FRAPPE: $underline{text{F}}$ast $underline{text{Ra}}$nk $underline{text{App}}$roximation with $underline{text{E}}$xplainable Features for Tensors

0
📊
Sign in to get full access
Overview
- Tensor decompositions, such as the CANDECOMP/PARAFAC decomposition (CPD), are effective at analyzing the structure of multidimensional data.
- The CPD requires a crucial parameter - the number of desired components, known as the canonical rank.
- Existing methods for estimating the canonical rank are computationally expensive, as they involve repeatedly calculating the CPD.
Plain English Explanation
Tensors are like multi-dimensional arrays of data, and tensor decompositions can help us understand the underlying structure of this data. One popular tensor decomposition is called CANDECOMP/PARAFAC (CPD), but it requires us to specify the number of components we want to extract - this number is called the "canonical rank."
Figuring out the ideal canonical rank is tricky, and existing methods rely on complex calculations or statistical techniques that are very computationally expensive. They have to run the CPD over and over again to estimate the right number of components.
Technical Explanation
In this paper, the researchers propose a new method called FRAPPE that can estimate the canonical rank of a tensor without actually having to compute the full CPD. The key ideas behind FRAPPE are:
- It's much cheaper to generate synthetic data with known rank than to compute the CPD.
- We can improve the speed and accuracy of the model by generating synthetic data that matches the size and sparsity of the input tensor.
The researchers train a specialized regression model on this synthetic data, and then use that model to quickly estimate the canonical rank of a new tensor - all without running the expensive CPD calculations.
Their experiments show that FRAPPE is over 24 times faster than the best-performing baseline method. It also achieves a 10% improvement in accuracy on a synthetic dataset and performs as well as or better than other methods on real-world datasets.
Critical Analysis
The researchers acknowledge that FRAPPE's performance may be limited by the quality of the synthetic data generation process. If the synthetic data does not accurately reflect the structure of the real-world tensors, the regression model may not generalize well.
Additionally, the paper does not explore how FRAPPE would handle tensors with complex, non-linear structures that may not be well-captured by the synthetic data generation process. Further research could investigate the limits of this approach and ways to make it more robust.
Conclusion
The FRAPPE method offers a promising alternative to existing techniques for estimating the canonical rank of tensors. By avoiding the computationally expensive CPD calculations and instead relying on a specialized regression model trained on synthetic data, FRAPPE is significantly faster and more accurate than previous approaches.
This work could have important implications for a wide range of applications that rely on tensor decompositions, from image and video analysis to recommender systems and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
FRAPPE: $underline{text{F}}$ast $underline{text{Ra}}$nk $underline{text{App}}$roximation with $underline{text{E}}$xplainable Features for Tensors
William Shiao, Evangelos E. Papalexakis
Tensor decompositions have proven to be effective in analyzing the structure of multidimensional data. However, most of these methods require a key parameter: the number of desired components. In the case of the CANDECOMP/PARAFAC decomposition (CPD), the ideal value for the number of components is known as the canonical rank and greatly affects the quality of the decomposition results. Existing methods use heuristics or Bayesian methods to estimate this value by repeatedly calculating the CPD, making them extremely computationally expensive. In this work, we propose FRAPPE, the first method to estimate the canonical rank of a tensor without having to compute the CPD. This method is the result of two key ideas. First, it is much cheaper to generate synthetic data with known rank compared to computing the CPD. Second, we can greatly improve the generalization ability and speed of our model by generating synthetic data that matches a given input tensor in terms of size and sparsity. We can then train a specialized single-use regression model on a synthetic set of tensors engineered to match a given input tensor and use that to estimate the canonical rank of the tensor - all without computing the expensive CPD. FRAPPE is over 24 times faster than the best-performing baseline and exhibits a 10% improvement in MAPE on a synthetic dataset. It also performs as well as or better than the baselines on real-world datasets.
Read more5/28/2024
📉
0
Fast Learnings of Coupled Nonnegative Tensor Decomposition Using Optimal Gradient and Low-rank Approximation
Xiulin Wang, Jing Liu, Fengyu Cong
Tensor decomposition is a fundamental technique widely applied in signal processing, machine learning, and various other fields. However, traditional tensor decomposition methods encounter limitations when jointly analyzing multi-block tensors, as they often struggle to effectively explore shared information among tensors. In this study, we first introduce a novel coupled nonnegative CANDECOMP/PARAFAC decomposition algorithm optimized by the alternating proximal gradient method (CoNCPD-APG). This algorithm is specially designed to address the challenges of jointly decomposing different tensors that are partially or fully linked, while simultaneously extracting common components, individual components and, core tensors. Recognizing the computational challenges inherent in optimizing nonnegative constraints over high-dimensional tensor data, we further propose the lraCoNCPD-APG algorithm. By integrating low-rank approximation with the proposed CoNCPD-APG method, the proposed algorithm can significantly decrease the computational burden without compromising decomposition quality, particularly for multi-block large-scale tensors. Simulation experiments conducted on synthetic data, real-world face image data, and two kinds of electroencephalography (EEG) data demonstrate the practicality and superiority of the proposed algorithms for coupled nonnegative tensor decomposition problems. Our results underscore the efficacy of our methods in uncovering meaningful patterns and structures from complex multi-block tensor data, thereby offering valuable insights for future applications.
Read more6/27/2024
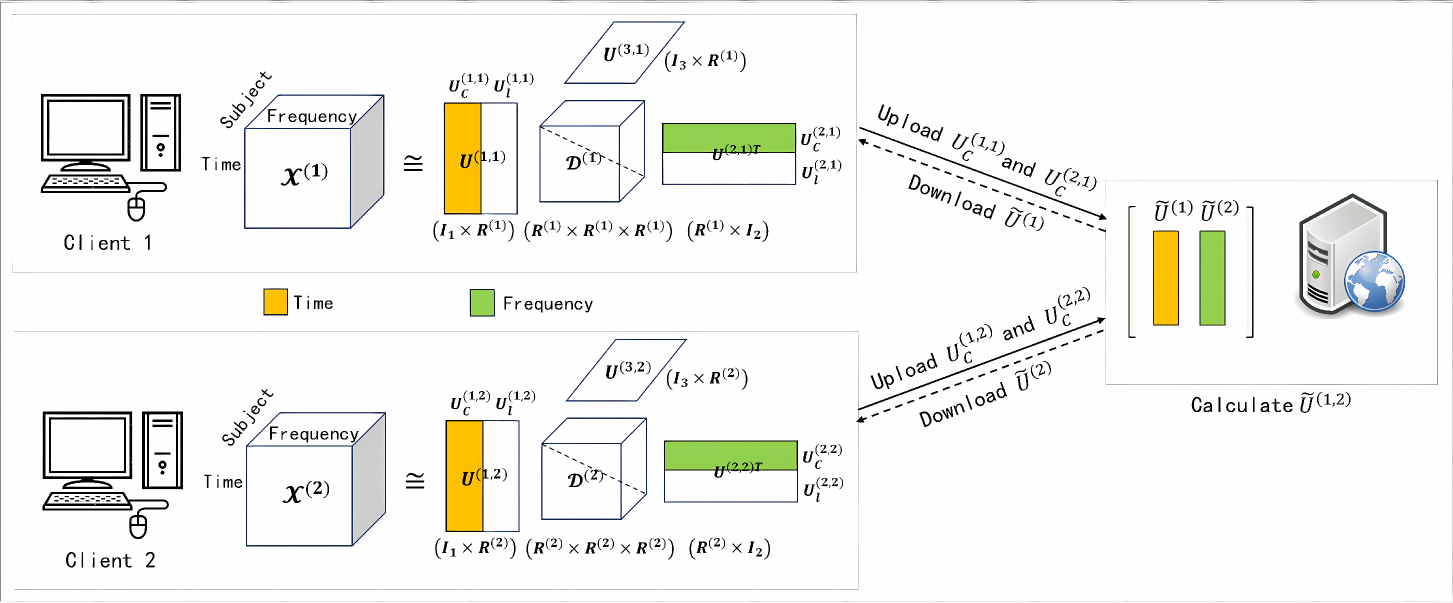
0
FCNCP: A Coupled Nonnegative CANDECOMP/PARAFAC Decomposition Based on Federated Learning
Yukai Cai, Hang Liu, Xiulin Wang, Hongjin Li, Ziyi Wang, Chuanshuai Yang, Fengyu Cong
In the field of brain science, data sharing across servers is becoming increasingly challenging due to issues such as industry competition, privacy security, and administrative procedure policies and regulations. Therefore, there is an urgent need to develop new methods for data analysis and processing that enable scientific collaboration without data sharing. In view of this, this study proposes to study and develop a series of efficient non-negative coupled tensor decomposition algorithm frameworks based on federated learning called FCNCP for the EEG data arranged on different servers. It combining the good discriminative performance of tensor decomposition in high-dimensional data representation and decomposition, the advantages of coupled tensor decomposition in cross-sample tensor data analysis, and the features of federated learning for joint modelling in distributed servers. The algorithm utilises federation learning to establish coupling constraints for data distributed across different servers. In the experiments, firstly, simulation experiments are carried out using simulated data, and stable and consistent decomposition results are obtained, which verify the effectiveness of the proposed algorithms in this study. Then the FCNCP algorithm was utilised to decompose the fifth-order event-related potential (ERP) tensor data collected by applying proprioceptive stimuli on the left and right hands. It was found that contralateral stimulation induced more symmetrical components in the activation areas of the left and right hemispheres. The conclusions drawn are consistent with the interpretations of related studies in cognitive neuroscience, demonstrating that the method can efficiently process higher-order EEG data and that some key hidden information can be preserved.
Read more4/19/2024

0
Unified Framework for Neural Network Compression via Decomposition and Optimal Rank Selection
Ali Aghababaei-Harandi, Massih-Reza Amini
Despite their high accuracy, complex neural networks demand significant computational resources, posing challenges for deployment on resource-constrained devices such as mobile phones and embedded systems. Compression algorithms have been developed to address these challenges by reducing model size and computational demands while maintaining accuracy. Among these approaches, factorization methods based on tensor decomposition are theoretically sound and effective. However, they face difficulties in selecting the appropriate rank for decomposition. This paper tackles this issue by presenting a unified framework that simultaneously applies decomposition and optimal rank selection, employing a composite compression loss within defined rank constraints. Our approach includes an automatic rank search in a continuous space, efficiently identifying optimal rank configurations without the use of training data, making it computationally efficient. Combined with a subsequent fine-tuning step, our approach maintains the performance of highly compressed models on par with their original counterparts. Using various benchmark datasets, we demonstrate the efficacy of our method through a comprehensive analysis.
Read more9/6/2024