An FPGA-Based Reconfigurable Accelerator for Convolution-Transformer Hybrid EfficientViT
2403.20230
0
0
Abstract
Vision Transformers (ViTs) have achieved significant success in computer vision. However, their intensive computations and massive memory footprint challenge ViTs' deployment on embedded devices, calling for efficient ViTs. Among them, EfficientViT, the state-of-the-art one, features a Convolution-Transformer hybrid architecture, enhancing both accuracy and hardware efficiency. Unfortunately, existing accelerators cannot fully exploit the hardware benefits of EfficientViT due to its unique architecture. In this paper, we propose an FPGA-based accelerator for EfficientViT to advance the hardware efficiency frontier of ViTs. Specifically, we design a reconfigurable architecture to efficiently support various operation types, including lightweight convolutions and attention, boosting hardware utilization. Additionally, we present a time-multiplexed and pipelined dataflow to facilitate both intra- and inter-layer fusions, reducing off-chip data access costs. Experimental results show that our accelerator achieves up to 780.2 GOPS in throughput and 105.1 GOPS/W in energy efficiency at 200MHz on the Xilinx ZCU102 FPGA, which significantly outperforms prior works.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents an FPGA-based reconfigurable accelerator for a Convolution-Transformer Hybrid EfficientViT model, which aims to improve the efficiency of vision transformer architectures.
- The accelerator is designed to leverage the strengths of both convolutional and transformer-based approaches for computer vision tasks.
- The research is supported by the National Key R&D Program of China under Grant 2022YFB4400604.
Plain English Explanation
The paper describes a new hardware system that can run a type of artificial intelligence (AI) model called a "vision transformer" more efficiently. Vision transformers are a recent advancement in computer vision, allowing AI systems to understand and process visual information in a more powerful way than traditional approaches.
However, vision transformers can be computationally intensive and require a lot of processing power. The researchers in this paper have developed a special hardware accelerator, built using a type of programmable chip called an FPGA, that can run these vision transformer models more efficiently.
The key idea is to combine the strengths of two different AI techniques - convolutional neural networks and transformer models. Convolutional networks are well-suited for processing visual information, while transformer models excel at understanding contextual relationships. By blending these approaches, the researchers have created a hybrid model that can leverage the benefits of both.
The FPGA-based accelerator is designed to run this hybrid vision transformer model more quickly and with lower power consumption than a general-purpose computer. This could enable deploying advanced computer vision AI in energy-constrained settings like mobile devices or embedded systems.
Technical Explanation
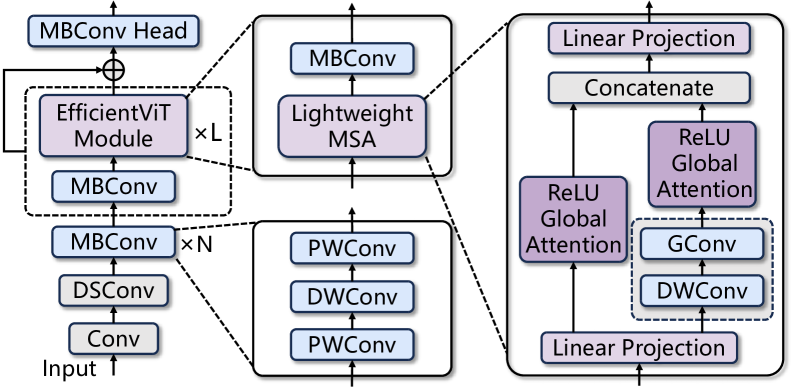
The paper introduces a reconfigurable hardware accelerator based on field-programmable gate arrays (FPGAs) for a Convolution-Transformer Hybrid EfficientViT model. EfficientViT is a variant of the Vision Transformer (ViT) architecture that aims to improve efficiency.
The accelerator architecture consists of three main components:
- A Convolution Module that efficiently handles the convolutional layers of the hybrid model.
- A Transformer Module that accelerates the transformer layers.
- A Scheduling and Control Unit that manages the data flow between the modules.
The researchers implemented the accelerator on a Xilinx Zynq UltraScale+ MPSoC FPGA platform. They evaluated the performance and energy efficiency of the accelerator on image classification tasks, comparing it to a CPU and GPU implementation.
The results show that the FPGA-based accelerator can achieve up to 4.7x higher throughput and 7.9x better energy efficiency compared to running the model on a CPU. It also outperforms a GPU implementation in terms of energy efficiency.
Critical Analysis
The paper provides a strong technical explanation of the proposed FPGA-based accelerator and demonstrates its benefits in terms of performance and energy efficiency. The hybrid approach of combining convolutional and transformer layers is well-motivated and the architecture seems thoughtfully designed to leverage the strengths of each component.
However, the paper does not deeply explore the potential limitations or tradeoffs of this approach. For example, it is unclear how the reconfigurability of the FPGA-based design impacts the overall efficiency gains, or how the accelerator would scale to larger or more complex vision transformer models.
Additionally, the paper does not discuss potential challenges in deploying such a specialized hardware accelerator in real-world settings, such as the cost, complexity, and programmability compared to general-purpose GPU or CPU solutions.
Further research could investigate the generalizability of the hybrid approach, explore alternative hardware implementations, and assess the practical feasibility and commercialization potential of the proposed accelerator design.
Conclusion
In summary, this paper presents an innovative FPGA-based accelerator for a Convolution-Transformer Hybrid EfficientViT model, which aims to improve the efficiency of advanced vision transformer architectures. The hybrid design and reconfigurable hardware implementation allow the accelerator to outperform CPU and GPU solutions in terms of throughput and energy efficiency for image classification tasks.
While the technical details are compelling, the paper could benefit from a deeper exploration of the potential limitations and practical considerations of deploying such a specialized hardware accelerator. Nonetheless, this research represents an important step towards developing more efficient and capable computer vision systems, with potential applications in energy-constrained environments like mobile devices and edge computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Model Quantization and Hardware Acceleration for Vision Transformers: A Comprehensive Survey
Dayou Du, Gu Gong, Xiaowen Chu
0
0
Vision Transformers (ViTs) have recently garnered considerable attention, emerging as a promising alternative to convolutional neural networks (CNNs) in several vision-related applications. However, their large model sizes and high computational and memory demands hinder deployment, especially on resource-constrained devices. This underscores the necessity of algorithm-hardware co-design specific to ViTs, aiming to optimize their performance by tailoring both the algorithmic structure and the underlying hardware accelerator to each other's strengths. Model quantization, by converting high-precision numbers to lower-precision, reduces the computational demands and memory needs of ViTs, allowing the creation of hardware specifically optimized for these quantized algorithms, boosting efficiency. This article provides a comprehensive survey of ViTs quantization and its hardware acceleration. We first delve into the unique architectural attributes of ViTs and their runtime characteristics. Subsequently, we examine the fundamental principles of model quantization, followed by a comparative analysis of the state-of-the-art quantization techniques for ViTs. Additionally, we explore the hardware acceleration of quantized ViTs, highlighting the importance of hardware-friendly algorithm design. In conclusion, this article will discuss ongoing challenges and future research paths. We consistently maintain the related open-source materials at https://github.com/DD-DuDa/awesome-vit-quantization-acceleration.
5/2/2024
👀
New!Q-HyViT: Post-Training Quantization of Hybrid Vision Transformers with Bridge Block Reconstruction for IoT Systems
Jemin Lee, Yongin Kwon, Sihyeong Park, Misun Yu, Jeman Park, Hwanjun Song
0
0
Recently, vision transformers (ViTs) have superseded convolutional neural networks in numerous applications, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers with optimized attention computation of linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. For mobile devices, achieving optimal acceleration for ViTs necessitates the strategic integration of quantization techniques and efficient hybrid transformer structures. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, we discover that applying existing post-training quantization (PTQ) methods for ViTs to efficient hybrid transformers leads to a drastic accuracy drop, attributed to the four following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters ($<$5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid ViTs (MobileViTv1, MobileViTv2, Mobile-Former, EfficientFormerV1, EfficientFormerV2). We achieve a significant improvement of 17.73% for 8-bit and 29.75% for 6-bit on average, respectively, compared with existing PTQ methods (EasyQuant, FQ-ViT, PTQ4ViT, and RepQ-ViT)}. We plan to release our code at https://gitlab.com/ones-ai/q-hyvit.
5/20/2024
Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free Efficient Vision Transformer
Huihong Shi, Haikuo Shao, Wendong Mao, Zhongfeng Wang
0
0
Motivated by the huge success of Transformers in the field of natural language processing (NLP), Vision Transformers (ViTs) have been rapidly developed and achieved remarkable performance in various computer vision tasks. However, their huge model sizes and intensive computations hinder ViTs' deployment on embedded devices, calling for effective model compression methods, such as quantization. Unfortunately, due to the existence of hardware-unfriendly and quantization-sensitive non-linear operations, particularly {Softmax}, it is non-trivial to completely quantize all operations in ViTs, yielding either significant accuracy drops or non-negligible hardware costs. In response to challenges associated with textit{standard ViTs}, we focus our attention towards the quantization and acceleration for textit{efficient ViTs}, which not only eliminate the troublesome Softmax but also integrate linear attention with low computational complexity, and propose emph{Trio-ViT} accordingly. Specifically, at the algorithm level, we develop a {tailored post-training quantization engine} taking the unique activation distributions of Softmax-free efficient ViTs into full consideration, aiming to boost quantization accuracy. Furthermore, at the hardware level, we build an accelerator dedicated to the specific Convolution-Transformer hybrid architecture of efficient ViTs, thereby enhancing hardware efficiency. Extensive experimental results consistently prove the effectiveness of our Trio-ViT framework. {Particularly, we can gain up to $uparrow$$mathbf{7.2}times$ and $uparrow$$mathbf{14.6}times$ FPS under comparable accuracy over state-of-the-art ViT accelerators, as well as $uparrow$$mathbf{5.9}times$ and $uparrow$$mathbf{2.0}times$ DSP efficiency.} Codes will be released publicly upon acceptance.
5/8/2024
GCV-Turbo: End-to-end Acceleration of GNN-based Computer Vision Tasks on FPGA
Bingyi Zhang, Rajgopal Kannan, Carl Busart, Viktor Prasanna
0
0
Graph neural networks (GNNs) have recently empowered various novel computer vision (CV) tasks. In GNN-based CV tasks, a combination of CNN layers and GNN layers or only GNN layers are employed. This paper introduces GCV-Turbo, a domain-specific accelerator on FPGA for end-to-end acceleration of GNN-based CV tasks. GCV-Turbo consists of two key components: (1) a emph{novel} hardware architecture optimized for the computation kernels in both CNNs and GNNs using the same set of computation resources. (2) a PyTorch-compatible compiler that takes a user-defined model as input, performs end-to-end optimization for the computation graph of a given GNN-based CV task, and produces optimized code for hardware execution. The hardware architecture and the compiler work synergistically to support a variety of GNN-based CV tasks. We implement GCV-Turbo on a state-of-the-art FPGA and evaluate its performance across six representative GNN-based CV tasks with diverse input data modalities (e.g., image, human skeleton, point cloud). Compared with state-of-the-art CPU (GPU) implementations, GCV-Turbo achieves an average latency reduction of $68.4times$ ($4.1times$) on these six GNN-based CV tasks. Moreover, GCV-Turbo supports the execution of the standalone CNNs or GNNs, achieving performance comparable to that of state-of-the-art CNN (GNN) accelerators for widely used CNN-only (GNN-only) models.
4/11/2024