From Static Benchmarks to Adaptive Testing: Psychometrics in AI Evaluation

0
Sign in to get full access
Overview
- Investigates how to efficiently measure the cognitive abilities of large language models (LLMs) using an adaptive testing approach
- Proposes a novel framework that dynamically selects test items to assess an LLM's capabilities in a more targeted and efficient manner
- Aims to provide a robust and scalable methodology for evaluating the cognitive skills of advanced AI systems
Plain English Explanation
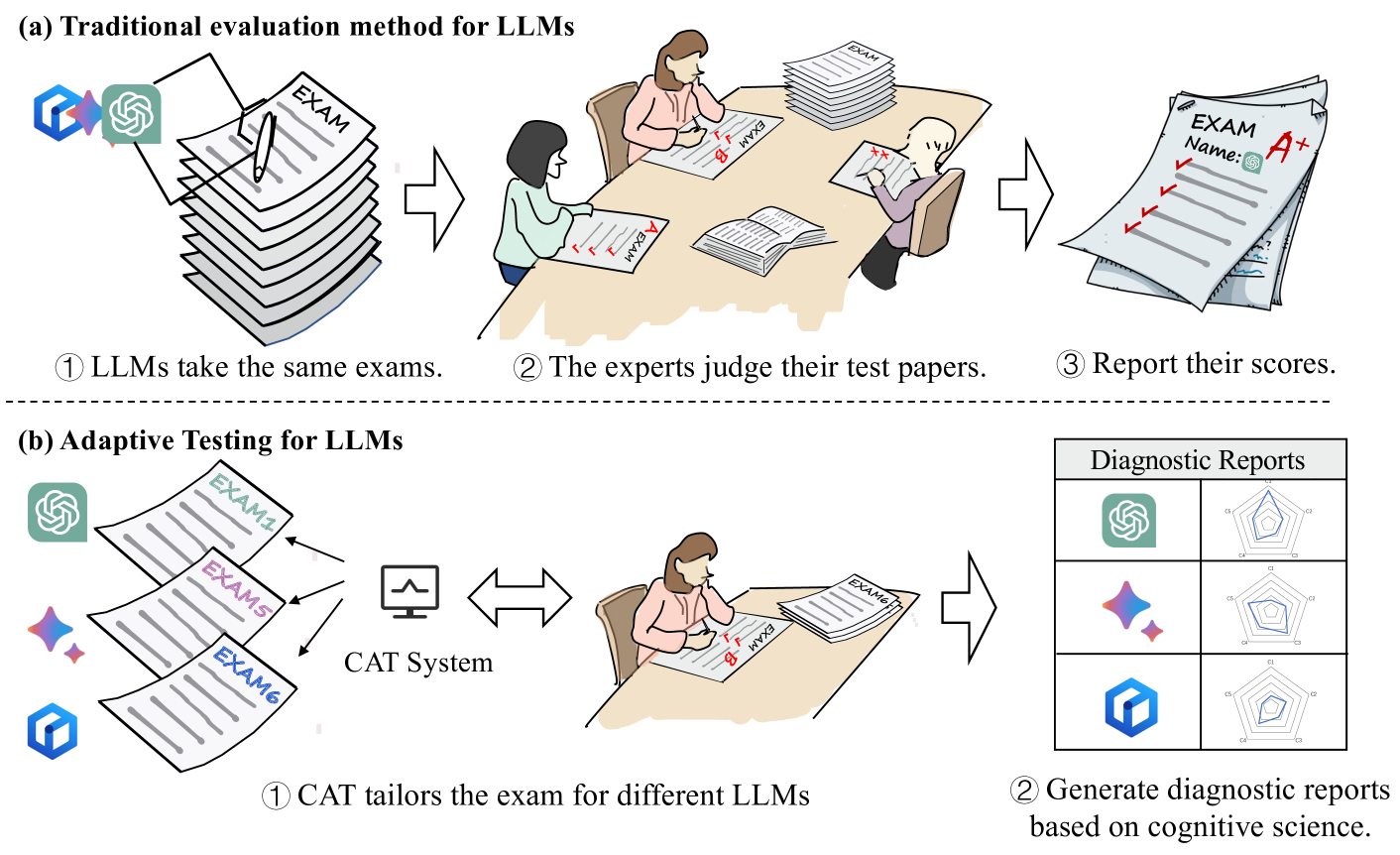
The paper explores ways to measure the cognitive abilities of large language models (LLMs) more effectively. The researchers propose an adaptive testing approach, which means the test dynamically selects questions based on the model's previous responses. This allows the assessment to be more tailored and efficient, rather than using a fixed set of questions. The goal is to develop a robust and scalable method for evaluating the cognitive skills of advanced AI systems like LLMs.
Technical Explanation
The paper presents a novel adaptive testing framework for measuring the cognitive abilities of LLMs. The key ideas are:
-
Adaptive Item Selection: The system dynamically selects test items (questions) based on the model's previous responses, aiming to efficiently assess its capabilities.
-
Ability Estimation: The framework uses Bayesian inference to continuously update its estimate of the model's underlying cognitive abilities as the test progresses.
-
Stopping Criterion: The test adaptively determines when to stop, balancing measurement precision and test length to provide a robust assessment.
The authors evaluate their approach on several benchmark datasets and show that it can achieve comparable or better performance compared to traditional fixed-form tests, while being more efficient.
Critical Analysis
The paper provides a promising approach for evaluating the cognitive abilities of LLMs in a more targeted and efficient manner. However, some potential limitations and areas for further research include:
-
The framework relies on the availability of a large item pool (question bank) to support the adaptive testing process. Constructing and curating such a pool could be challenging, especially for novel or custom-designed cognitive tasks.
-
The evaluation is primarily focused on language-based benchmarks. Extending the approach to assess other modalities, such as visual reasoning, may require additional considerations.
-
The paper does not explore the interpretability or explainability of the ability estimates produced by the framework. Understanding the underlying cognitive processes being measured could be important for practical applications.
Conclusion
This paper presents an adaptive testing framework that can efficiently measure the cognitive abilities of large language models. By dynamically selecting test items and continuously updating ability estimates, the approach aims to provide a robust and scalable methodology for evaluating advanced AI systems. While the research shows promising results, further work is needed to address potential limitations and explore the broader applicability of the framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Static Benchmarks to Adaptive Testing: Psychometrics in AI Evaluation
Yan Zhuang, Qi Liu, Yuting Ning, Weizhe Huang, Zachary A. Pardos, Patrick C. Kyllonen, Jiyun Zu, Qingyang Mao, Rui Lv, Zhenya Huang, Guanhao Zhao, Zheng Zhang, Shijin Wang, Enhong Chen
As AI systems continue to grow, particularly generative models like Large Language Models (LLMs), their rigorous evaluation is crucial for development and deployment. To determine their adequacy, researchers have developed various large-scale benchmarks against a so-called gold-standard test set and report metrics averaged across all items. However, this static evaluation paradigm increasingly shows its limitations, including high computational costs, data contamination, and the impact of low-quality or erroneous items on evaluation reliability and efficiency. In this Perspective, drawing from human psychometrics, we discuss a paradigm shift from static evaluation methods to adaptive testing. This involves estimating the characteristics and value of each test item in the benchmark and dynamically adjusting items in real-time, tailoring the evaluation based on the model's ongoing performance instead of relying on a fixed test set. This paradigm not only provides a more robust ability estimation but also significantly reduces the number of test items required. We analyze the current approaches, advantages, and underlying reasons for adopting psychometrics in AI evaluation. We propose that adaptive testing will become the new norm in AI model evaluation, enhancing both the efficiency and effectiveness of assessing advanced intelligence systems.
Read more8/7/2024

0
Survey of Computerized Adaptive Testing: A Machine Learning Perspective
Qi Liu, Yan Zhuang, Haoyang Bi, Zhenya Huang, Weizhe Huang, Jiatong Li, Junhao Yu, Zirui Liu, Zirui Hu, Yuting Hong, Zachary A. Pardos, Haiping Ma, Mengxiao Zhu, Shijin Wang, Enhong Chen
Computerized Adaptive Testing (CAT) provides an efficient and tailored method for assessing the proficiency of examinees, by dynamically adjusting test questions based on their performance. Widely adopted across diverse fields like education, healthcare, sports, and sociology, CAT has revolutionized testing practices. While traditional methods rely on psychometrics and statistics, the increasing complexity of large-scale testing has spurred the integration of machine learning techniques. This paper aims to provide a machine learning-focused survey on CAT, presenting a fresh perspective on this adaptive testing method. By examining the test question selection algorithm at the heart of CAT's adaptivity, we shed light on its functionality. Furthermore, we delve into cognitive diagnosis models, question bank construction, and test control within CAT, exploring how machine learning can optimize these components. Through an analysis of current methods, strengths, limitations, and challenges, we strive to develop robust, fair, and efficient CAT systems. By bridging psychometric-driven CAT research with machine learning, this survey advocates for a more inclusive and interdisciplinary approach to the future of adaptive testing.
Read more4/8/2024

0
PATCH -- Psychometrics-AssisTed benCHmarking of Large Language Models: A Case Study of Mathematics Proficiency
Qixiang Fang, Daniel L. Oberski, Dong Nguyen
Many existing benchmarks of large (multimodal) language models (LLMs) focus on measuring LLMs' academic proficiency, often with also an interest in comparing model performance with human test takers. While these benchmarks have proven key to the development of LLMs, they suffer from several limitations, including questionable measurement quality (e.g., Do they measure what they are supposed to in a reliable way?), lack of quality assessment on the item level (e.g., Are some items more important or difficult than others?) and unclear human population reference (e.g., To whom can the model be compared?). In response to these challenges, we propose leveraging knowledge from psychometrics - a field dedicated to the measurement of latent variables like academic proficiency - into LLM benchmarking. We make three primary contributions. First, we introduce PATCH: a novel framework for {P}sychometrics-{A}ssis{T}ed ben{CH}marking of LLMs. PATCH addresses the aforementioned limitations, presenting a new direction for LLM benchmark research. Second, we implement PATCH by measuring GPT-4 and Gemini-Pro-Vision's proficiency in 8th grade mathematics against 56 human populations. We show that adopting a psychometrics-based approach yields evaluation outcomes that diverge from those based on existing benchmarking practices. Third, we release 4 high-quality datasets to support measuring and comparing LLM proficiency in grade school mathematics and science against human populations.
Read more7/26/2024
🛸
0
ALBA: Adaptive Language-based Assessments for Mental Health
Vasudha Varadarajan, Sverker Sikstrom, Oscar N. E. Kjell, H. Andrew Schwartz
Mental health issues differ widely among individuals, with varied signs and symptoms. Recently, language-based assessments have shown promise in capturing this diversity, but they require a substantial sample of words per person for accuracy. This work introduces the task of Adaptive Language-Based Assessment ALBA, which involves adaptively ordering questions while also scoring an individual's latent psychological trait using limited language responses to previous questions. To this end, we develop adaptive testing methods under two psychometric measurement theories: Classical Test Theory and Item Response Theory. We empirically evaluate ordering and scoring strategies, organizing into two new methods: a semi-supervised item response theory-based method ALIRT and a supervised Actor-Critic model. While we found both methods to improve over non-adaptive baselines, We found ALIRT to be the most accurate and scalable, achieving the highest accuracy with fewer questions (e.g., Pearson r ~ 0.93 after only 3 questions as compared to typically needing at least 7 questions). In general, adaptive language-based assessments of depression and anxiety were able to utilize a smaller sample of language without compromising validity or large computational costs.
Read more5/17/2024