GCV-Turbo: End-to-end Acceleration of GNN-based Computer Vision Tasks on FPGA

0
Sign in to get full access
Overview
- The paper "GCV-Turbo: End-to-end Acceleration of GNN-based Computer Vision Tasks on FPGA" presents a novel FPGA-based acceleration framework for Graph Neural Network (GNN) models in computer vision tasks.
- The framework, named GCV-Turbo, aims to provide end-to-end acceleration of GNN-based computer vision pipelines on FPGA platforms.
- The authors propose various optimization techniques, including graph partitioning, custom hardware design, and runtime scheduling, to achieve high performance and energy efficiency.
Plain English Explanation
Graph Neural Networks (GNNs) are a type of machine learning model that can effectively capture the relationships between different elements in an image or other data. This makes them powerful for a variety of computer vision tasks, such as object detection, image segmentation, and scene understanding. However, running these GNN models on traditional hardware like CPUs or GPUs can be slow and energy-intensive.
The researchers behind this paper have developed a new system called "GCV-Turbo" that can run GNN-based computer vision models much faster and more efficiently on a type of specialized hardware called an FPGA (Field-Programmable Gate Array). FPGAs are flexible chips that can be reconfigured to perform specific computations very quickly.
The key ideas behind GCV-Turbo are:
- Partitioning the GNN graph into smaller, more manageable pieces that can be processed in parallel on the FPGA.
- Designing custom hardware components on the FPGA that are optimized for the specific operations required by GNN models.
- Developing advanced scheduling techniques to make the best use of the FPGA's resources and minimize any delays or bottlenecks.
By implementing these ideas, the researchers were able to achieve significant speedups (up to 7.4x) and energy savings (up to 9.8x) compared to running the same GNN models on a GPU. This means that GNN-based computer vision applications could potentially run much faster and more efficiently on FPGA-powered devices, which could have important implications for real-world applications like self-driving cars, robotics, and augmented reality.
Technical Explanation
The paper introduces GCV-Turbo, a novel FPGA-based acceleration framework for end-to-end acceleration of GNN-based computer vision tasks. The key components of GCV-Turbo include:
-
Graph Partitioning: The authors propose a novel graph partitioning algorithm that divides the GNN graph into smaller subgraphs, which can be efficiently mapped and executed on the FPGA's parallel processing resources. [See related work: FPGA-based Reconfigurable Accelerator for Convolution-Transformer Hybrid]
-
Custom Hardware Design: GCV-Turbo incorporates custom hardware components and dataflow architectures that are tailored to the specific computational requirements of GNN models. This includes efficient implementations of key GNN operations, such as message passing and graph pooling. [See related work: GVT: Graph-based Vision Transformer "Talking Heads"]
-
Runtime Scheduling: The framework employs advanced runtime scheduling techniques to manage the execution of the partitioned GNN subgraphs on the FPGA, ensuring efficient utilization of the available hardware resources. [See related work: Understanding the Potential of FPGA-based Spatial Acceleration for Large-Scale Vision Transformers]
The authors evaluate GCV-Turbo on several GNN-based computer vision benchmarks, including object detection, semantic segmentation, and point cloud processing. The results demonstrate significant performance and energy efficiency improvements compared to GPU-based implementations, with speedups of up to 7.4x and energy savings of up to 9.8x. [See related work: FasterViT: Fast Vision Transformers with Hierarchical Attention]
Critical Analysis
The paper presents a well-designed and thoroughly evaluated FPGA-based acceleration framework for GNN-based computer vision tasks. The authors have addressed several key challenges in mapping GNN models to FPGA hardware, such as graph partitioning, custom hardware design, and runtime scheduling.
One potential limitation of the work is the reliance on a specific FPGA platform (Xilinx Alveo U280) for the evaluation. It would be valuable to understand the performance and scalability of GCV-Turbo on a broader range of FPGA platforms, including lower-cost and edge-deployed devices. [See related work: A Fast System-Technology Co-Optimization Framework for Emerging Accelerators]
Additionally, the paper does not delve into the architectural details of the custom hardware components designed for GNN operations. A more in-depth description of these hardware designs and their tradeoffs would be beneficial for researchers interested in further optimizing or extending the GCV-Turbo framework.
Overall, the GCV-Turbo framework represents a significant advancement in the field of FPGA-based acceleration for GNN-based computer vision tasks, and the results presented in the paper are promising for the future development of high-performance and energy-efficient edge computing solutions.
Conclusion
The "GCV-Turbo: End-to-end Acceleration of GNN-based Computer Vision Tasks on FPGA" paper introduces a novel FPGA-based acceleration framework that can significantly improve the performance and energy efficiency of Graph Neural Network (GNN) models in various computer vision applications. By proposing techniques like graph partitioning, custom hardware design, and runtime scheduling, the researchers have demonstrated the potential of FPGA-based acceleration for enabling the deployment of advanced GNN-based computer vision models on edge devices and resource-constrained platforms. This work paves the way for more efficient and accessible real-world applications of GNN-powered computer vision, with potential impacts on domains such as autonomous driving, robotics, and augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GCV-Turbo: End-to-end Acceleration of GNN-based Computer Vision Tasks on FPGA
Bingyi Zhang, Rajgopal Kannan, Carl Busart, Viktor Prasanna
Graph neural networks (GNNs) have recently empowered various novel computer vision (CV) tasks. In GNN-based CV tasks, a combination of CNN layers and GNN layers or only GNN layers are employed. This paper introduces GCV-Turbo, a domain-specific accelerator on FPGA for end-to-end acceleration of GNN-based CV tasks. GCV-Turbo consists of two key components: (1) a emph{novel} hardware architecture optimized for the computation kernels in both CNNs and GNNs using the same set of computation resources. (2) a PyTorch-compatible compiler that takes a user-defined model as input, performs end-to-end optimization for the computation graph of a given GNN-based CV task, and produces optimized code for hardware execution. The hardware architecture and the compiler work synergistically to support a variety of GNN-based CV tasks. We implement GCV-Turbo on a state-of-the-art FPGA and evaluate its performance across six representative GNN-based CV tasks with diverse input data modalities (e.g., image, human skeleton, point cloud). Compared with state-of-the-art CPU (GPU) implementations, GCV-Turbo achieves an average latency reduction of $68.4times$ ($4.1times$) on these six GNN-based CV tasks. Moreover, GCV-Turbo supports the execution of the standalone CNNs or GNNs, achieving performance comparable to that of state-of-the-art CNN (GNN) accelerators for widely used CNN-only (GNN-only) models.
Read more4/11/2024
🧠
0
EvGNN: An Event-driven Graph Neural Network Accelerator for Edge Vision
Yufeng Yang, Adrian Kneip, Charlotte Frenkel
Edge vision systems combining sensing and embedded processing promise low-latency, decentralized, and energy-efficient solutions that forgo reliance on the cloud. As opposed to conventional frame-based vision sensors, event-based cameras deliver a microsecond-scale temporal resolution with sparse information encoding, thereby outlining new opportunities for edge vision systems. However, mainstream algorithms for frame-based vision, which mostly rely on convolutional neural networks (CNNs), can hardly exploit the advantages of event-based vision as they are typically optimized for dense matrix-vector multiplications. While event-driven graph neural networks (GNNs) have recently emerged as a promising solution for sparse event-based vision, their irregular structure is a challenge that currently hinders the design of efficient hardware accelerators. In this paper, we propose EvGNN, the first event-driven GNN accelerator for low-footprint, ultra-low-latency, and high-accuracy edge vision with event-based cameras. It relies on three central ideas: (i) directed dynamic graphs exploiting single-hop nodes with edge-free storage, (ii) event queues for the efficient identification of local neighbors within a spatiotemporally decoupled search range, and (iii) a novel layer-parallel processing scheme enabling the low-latency execution of multi-layer GNNs. We deployed EvGNN on a Xilinx KV260 Ultrascale+ MPSoC platform and benchmarked it on the N-CARS dataset for car recognition, demonstrating a classification accuracy of 87.8% and an average latency per event of 16$mu$s, thereby enabling real-time, microsecond-resolution event-based vision at the edge.
Read more5/1/2024
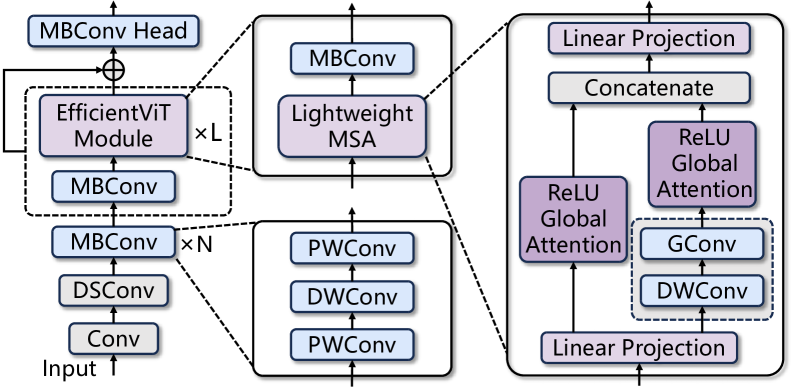
0
An FPGA-Based Reconfigurable Accelerator for Convolution-Transformer Hybrid EfficientViT
Haikuo Shao, Huihong Shi, Wendong Mao, Zhongfeng Wang
Vision Transformers (ViTs) have achieved significant success in computer vision. However, their intensive computations and massive memory footprint challenge ViTs' deployment on embedded devices, calling for efficient ViTs. Among them, EfficientViT, the state-of-the-art one, features a Convolution-Transformer hybrid architecture, enhancing both accuracy and hardware efficiency. Unfortunately, existing accelerators cannot fully exploit the hardware benefits of EfficientViT due to its unique architecture. In this paper, we propose an FPGA-based accelerator for EfficientViT to advance the hardware efficiency frontier of ViTs. Specifically, we design a reconfigurable architecture to efficiently support various operation types, including lightweight convolutions and attention, boosting hardware utilization. Additionally, we present a time-multiplexed and pipelined dataflow to facilitate both intra- and inter-layer fusions, reducing off-chip data access costs. Experimental results show that our accelerator achieves up to 780.2 GOPS in throughput and 105.1 GOPS/W in energy efficiency at 200MHz on the Xilinx ZCU102 FPGA, which significantly outperforms prior works.
Read more4/1/2024
🧠
0
A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective
Chaoqi Chen, Yushuang Wu, Qiyuan Dai, Hong-Yu Zhou, Mutian Xu, Sibei Yang, Xiaoguang Han, Yizhou Yu
Graph Neural Networks (GNNs) have gained momentum in graph representation learning and boosted the state of the art in a variety of areas, such as data mining (emph{e.g.,} social network analysis and recommender systems), computer vision (emph{e.g.,} object detection and point cloud learning), and natural language processing (emph{e.g.,} relation extraction and sequence learning), to name a few. With the emergence of Transformers in natural language processing and computer vision, graph Transformers embed a graph structure into the Transformer architecture to overcome the limitations of local neighborhood aggregation while avoiding strict structural inductive biases. In this paper, we present a comprehensive review of GNNs and graph Transformers in computer vision from a task-oriented perspective. Specifically, we divide their applications in computer vision into five categories according to the modality of input data, emph{i.e.,} 2D natural images, videos, 3D data, vision + language, and medical images. In each category, we further divide the applications according to a set of vision tasks. Such a task-oriented taxonomy allows us to examine how each task is tackled by different GNN-based approaches and how well these approaches perform. Based on the necessary preliminaries, we provide the definitions and challenges of the tasks, in-depth coverage of the representative approaches, as well as discussions regarding insights, limitations, and future directions.
Read more8/15/2024