Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization
2406.16008
0
0

Abstract
Large language models (LLMs), even when specifically trained to process long input contexts, struggle to capture relevant information located in the middle of their input. This phenomenon has been known as the lost-in-the-middle problem. In this work, we make three contributions. First, we set out to understand the factors that cause this phenomenon. In doing so, we establish a connection between lost-in-the-middle to LLMs' intrinsic attention bias: LLMs exhibit a U-shaped attention bias where the tokens at the beginning and at the end of its input receive higher attention, regardless of their relevance. Second, we mitigate this positional bias through a calibration mechanism, found-in-the-middle, that allows the model to attend to contexts faithfully according to their relevance, even though when they are in the middle. Third, we show found-in-the-middle not only achieves better performance in locating relevant information within a long context, but also eventually leads to improved retrieval-augmented generation (RAG) performance across various tasks, outperforming existing methods by up to 15 percentage points. These findings open up future directions in understanding LLM attention bias and its potential consequences.
Create account to get full access
Overview
- The paper examines how positional attention bias in large language models can limit their ability to fully utilize long context information.
- It proposes a method called "Calibrated Positional Attention" to mitigate this bias and improve long-context understanding.
- The approach involves adjusting the attention weights assigned to different positions in the input sequence to better balance the importance of middle and end positions.
Plain English Explanation
Large language models like those used in GPT-3 are powerful tools for processing and understanding natural language. However, they can sometimes struggle to make full use of all the information available in long input sequences. This is partly because the models have an inherent "positional attention bias" - they tend to pay more attention to the beginning and end of a sequence, while the middle parts get relatively less focus.
The researchers behind this paper discovered that this bias towards the start and end of a sequence can prevent the models from properly incorporating important information that may be found in the middle of the input. To address this, they developed a technique called "Calibrated Positional Attention" that adjusts the attention weights to better balance the importance given to different positions in the sequence.
By calibrating the positional attention, the models are able to more effectively leverage the full context provided in long inputs. This can lead to performance improvements on tasks that require deep understanding of the entire sequence, such as summarization or question answering.
In essence, the key insight is that simply letting the model decide how much attention to pay to different parts of the input is not always optimal. By actively mitigating the positional bias, the researchers were able to help the model make better use of the full context and improve its overall performance.
Technical Explanation
The paper begins by demonstrating how positional attention bias can limit large language models' ability to fully utilize long input sequences. Through controlled experiments, the authors show that models tend to focus disproportionately on the beginning and end of a sequence, while the middle parts receive relatively less attention.
To address this issue, the researchers introduce "Calibrated Positional Attention", a method that adjusts the attention weights assigned to different positions in the input. Specifically, they apply a learned positional bias function that increases the attention given to middle positions and decreases the attention given to start and end positions.
This calibration is implemented as an additional learnable parameter in the attention mechanism, which can be trained end-to-end along with the rest of the model. The authors show that this approach leads to consistent performance improvements on a variety of long-context tasks, including text summarization and question answering.
Importantly, the Calibrated Positional Attention method is designed to be efficient and applicable to different model architectures. It does not require any changes to the core model structure or add significant computational overhead, making it a practical solution for improving long-context understanding in large language models.
Critical Analysis
The paper provides a thoughtful analysis of an important issue in large language models - their tendency to prioritize information at the beginning and end of sequences over the middle. The authors' proposed solution of Calibrated Positional Attention is a clever and effective approach to mitigate this bias.
One potential limitation of the work is that it focuses primarily on evaluating the method on text-based tasks. While the authors demonstrate its effectiveness on summarization and question answering, it would be valuable to explore how the technique performs on other modalities, such as vision-language models or models that process multi-modal inputs.
Additionally, the paper does not delve deeply into the reasons behind the positional attention bias in the first place. Further research into the underlying mechanisms and architectural factors that contribute to this bias could lead to even more targeted solutions.
That said, the Calibrated Positional Attention method represents a significant step forward in improving the ability of large language models to fully utilize long context. As models continue to grow in scale and complexity, addressing issues like this will be crucial for unlocking their full potential.
Conclusion
This paper identifies and tackles an important limitation of large language models - their tendency to prioritize information at the beginning and end of sequences over the middle. By introducing a technique called Calibrated Positional Attention, the researchers were able to mitigate this bias and help the models make better use of the full context provided in long input sequences.
The proposed approach is efficient, effective, and applicable to a variety of model architectures, making it a practical solution for improving the performance of large language models on tasks that require deep understanding of entire sequences. While there are still avenues for further research, this work represents a significant step forward in addressing the challenge of long-context utilization in powerful language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Mitigate Position Bias in Large Language Models via Scaling a Single Dimension
Yijiong Yu, Huiqiang Jiang, Xufang Luo, Qianhui Wu, Chin-Yew Lin, Dongsheng Li, Yuqing Yang, Yongfeng Huang, Lili Qiu
0
0
Large Language Models (LLMs) are increasingly applied in various real-world scenarios due to their excellent generalization capabilities and robust generative abilities. However, they exhibit position bias, also known as lost in the middle, a phenomenon that is especially pronounced in long-context scenarios, which indicates the placement of the key information in different positions of a prompt can significantly affect accuracy. This paper first explores the micro-level manifestations of position bias, concluding that attention weights are a micro-level expression of position bias. It further identifies that, in addition to position embeddings, causal attention mask also contributes to position bias by creating position-specific hidden states. Based on these insights, we propose a method to mitigate position bias by scaling this positional hidden states. Experiments on the NaturalQuestions Multi-document QA, KV retrieval, LongBench and timeline reorder tasks, using various models including RoPE models, context windowextended models, and Alibi models, demonstrate the effectiveness and generalizability of our approach. Our method can improve performance by up to 15.2% by modifying just one dimension of hidden states. Our code is available at https://aka.ms/PositionalHidden.
6/5/2024
🔄
Make Your LLM Fully Utilize the Context
Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou
0
0
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information. Based on this intuition, our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle. Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires (1) fine-grained information awareness on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens), and (2) the integration and reasoning of information from two or more short segments. Through applying this information-intensive training on Mistral-7B, we present FILM-7B (FILl-in-the-Middle). To thoroughly assess the ability of FILM-7B for utilizing long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval). The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window. Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU). Github Link: https://github.com/microsoft/FILM.
4/29/2024
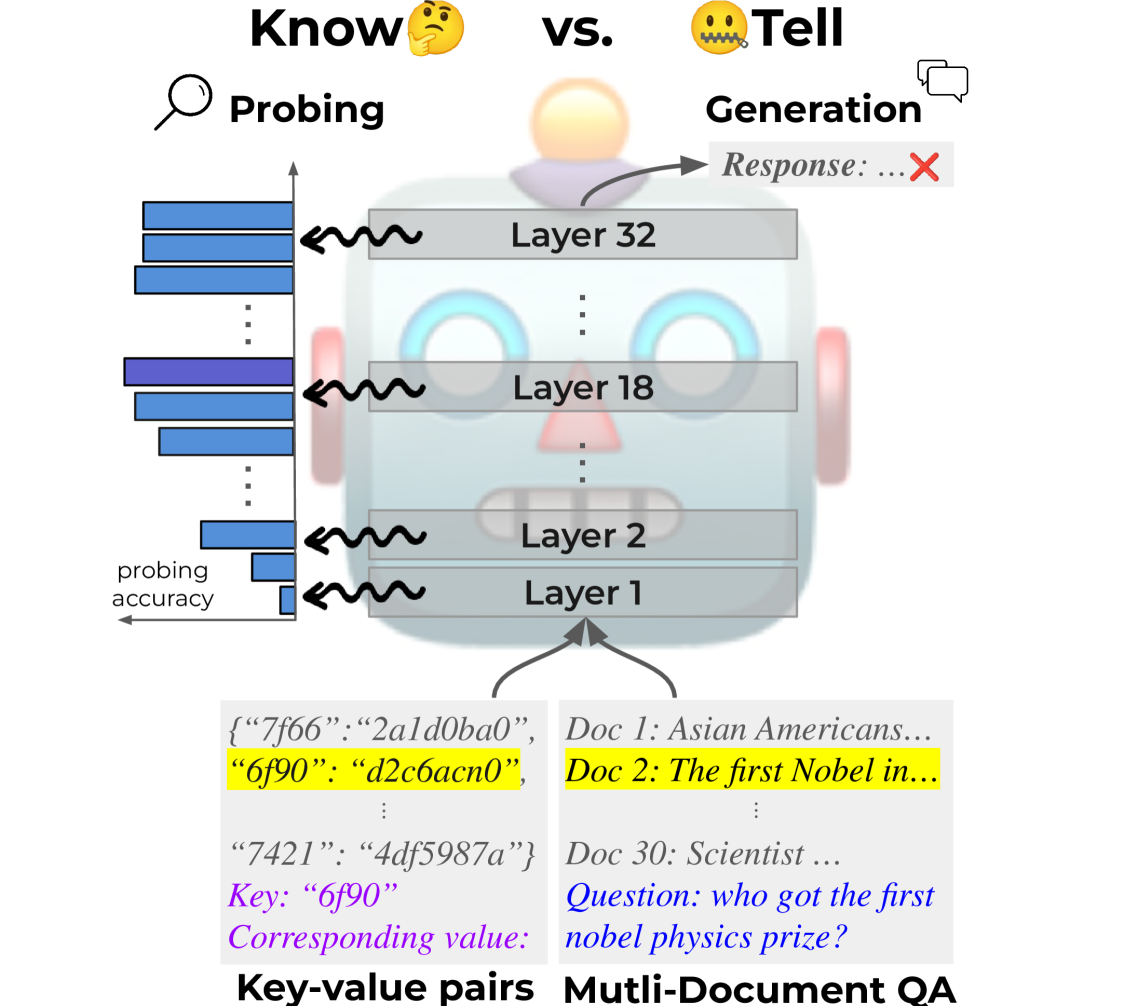
Insights into LLM Long-Context Failures: When Transformers Know but Don't Tell
Taiming Lu, Muhan Gao, Kuai Yu, Adam Byerly, Daniel Khashabi
0
0
Large Language Models (LLMs) exhibit positional bias, struggling to utilize information from the middle or end of long contexts. Our study explores LLMs' long-context reasoning by probing their hidden representations. We find that while LLMs encode the position of target information, they often fail to leverage this in generating accurate responses. This reveals a disconnect between information retrieval and utilization, a know but don't tell phenomenon. We further analyze the relationship between extraction time and final accuracy, offering insights into the underlying mechanics of transformer models.
6/24/2024
💬
On Context Utilization in Summarization with Large Language Models
Mathieu Ravaut, Aixin Sun, Nancy F. Chen, Shafiq Joty
0
0
Large language models (LLMs) excel in abstractive summarization tasks, delivering fluent and pertinent summaries. Recent advancements have extended their capabilities to handle long-input contexts, exceeding 100k tokens. However, in question answering, language models exhibit uneven utilization of their input context. They tend to favor the initial and final segments, resulting in a U-shaped performance pattern concerning where the answer is located within the input. This bias raises concerns, particularly in summarization where crucial content may be dispersed throughout the source document(s). Besides, in summarization, mapping facts from the source to the summary is not trivial as salient content is usually re-phrased. In this paper, we conduct the first comprehensive study on context utilization and position bias in summarization. Our analysis encompasses 6 LLMs, 10 datasets, and 5 evaluation metrics. We introduce a new evaluation benchmark called MiddleSum on the which we benchmark two alternative inference methods to alleviate position bias: hierarchical summarization and incremental summarization. Our code and data can be found here: https://github.com/ntunlp/MiddleSum.
6/17/2024