From Learning to Optimize to Learning Optimization Algorithms
2405.18222
0
0

Abstract
Towards designing learned optimization algorithms that are usable beyond their training setting, we identify key principles that classical algorithms obey, but have up to now, not been used for Learning to Optimize (L2O). Following these principles, we provide a general design pipeline, taking into account data, architecture and learning strategy, and thereby enabling a synergy between classical optimization and L2O, resulting in a philosophy of Learning Optimization Algorithms. As a consequence our learned algorithms perform well far beyond problems from the training distribution. We demonstrate the success of these novel principles by designing a new learning-enhanced BFGS algorithm and provide numerical experiments evidencing its adaptation to many settings at test time.
Create account to get full access
Overview
- This paper explores the transition from "learning to optimize" to "learning optimization algorithms" - a shift in the field of machine learning and optimization.
- The authors discuss the potential benefits and challenges of learning optimization algorithms, which could lead to more efficient and adaptive optimization methods.
- The paper covers various topics, including Learning to Optimize, Data-Driven Performance Guarantees, Large Language Models and Optimization, Theoretical Guarantees, and Memory-Efficient Optimization.
Plain English Explanation
The paper discusses a shift in the field of machine learning and optimization, moving from "learning to optimize" towards "learning optimization algorithms." The core idea is that instead of just optimizing a specific task, we can now train machine learning models to learn how to optimize in a more general and adaptive way.
This could lead to significant benefits, such as more efficient and effective optimization methods that can adapt to different problems and constraints. For example, the paper explores how large language models could be leveraged to learn optimization algorithms that are more memory-efficient and capable of handling a wider range of optimization tasks.
However, this shift also comes with its own set of challenges. Researchers need to figure out how to design and train these "learned optimization algorithms" in a way that provides strong theoretical guarantees and predictable performance. The paper delves into some of the latest research in this area, looking at topics like data-driven performance guarantees and PAC-Bayesian theoretical guarantees.
Overall, the transition from "learning to optimize" to "learning optimization algorithms" represents an exciting direction in the field, with the potential to unlock new levels of efficiency and adaptability in optimization tasks. But it also requires careful research and consideration to ensure these learned optimization methods are reliable and trustworthy.
Technical Explanation
The paper discusses the shift from "learning to optimize" to "learning optimization algorithms," which represents a significant development in the field of machine learning and optimization.
In the traditional "learning to optimize" approach, machine learning models are trained to optimize specific tasks, such as image classification or natural language processing. However, this approach can be limited in its flexibility and generalization capabilities.
The authors propose the idea of "learning optimization algorithms," where machine learning models are trained to learn how to optimize in a more general and adaptive way. This could involve training models to learn optimization algorithms, such as gradient descent or evolutionary strategies, which can then be applied to a wider range of optimization problems.
The paper explores several key aspects of this transition:
-
Learning to Optimize: The authors provide a tutorial on the current state-of-the-art in "learning to optimize" techniques, including both continuous and mixed-integer optimization problems.
-
Data-Driven Performance Guarantees: The paper discusses the challenge of providing robust performance guarantees for learned optimization algorithms, and explores data-driven approaches to addressing this issue.
-
Large Language Models and Optimization: The authors investigate the potential of leveraging large language models, such as GPT-3, to learn optimization algorithms that are more memory-efficient and capable of handling a wider range of optimization tasks.
-
Theoretical Guarantees: The paper delves into the theoretical aspects of learning optimization algorithms, exploring PAC-Bayesian guarantees and other approaches to ensuring the reliability and predictability of these learned optimization methods.
-
Memory-Efficient Optimization: Finally, the authors discuss the importance of memory-efficient optimization algorithms, particularly in the context of large language models, and present research on how to develop such algorithms.
Critical Analysis
The paper presents an exciting and forward-looking exploration of the transition from "learning to optimize" to "learning optimization algorithms." The authors make a compelling case for the potential benefits of this shift, including the possibility of more efficient and adaptive optimization methods.
However, the paper also acknowledges the significant challenges involved in this transition. Ensuring the reliability and predictability of learned optimization algorithms is a critical concern, and the authors' discussion of theoretical guarantees and data-driven performance evaluation highlights the importance of this issue.
Additionally, the potential integration of large language models into optimization tasks raises interesting questions about the scalability and interpretability of these approaches. While the paper presents promising research in this area, further work may be needed to fully address these concerns.
Overall, the paper provides a comprehensive and insightful overview of the current state of the field and the exciting possibilities ahead. Readers are encouraged to think critically about the research and consider the implications for the future of optimization and machine learning.
Conclusion
This paper explores a significant shift in the field of machine learning and optimization, moving from "learning to optimize" towards "learning optimization algorithms." The core idea is to train machine learning models to learn how to optimize in a more general and adaptive way, rather than just optimizing specific tasks.
The potential benefits of this approach include more efficient and effective optimization methods that can adapt to a wider range of problems and constraints. However, the paper also highlights the challenges involved, such as ensuring the reliability and predictability of these learned optimization algorithms.
The paper covers a range of relevant topics, from learning to optimize to leveraging large language models and providing theoretical guarantees. Overall, the transition represents an exciting and promising direction for the field, with the potential to unlock new levels of efficiency and adaptability in optimization tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning to optimize: A tutorial for continuous and mixed-integer optimization
Xiaohan Chen, Jialin Liu, Wotao Yin
0
0
Learning to Optimize (L2O) stands at the intersection of traditional optimization and machine learning, utilizing the capabilities of machine learning to enhance conventional optimization techniques. As real-world optimization problems frequently share common structures, L2O provides a tool to exploit these structures for better or faster solutions. This tutorial dives deep into L2O techniques, introducing how to accelerate optimization algorithms, promptly estimate the solutions, or even reshape the optimization problem itself, making it more adaptive to real-world applications. By considering the prerequisites for successful applications of L2O and the structure of the optimization problems at hand, this tutorial provides a comprehensive guide for practitioners and researchers alike.
5/27/2024

Learning to optimize with convergence guarantees using nonlinear system theory
Andrea Martin, Luca Furieri
0
0
The increasing reliance on numerical methods for controlling dynamical systems and training machine learning models underscores the need to devise algorithms that dependably and efficiently navigate complex optimization landscapes. Classical gradient descent methods offer strong theoretical guarantees for convex problems; however, they demand meticulous hyperparameter tuning for non-convex ones. The emerging paradigm of learning to optimize (L2O) automates the discovery of algorithms with optimized performance leveraging learning models and data - yet, it lacks a theoretical framework to analyze convergence of the learned algorithms. In this paper, we fill this gap by harnessing nonlinear system theory. Specifically, we propose an unconstrained parametrization of all convergent algorithms for smooth non-convex objective functions. Notably, our framework is directly compatible with automatic differentiation tools, ensuring convergence by design while learning to optimize.
6/4/2024
🚀
Data-Driven Performance Guarantees for Classical and Learned Optimizers
Rajiv Sambharya, Bartolomeo Stellato
0
0
We introduce a data-driven approach to analyze the performance of continuous optimization algorithms using generalization guarantees from statistical learning theory. We study classical and learned optimizers to solve families of parametric optimization problems. We build generalization guarantees for classical optimizers, using a sample convergence bound, and for learned optimizers, using the Probably Approximately Correct (PAC)-Bayes framework. To train learned optimizers, we use a gradient-based algorithm to directly minimize the PAC-Bayes upper bound. Numerical experiments in signal processing, control, and meta-learning showcase the ability of our framework to provide strong generalization guarantees for both classical and learned optimizers given a fixed budget of iterations. For classical optimizers, our bounds are much tighter than those that worst-case guarantees provide. For learned optimizers, our bounds outperform the empirical outcomes observed in their non-learned counterparts.
5/24/2024
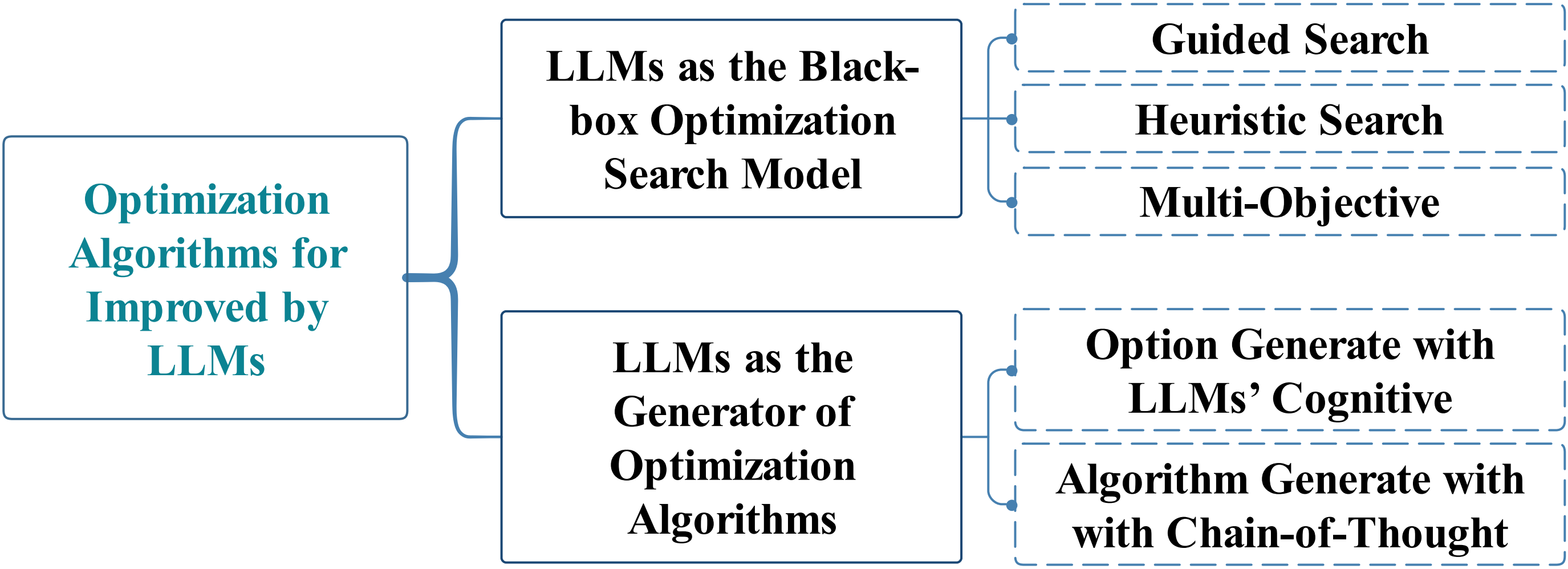
When Large Language Model Meets Optimization
Sen Huang, Kaixiang Yang, Sheng Qi, Rui Wang
0
0
Optimization algorithms and large language models (LLMs) enhance decision-making in dynamic environments by integrating artificial intelligence with traditional techniques. LLMs, with extensive domain knowledge, facilitate intelligent modeling and strategic decision-making in optimization, while optimization algorithms refine LLM architectures and output quality. This synergy offers novel approaches for advancing general AI, addressing both the computational challenges of complex problems and the application of LLMs in practical scenarios. This review outlines the progress and potential of combining LLMs with optimization algorithms, providing insights for future research directions.
5/17/2024