Mitigate Position Bias in Large Language Models via Scaling a Single Dimension
2406.02536
0
0

Abstract
Large Language Models (LLMs) are increasingly applied in various real-world scenarios due to their excellent generalization capabilities and robust generative abilities. However, they exhibit position bias, also known as lost in the middle, a phenomenon that is especially pronounced in long-context scenarios, which indicates the placement of the key information in different positions of a prompt can significantly affect accuracy. This paper first explores the micro-level manifestations of position bias, concluding that attention weights are a micro-level expression of position bias. It further identifies that, in addition to position embeddings, causal attention mask also contributes to position bias by creating position-specific hidden states. Based on these insights, we propose a method to mitigate position bias by scaling this positional hidden states. Experiments on the NaturalQuestions Multi-document QA, KV retrieval, LongBench and timeline reorder tasks, using various models including RoPE models, context windowextended models, and Alibi models, demonstrate the effectiveness and generalizability of our approach. Our method can improve performance by up to 15.2% by modifying just one dimension of hidden states. Our code is available at https://aka.ms/PositionalHidden.
Create account to get full access
Overview
- This paper explores how to mitigate position bias in large language models (LLMs) by scaling a single dimension.
- Position bias refers to the tendency of LLMs to place disproportionate importance on the position of a word within a sequence, which can lead to suboptimal performance on certain tasks.
- The researchers propose a novel approach that involves scaling a single dimension of the position embeddings, rather than modifying the entire position embedding matrix.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, these models can sometimes exhibit a phenomenon called "position bias," where they place too much importance on the position of a word within a sequence. This can lead to suboptimal performance on certain tasks.
To address this issue, the researchers in this paper propose a new approach that involves scaling a single dimension of the position embeddings, rather than modifying the entire position embedding matrix. [This builds on the work in these related papers: Position-Aware Parameter-Efficient Fine-Tuning Approach, Technical Report: Impact of Position Bias in Language Models, Exploring Context Window in Large Language Models via, Where is the Answer? Investigating Positional Bias in Language Models, and Dwell at the Beginning: How Language Models Embed Long-Range Dependencies.]
By focusing on a single dimension, the researchers were able to reduce the position bias in LLMs while maintaining the model's overall performance. This approach is simpler and more efficient than modifying the entire position embedding matrix, which can be computationally expensive and may not always be effective.
Overall, this research represents an important step towards developing more robust and reliable LLMs that can perform better on a wider range of tasks.
Technical Explanation
The researchers begin by demonstrating that position bias in LLMs is not solely caused by the position embeddings, but is also influenced by the causal masks used in the models. Causal masks are used to ensure that the model only attends to tokens that appear before the current token in the sequence, which can also contribute to position bias.
To address this issue, the researchers propose a novel approach called "Single Dimension Scaling" (SDS). In this method, they scale a single dimension of the position embeddings, rather than modifying the entire position embedding matrix. This allows them to reduce the position bias while maintaining the model's overall performance.
The researchers conduct experiments on a variety of benchmark tasks, including language modeling, question answering, and text classification. They demonstrate that SDS outperforms existing methods for mitigating position bias, such as removing or randomizing the position embeddings.
Furthermore, the researchers provide insights into the mechanisms underlying position bias in LLMs. They show that the position embeddings and causal masks both contribute to this bias, and that scaling a single dimension of the position embeddings is an effective way to address this issue.
Critical Analysis
The researchers provide a comprehensive analysis of the position bias problem in LLMs and offer a novel and effective solution. The SDS approach is relatively simple to implement and appears to be more efficient than modifying the entire position embedding matrix.
However, the paper does not explore the potential limitations or drawbacks of this approach. For example, it is unclear how SDS would perform on tasks that are particularly sensitive to position information, such as sequence-to-sequence tasks or tasks that require strong positional awareness.
Additionally, the paper does not discuss the potential implications of the observed position bias in LLMs. It would be interesting to understand the real-world consequences of this bias and how it might affect the performance of LLMs in practical applications.
Overall, this paper represents an important contribution to the field of language model research, and the SDS approach could be a valuable tool for mitigating position bias in a wide range of LLM applications.
Conclusion
This paper presents a novel approach, called Single Dimension Scaling (SDS), for mitigating position bias in large language models (LLMs). The researchers demonstrate that position bias is not solely caused by the position embeddings, but is also influenced by the causal masks used in the models.
By scaling a single dimension of the position embeddings, the researchers were able to reduce the position bias in LLMs while maintaining the model's overall performance. This approach is simpler and more efficient than modifying the entire position embedding matrix, which can be computationally expensive and may not always be effective.
The researchers provide a comprehensive analysis of the position bias problem and offer insights into the mechanisms underlying this issue. While the paper does not explore the potential limitations or drawbacks of the SDS approach, it represents an important contribution to the field of language model research and could be a valuable tool for developing more robust and reliable LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Position-Aware Parameter Efficient Fine-Tuning Approach for Reducing Positional Bias in LLMs
Zheng Zhang, Fan Yang, Ziyan Jiang, Zheng Chen, Zhengyang Zhao, Chengyuan Ma, Liang Zhao, Yang Liu
0
0
Recent advances in large language models (LLMs) have enhanced their ability to process long input contexts. This development is particularly crucial for tasks that involve retrieving knowledge from an external datastore, which can result in long inputs. However, recent studies show a positional bias in LLMs, demonstrating varying performance depending on the location of useful information within the input sequence. In this study, we conduct extensive experiments to investigate the root causes of positional bias. Our findings indicate that the primary contributor to LLM positional bias stems from the inherent positional preferences of different models. We demonstrate that merely employing prompt-based solutions is inadequate for overcoming the positional preferences. To address this positional bias issue of a pre-trained LLM, we developed a Position-Aware Parameter Efficient Fine-Tuning (PAPEFT) approach which is composed of a data augmentation technique and a parameter efficient adapter, enhancing a uniform attention distribution across the input context. Our experiments demonstrate that the proposed approach effectively reduces positional bias, improving LLMs' effectiveness in handling long context sequences for various tasks that require externally retrieved knowledge.
4/3/2024
💬
Technical Report: Impact of Position Bias on Language Models in Token Classification
Mehdi Ben Amor, Michael Granitzer, Jelena Mitrovi'c
0
0
Language Models (LMs) have shown state-of-the-art performance in Natural Language Processing (NLP) tasks. Downstream tasks such as Named Entity Recognition (NER) or Part-of-Speech (POS) tagging are known to suffer from data imbalance issues, particularly regarding the ratio of positive to negative examples and class disparities. This paper investigates an often-overlooked issue of encoder models, specifically the position bias of positive examples in token classification tasks. For completeness, we also include decoders in the evaluation. We evaluate the impact of position bias using different position embedding techniques, focusing on BERT with Absolute Position Embedding (APE), Relative Position Embedding (RPE), and Rotary Position Embedding (RoPE). Therefore, we conduct an in-depth evaluation of the impact of position bias on the performance of LMs when fine-tuned on token classification benchmarks. Our study includes CoNLL03 and OntoNote5.0 for NER, English Tree Bank UD_en, and TweeBank for POS tagging. We propose an evaluation approach to investigate position bias in transformer models. We show that LMs can suffer from this bias with an average drop ranging from 3% to 9% in their performance. To mitigate this effect, we propose two methods: Random Position Shifting and Context Perturbation, that we apply on batches during the training process. The results show an improvement of $approx$ 2% in the performance of the model on CoNLL03, UD_en, and TweeBank.
4/12/2024

Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization
Cheng-Yu Hsieh, Yung-Sung Chuang, Chun-Liang Li, Zifeng Wang, Long T. Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, Tomas Pfister
0
0
Large language models (LLMs), even when specifically trained to process long input contexts, struggle to capture relevant information located in the middle of their input. This phenomenon has been known as the lost-in-the-middle problem. In this work, we make three contributions. First, we set out to understand the factors that cause this phenomenon. In doing so, we establish a connection between lost-in-the-middle to LLMs' intrinsic attention bias: LLMs exhibit a U-shaped attention bias where the tokens at the beginning and at the end of its input receive higher attention, regardless of their relevance. Second, we mitigate this positional bias through a calibration mechanism, found-in-the-middle, that allows the model to attend to contexts faithfully according to their relevance, even though when they are in the middle. Third, we show found-in-the-middle not only achieves better performance in locating relevant information within a long context, but also eventually leads to improved retrieval-augmented generation (RAG) performance across various tasks, outperforming existing methods by up to 15 percentage points. These findings open up future directions in understanding LLM attention bias and its potential consequences.
6/26/2024
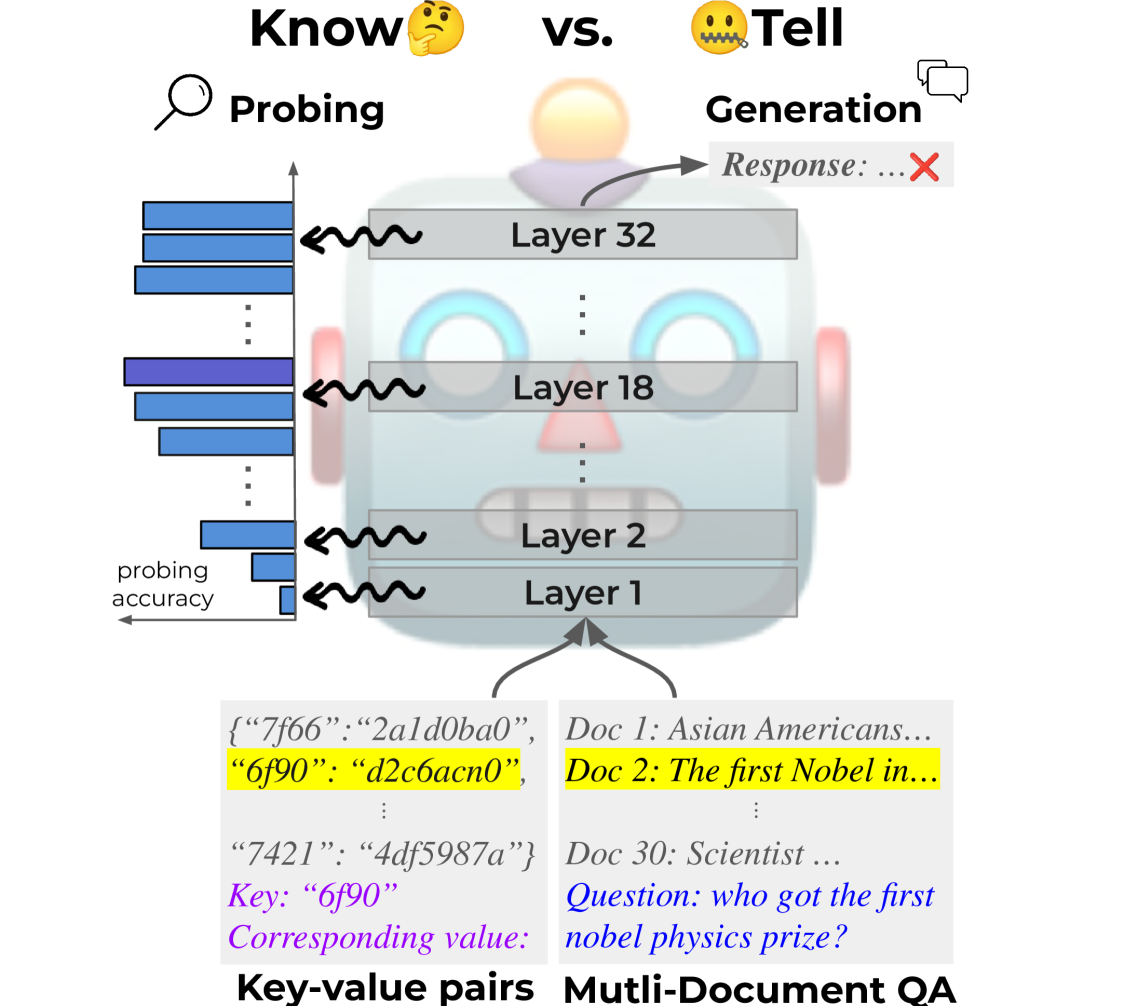
Insights into LLM Long-Context Failures: When Transformers Know but Don't Tell
Taiming Lu, Muhan Gao, Kuai Yu, Adam Byerly, Daniel Khashabi
0
0
Large Language Models (LLMs) exhibit positional bias, struggling to utilize information from the middle or end of long contexts. Our study explores LLMs' long-context reasoning by probing their hidden representations. We find that while LLMs encode the position of target information, they often fail to leverage this in generating accurate responses. This reveals a disconnect between information retrieval and utilization, a know but don't tell phenomenon. We further analyze the relationship between extraction time and final accuracy, offering insights into the underlying mechanics of transformer models.
6/24/2024