FrameQuant: Flexible Low-Bit Quantization for Transformers

0

Sign in to get full access
Overview
- This paper presents FrameQuant, a flexible low-bit quantization method for Transformer-based models.
- FrameQuant allows for efficient deployment of Transformer models on resource-constrained devices by reducing the bit-width of model parameters.
- The key idea is to leverage finite frame theory and fusion frames to enable flexible and robust low-bit quantization.
Plain English Explanation
FrameQuant: Flexible Low-Bit Quantization for Transformers is a research paper that introduces a new way to compress Transformer-based machine learning models. Transformer models are a type of neural network that have become very popular for tasks like natural language processing and computer vision, but they can also be quite large and computationally expensive to run, especially on devices with limited resources like phones or embedded systems.
The researchers behind FrameQuant wanted to find a way to reduce the size and complexity of Transformer models without sacrificing too much performance. Their solution is a quantization technique, which means converting the model's floating-point parameters (the numbers that define how the model works) into integers that take up less memory and can be processed faster.
The key innovation in FrameQuant is that it uses an advanced mathematical framework called finite frame theory and fusion frames to enable flexible and robust low-bit quantization. This allows the method to adapt to the unique structure and characteristics of each Transformer model, finding an optimal balance between compression and accuracy.
In simple terms, FrameQuant gives Transformer models a "diet" - it slims them down so they can run more efficiently on a wider range of devices, from powerful servers to resource-constrained edge devices. This could enable new applications and use cases for Transformer models that weren't feasible before due to the models' size and complexity.
Technical Explanation
FrameQuant: Flexible Low-Bit Quantization for Transformers introduces a novel quantization method for Transformer-based models that leverages finite frame theory and fusion frames. The key idea is to exploit the inherent structure of Transformer architectures to enable flexible and robust low-bit quantization.
The authors first provide an overview of finite frame theory and fusion frames, which form the mathematical foundation of FrameQuant. These concepts allow the quantization process to adapt to the unique characteristics of each Transformer model, leading to more efficient compression without excessive accuracy degradation.
The FrameQuant method consists of three main steps:
-
Frame Construction: The authors construct a finite frame representation of the Transformer model's weight tensors. This captures the underlying structure of the model in a way that enables effective quantization.
-
Fusion Frame Design: The researchers then design a fusion frame, which is a collection of frames that can be used to quantize the model parameters. The fusion frame is optimized to minimize the quantization error while preserving the model's performance.
-
Quantization and Fine-Tuning: Finally, the model parameters are quantized using the fusion frame, and the model is fine-tuned to recover any accuracy lost during the quantization process.
The authors evaluate FrameQuant on various Transformer-based models and tasks, including language modeling, text classification, and image classification. The results demonstrate that FrameQuant can achieve significant model size reductions (up to 4x) while maintaining competitive accuracy, outperforming other state-of-the-art quantization techniques.
Critical Analysis
The FrameQuant paper presents a well-designed and mathematically grounded approach to low-bit quantization for Transformer models. The authors have clearly explained the underlying theory and how it enables the flexible and robust quantization process.
One potential limitation of the FrameQuant method is that it may require additional computational overhead during the frame construction and fusion frame design steps, which could offset some of the efficiency gains from the quantization. The authors acknowledge this and suggest that future work could explore ways to streamline these preprocessing steps.
Additionally, the authors note that the performance of FrameQuant may vary depending on the specific Transformer model and task, and they encourage further exploration of its applicability across a wider range of applications.
Overall, the FrameQuant paper presents a promising approach to enabling the efficient deployment of Transformer models on resource-constrained devices, and the researchers have made their code publicly available for further exploration and development.
Conclusion
The FrameQuant: Flexible Low-Bit Quantization for Transformers paper introduces a novel quantization method that leverages finite frame theory and fusion frames to enable flexible and robust compression of Transformer-based models. By adapting the quantization process to the unique characteristics of each Transformer architecture, FrameQuant can achieve significant model size reductions without excessive accuracy degradation.
This work has the potential to unlock new applications and use cases for Transformer models, as the ability to deploy these powerful AI systems on a wider range of devices, including resource-constrained edge devices, could lead to advancements in areas like real-time language processing, computer vision on mobile platforms, and energy-efficient AI inference. As the authors suggest, further research and development in this direction could yield even more efficient and versatile quantization techniques for Transformer models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FrameQuant: Flexible Low-Bit Quantization for Transformers
Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh
Transformers are the backbone of powerful foundation models for many Vision and Natural Language Processing tasks. But their compute and memory/storage footprint is large, and so, serving such models is expensive often requiring high-end hardware. To mitigate this difficulty, Post-Training Quantization seeks to modify a pre-trained model and quantize it to eight bits or lower, significantly boosting compute/memory/latency efficiency. Such models have been successfully quantized to four bits with some performance loss. In this work, we outline a simple scheme to quantize Transformer-based models to just two bits (plus some overhead) with only a small drop in accuracy. Key to our formulation is a concept borrowed from Harmonic analysis called Fusion Frames. Our main finding is that the quantization must take place not in the original weight space, but instead in the Fusion Frame representations. If quantization is interpreted as the addition of noise, our casting of the problem allows invoking an extensive body of known consistent recovery and noise robustness guarantees. Further, if desired, de-noising filters are known in closed form. We show empirically, via a variety of experiments, that (almost) two-bit quantization for Transformer models promises sizable efficiency gains. The code is available at https://github.com/vsingh-group/FrameQuant
Read more8/1/2024

0
Frame Quantization of Neural Networks
Wojciech Czaja, Sanghoon Na
We present a post-training quantization algorithm with error estimates relying on ideas originating from frame theory. Specifically, we use first-order Sigma-Delta ($SigmaDelta$) quantization for finite unit-norm tight frames to quantize weight matrices and biases in a neural network. In our scenario, we derive an error bound between the original neural network and the quantized neural network in terms of step size and the number of frame elements. We also demonstrate how to leverage the redundancy of frames to achieve a quantized neural network with higher accuracy.
Read more4/15/2024

0
Integer-only Quantized Transformers for Embedded FPGA-based Time-series Forecasting in AIoT
Tianheng Ling, Chao Qian, Gregor Schiele
This paper presents the design of a hardware accelerator for Transformers, optimized for on-device time-series forecasting in AIoT systems. It integrates integer-only quantization and Quantization-Aware Training with optimized hardware designs to realize 6-bit and 4-bit quantized Transformer models, which achieved precision comparable to 8-bit quantized models from related research. Utilizing a complete implementation on an embedded FPGA (Xilinx Spartan-7 XC7S15), we examine the feasibility of deploying Transformer models on embedded IoT devices. This includes a thorough analysis of achievable precision, resource utilization, timing, power, and energy consumption for on-device inference. Our results indicate that while sufficient performance can be attained, the optimization process is not trivial. For instance, reducing the quantization bitwidth does not consistently result in decreased latency or energy consumption, underscoring the necessity of systematically exploring various optimization combinations. Compared to an 8-bit quantized Transformer model in related studies, our 4-bit quantized Transformer model increases test loss by only 0.63%, operates up to 132.33x faster, and consumes 48.19x less energy.
Read more9/9/2024
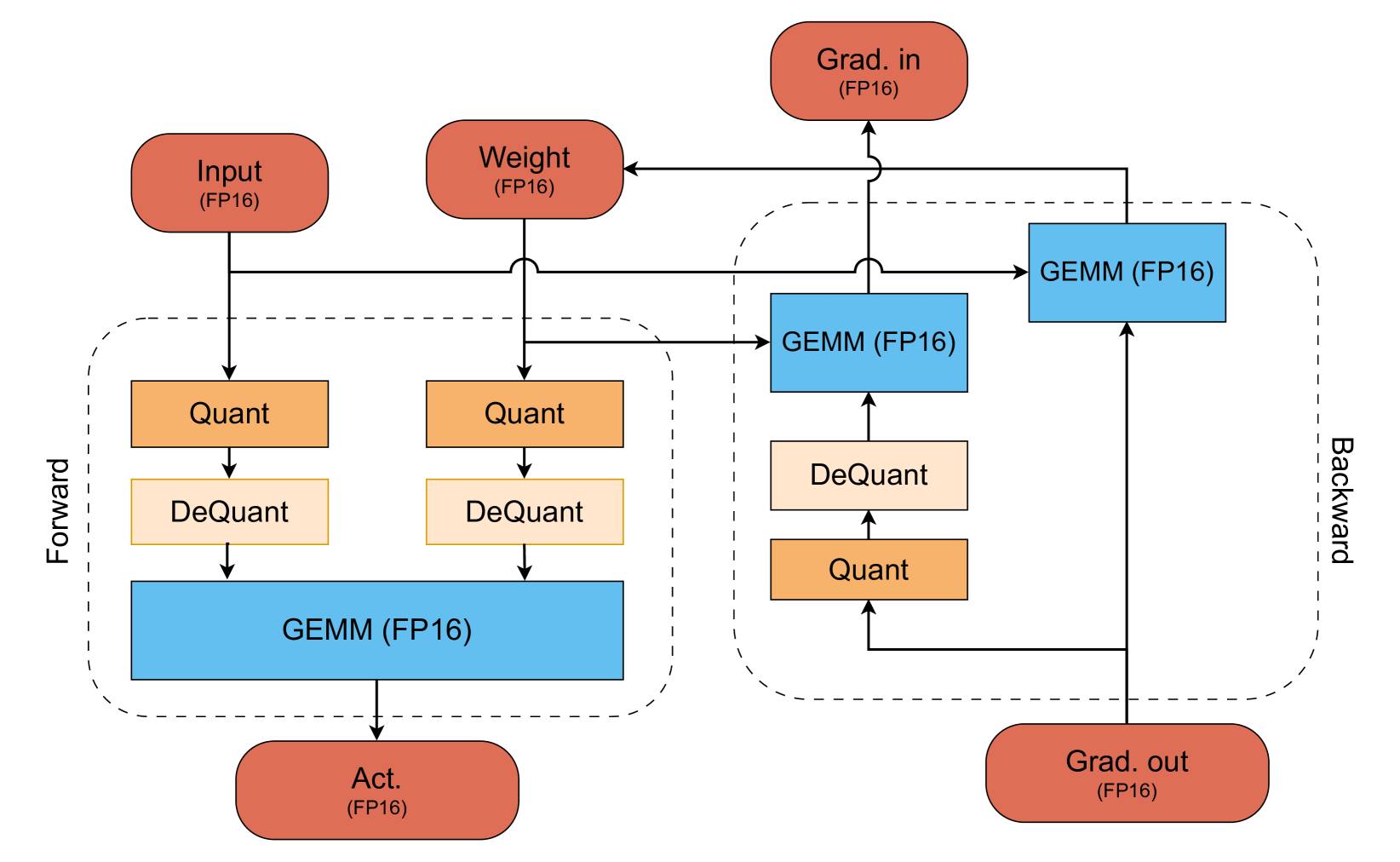
0
Exploring Quantization for Efficient Pre-Training of Transformer Language Models
Kamran Chitsaz, Quentin Fournier, Gonc{c}alo Mordido, Sarath Chandar
The increasing scale of Transformer models has led to an increase in their pre-training computational requirements. While quantization has proven to be effective after pre-training and during fine-tuning, applying quantization in Transformers during pre-training has remained largely unexplored at scale for language modeling. This study aims to explore the impact of quantization for efficient pre-training of Transformers, with a focus on linear layer components. By systematically applying straightforward linear quantization to weights, activations, gradients, and optimizer states, we assess its effects on model efficiency, stability, and performance during training. By offering a comprehensive recipe of effective quantization strategies to be applied during the pre-training of Transformers, we promote high training efficiency from scratch while retaining language modeling ability. Code is available at https://github.com/chandar-lab/EfficientLLMs.
Read more7/17/2024