the process of pathological images, making it difficult to generate an effective representation of the tumor microenvironment (TME). (2) Existing multimodal methods often rely on alignment strategies to integrate complementary information, which may lead to information loss due to the inherent heterogeneity between pathology and genes. In this paper, we propose a Multimodal Cross-Task Interaction (MCTI) framework to explore the intrinsic correlations between subtype classification and survival analysis tasks. Specifically, to capture TME-related features in WSIs, we leverage the subtype classification task to mine tumor regions. Simultaneously, multi-head attention mechanisms are applied in genomic feature extraction, adaptively performing genes grouping to obtain task-related genomic embedding. With the joint representation of pathological images and genomic data, we further introduce a Transport-Guided Attention (TGA) module that uses optimal transport theory to model the correlation between subtype classification and survival analysis tasks, effectively transferring potential information. Extensive experiments demonstrate the superiority of our approaches, with MCTI outperforming state-of-the-art frameworks on three public benchmarks. href{https://github.com/jsh0792/MCTI}{https://github.com/jsh0792/MCTI}.
6/26/2024
🔮
FORESEE: Multimodal and Multi-view Representation Learning for Robust Prediction of Cancer Survival
Liangrui Pan, Yijun Peng, Yan Li, Yiyi Liang, Liwen Xu, Qingchun Liang, Shaoliang Peng
0
0
Integrating the different data modalities of cancer patients can significantly improve the predictive performance of patient survival. However, most existing methods ignore the simultaneous utilization of rich semantic features at different scales in pathology images. When collecting multimodal data and extracting features, there is a likelihood of encountering intra-modality missing data, introducing noise into the multimodal data. To address these challenges, this paper proposes a new end-to-end framework, FORESEE, for robustly predicting patient survival by mining multimodal information. Specifically, the cross-fusion transformer effectively utilizes features at the cellular level, tissue level, and tumor heterogeneity level to correlate prognosis through a cross-scale feature cross-fusion method. This enhances the ability of pathological image feature representation. Secondly, the hybrid attention encoder (HAE) uses the denoising contextual attention module to obtain the contextual relationship features and local detail features of the molecular data. HAE's channel attention module obtains global features of molecular data. Furthermore, to address the issue of missing information within modalities, we propose an asymmetrically masked triplet masked autoencoder to reconstruct lost information within modalities. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods on four benchmark datasets in both complete and missing settings.
5/14/2024

Cohort-Individual Cooperative Learning for Multimodal Cancer Survival Analysis
Huajun Zhou, Fengtao Zhou, Hao Chen
0
0
Recently, we have witnessed impressive achievements in cancer survival analysis by integrating multimodal data, e.g., pathology images and genomic profiles. However, the heterogeneity and high dimensionality of these modalities pose significant challenges for extracting discriminative representations while maintaining good generalization. In this paper, we propose a Cohort-individual Cooperative Learning (CCL) framework to advance cancer survival analysis by collaborating knowledge decomposition and cohort guidance. Specifically, first, we propose a Multimodal Knowledge Decomposition (MKD) module to explicitly decompose multimodal knowledge into four distinct components: redundancy, synergy and uniqueness of the two modalities. Such a comprehensive decomposition can enlighten the models to perceive easily overlooked yet important information, facilitating an effective multimodal fusion. Second, we propose a Cohort Guidance Modeling (CGM) to mitigate the risk of overfitting task-irrelevant information. It can promote a more comprehensive and robust understanding of the underlying multimodal data, while avoiding the pitfalls of overfitting and enhancing the generalization ability of the model. By cooperating the knowledge decomposition and cohort guidance methods, we develop a robust multimodal survival analysis model with enhanced discrimination and generalization abilities. Extensive experimental results on five cancer datasets demonstrate the effectiveness of our model in integrating multimodal data for survival analysis.
4/4/2024

Pathology-genomic fusion via biologically informed cross-modality graph learning for survival analysis
Zeyu Zhang, Yuanshen Zhao, Jingxian Duan, Yaou Liu, Hairong Zheng, Dong Liang, Zhenyu Zhang, Zhi-Cheng Li
0
0
The diagnosis and prognosis of cancer are typically based on multi-modal clinical data, including histology images and genomic data, due to the complex pathogenesis and high heterogeneity. Despite the advancements in digital pathology and high-throughput genome sequencing, establishing effective multi-modal fusion models for survival prediction and revealing the potential association between histopathology and transcriptomics remains challenging. In this paper, we propose Pathology-Genome Heterogeneous Graph (PGHG) that integrates whole slide images (WSI) and bulk RNA-Seq expression data with heterogeneous graph neural network for cancer survival analysis. The PGHG consists of biological knowledge-guided representation learning network and pathology-genome heterogeneous graph. The representation learning network utilizes the biological prior knowledge of intra-modal and inter-modal data associations to guide the feature extraction. The node features of each modality are updated through attention-based graph learning strategy. Unimodal features and bi-modal fused features are extracted via attention pooling module and then used for survival prediction. We evaluate the model on low-grade gliomas, glioblastoma, and kidney renal papillary cell carcinoma datasets from the Cancer Genome Atlas (TCGA) and the First Affiliated Hospital of Zhengzhou University (FAHZU). Extensive experimental results demonstrate that the proposed method outperforms both unimodal and other multi-modal fusion models. For demonstrating the model interpretability, we also visualize the attention heatmap of pathological images and utilize integrated gradient algorithm to identify important tissue structure, biological pathways and key genes.
4/15/2024