FUSED-Net: Enhancing Few-Shot Traffic Sign Detection with Unfrozen Parameters, Pseudo-Support Sets, Embedding Normalization, and Domain Adaptation

0
Sign in to get full access
Overview
- FUSED-Net is a deep learning model that aims to enhance few-shot traffic sign detection by incorporating several novel techniques.
- Key contributions include unfrozen parameters, pseudo-support sets, embedding normalization, and domain adaptation.
- The model is evaluated on a cross-domain benchmark for Bangladeshi traffic sign detection.
Plain English Explanation
FUSED-Net: Enhancing Few-Shot Traffic Sign Detection with Unfrozen Parameters, Pseudo-Support Sets, Embedding Normalization, and Domain Adaptation is a research paper that presents a new deep learning model designed to improve the performance of object detection systems when there is limited training data available, a common challenge known as "few-shot learning."
The researchers focused on the specific problem of detecting traffic signs, particularly in the context of Bangladeshi road scenes, which can differ significantly from the environments used to train many existing object detection models.
To address this challenge, the FUSED-Net model incorporates several innovative techniques:
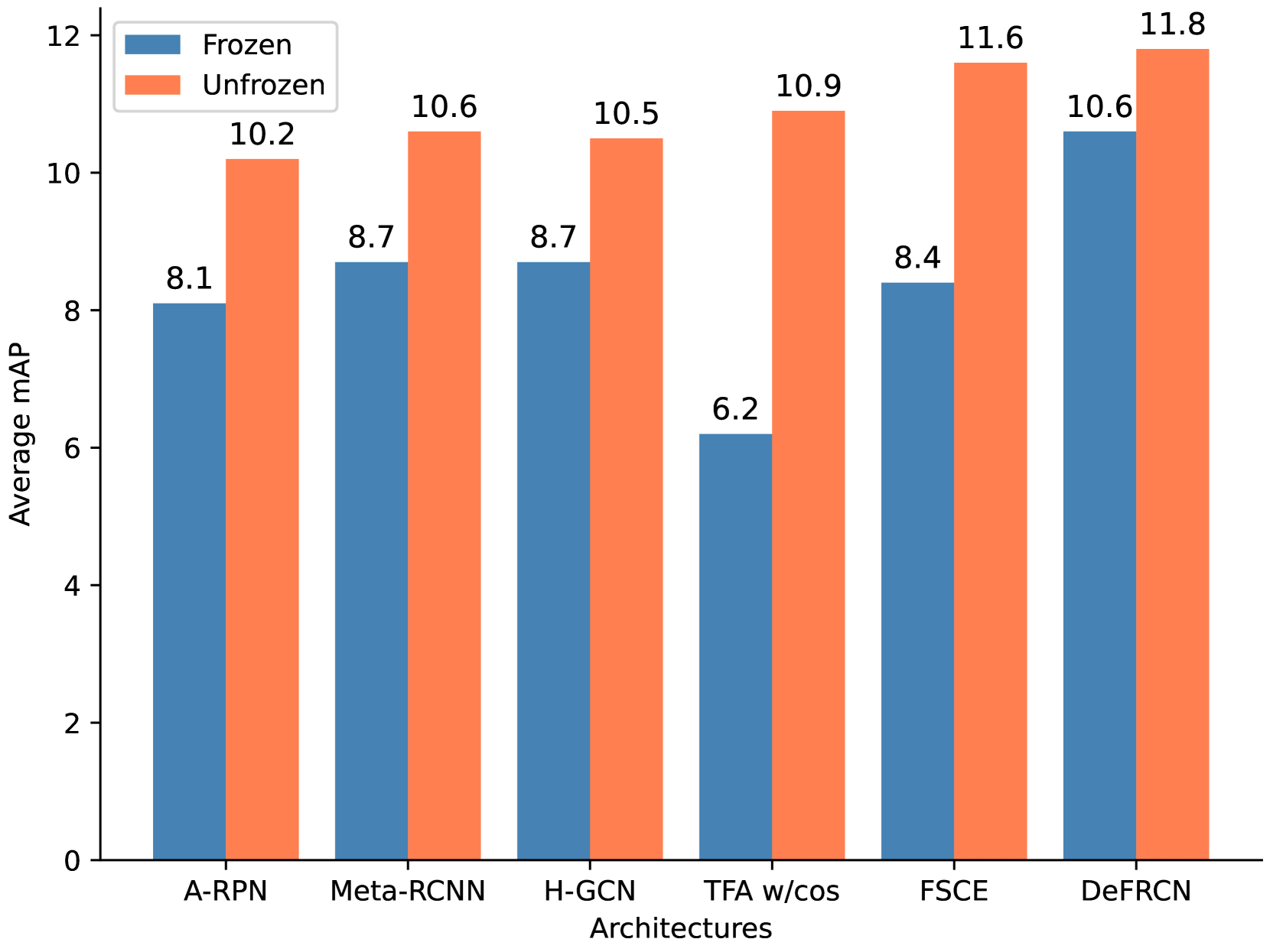
- Unfrozen Parameters: Instead of freezing most of the model's parameters during fine-tuning on the limited training data, FUSED-Net keeps more of the parameters "unfrozen" and able to continue learning.
- Pseudo-Support Sets: The model generates additional "pseudo-support" examples to supplement the limited real training data, helping the model learn more effectively.
- Embedding Normalization: FUSED-Net applies a specialized normalization technique to the model's feature representations, improving its ability to generalize to new data.
- Domain Adaptation: The model incorporates techniques to adapt its knowledge from the source domain (where more training data is available) to the target domain (Bangladeshi traffic scenes).
By combining these approaches, the researchers were able to demonstrate significant improvements in the few-shot traffic sign detection performance of FUSED-Net compared to other state-of-the-art models.
Technical Explanation
FUSED-Net: Enhancing Few-Shot Traffic Sign Detection with Unfrozen Parameters, Pseudo-Support Sets, Embedding Normalization, and Domain Adaptation is a deep learning model designed to address the challenge of few-shot object detection, where only a limited amount of labeled training data is available.
The key technical contributions of FUSED-Net include:
-
Unfrozen Parameters: Instead of freezing most of the model's parameters during fine-tuning on the limited training data, FUSED-Net keeps a larger portion of the parameters "unfrozen" and able to continue learning. This allows the model to better adapt to the new, limited dataset.
-
Pseudo-Support Sets: The researchers generate additional "pseudo-support" examples by applying data augmentation techniques to the limited real training data. These synthetic examples help the model learn more effectively from the scarce data.
-
Embedding Normalization: FUSED-Net applies a specialized normalization technique to the model's feature representations, which helps improve its ability to generalize to new, unseen data.
-
Domain Adaptation: The model incorporates techniques to adapt its knowledge from the source domain (where more training data is available) to the target domain (in this case, Bangladeshi traffic scenes), which can differ significantly from the source domain.
The researchers evaluate FUSED-Net on a cross-domain benchmark for Bangladeshi traffic sign detection, demonstrating significant improvements in few-shot detection performance compared to other state-of-the-art models.
Critical Analysis
The paper provides a comprehensive technical explanation of the FUSED-Net model and its various components. The researchers have thoroughly evaluated the model's performance on a challenging cross-domain few-shot object detection task, which is a relevant and important problem in the field of computer vision.
One potential limitation of the study is the reliance on a single dataset for the Bangladeshi traffic sign detection task. It would be valuable to see how the model performs on additional datasets or in other real-world scenarios to further validate its effectiveness.
Additionally, the paper does not provide much insight into the specific trade-offs or limitations of the individual techniques used in FUSED-Net, such as the impacts of the unfrozen parameters or the pseudo-support sets. A deeper analysis of these components and their relative contributions to the model's performance would be helpful for researchers looking to build upon this work.
Overall, the FUSED-Net model represents a significant advancement in the field of few-shot object detection, and the paper's technical details provide a solid foundation for future research in this area.
Conclusion
FUSED-Net: Enhancing Few-Shot Traffic Sign Detection with Unfrozen Parameters, Pseudo-Support Sets, Embedding Normalization, and Domain Adaptation presents a novel deep learning model that addresses the challenge of few-shot object detection, with a focus on Bangladeshi traffic sign recognition.
By incorporating techniques such as unfrozen parameters, pseudo-support sets, embedding normalization, and domain adaptation, the FUSED-Net model demonstrates significant improvements in detection performance compared to other state-of-the-art approaches. This research represents an important advancement in the field of computer vision, particularly for applications where training data is limited.
While the paper provides a thorough technical explanation of the model, additional exploration of the individual techniques and their tradeoffs would be valuable for researchers looking to build upon this work. Nevertheless, the FUSED-Net model offers a promising solution to the critical problem of few-shot object detection, with potential implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FUSED-Net: Enhancing Few-Shot Traffic Sign Detection with Unfrozen Parameters, Pseudo-Support Sets, Embedding Normalization, and Domain Adaptation
Md. Atiqur Rahman, Nahian Ibn Asad, Md. Mushfiqul Haque Omi, Md. Bakhtiar Hasan, Sabbir Ahmed, Md. Hasanul Kabir
Automatic Traffic Sign Recognition is paramount in modern transportation systems, motivating several research endeavors to focus on performance improvement by utilizing large-scale datasets. As the appearance of traffic signs varies across countries, curating large-scale datasets is often impractical; and requires efficient models that can produce satisfactory performance using limited data. In this connection, we present 'FUSED-Net', built-upon Faster RCNN for traffic sign detection, enhanced by Unfrozen Parameters, Pseudo-Support Sets, Embedding Normalization, and Domain Adaptation while reducing data requirement. Unlike traditional approaches, we keep all parameters unfrozen during training, enabling FUSED-Net to learn from limited samples. The generation of a Pseudo-Support Set through data augmentation further enhances performance by compensating for the scarcity of target domain data. Additionally, Embedding Normalization is incorporated to reduce intra-class variance, standardizing feature representation. Domain Adaptation, achieved by pre-training on a diverse traffic sign dataset distinct from the target domain, improves model generalization. Evaluating FUSED-Net on the BDTSD dataset, we achieved 2.4x, 2.2x, 1.5x, and 1.3x improvements of mAP in 1-shot, 3-shot, 5-shot, and 10-shot scenarios, respectively compared to the state-of-the-art Few-Shot Object Detection (FSOD) models. Additionally, we outperform state-of-the-art works on the cross-domain FSOD benchmark under several scenarios.
Read more9/24/2024

0
EMDFNet: Efficient Multi-scale and Diverse Feature Network for Traffic Sign Detection
Pengyu Li, Chenhe Liu, Tengfei Li, Xinyu Wang, Shihui Zhang, Dongyang Yu
The detection of small objects, particularly traffic signs, is a critical subtask within object detection and autonomous driving. Despite the notable achievements in previous research, two primary challenges persist. Firstly, the main issue is the singleness of feature extraction. Secondly, the detection process fails to effectively integrate with objects of varying sizes or scales. These issues are also prevalent in generic object detection. Motivated by these challenges, in this paper, we propose a novel object detection network named Efficient Multi-scale and Diverse Feature Network (EMDFNet) for traffic sign detection that integrates an Augmented Shortcut Module and an Efficient Hybrid Encoder to address the aforementioned issues simultaneously. Specifically, the Augmented Shortcut Module utilizes multiple branches to integrate various spatial semantic information and channel semantic information, thereby enhancing feature diversity. The Efficient Hybrid Encoder utilizes global feature fusion and local feature interaction based on various features to generate distinctive classification features by integrating feature information in an adaptable manner. Extensive experiments on the Tsinghua-Tencent 100K (TT100K) benchmark and the German Traffic Sign Detection Benchmark (GTSDB) demonstrate that our EMDFNet outperforms other state-of-the-art detectors in performance while retaining the real-time processing capabilities of single-stage models. This substantiates the effectiveness of EMDFNet in detecting small traffic signs.
Read more8/27/2024

0
Cross-domain Few-shot In-context Learning for Enhancing Traffic Sign Recognition
Yaozong Gan, Guang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
Recent multimodal large language models (MLLM) such as GPT-4o and GPT-4v have shown great potential in autonomous driving. In this paper, we propose a cross-domain few-shot in-context learning method based on the MLLM for enhancing traffic sign recognition (TSR). We first construct a traffic sign detection network based on Vision Transformer Adapter and an extraction module to extract traffic signs from the original road images. To reduce the dependence on training data and improve the performance stability of cross-country TSR, we introduce a cross-domain few-shot in-context learning method based on the MLLM. To enhance MLLM's fine-grained recognition ability of traffic signs, the proposed method generates corresponding description texts using template traffic signs. These description texts contain key information about the shape, color, and composition of traffic signs, which can stimulate the ability of MLLM to perceive fine-grained traffic sign categories. By using the description texts, our method reduces the cross-domain differences between template and real traffic signs. Our approach requires only simple and uniform textual indications, without the need for large-scale traffic sign images and labels. We perform comprehensive evaluations on the German traffic sign recognition benchmark dataset, the Belgium traffic sign dataset, and two real-world datasets taken from Japan. The experimental results show that our method significantly enhances the TSR performance.
Read more7/9/2024
🔎
0
Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
Yuqian Fu, Yu Wang, Yixuan Pan, Lian Huai, Xingyu Qiu, Zeyu Shangguan, Tong Liu, Yanwei Fu, Luc Van Gool, Xingqun Jiang
This paper studies the challenging cross-domain few-shot object detection (CD-FSOD), aiming to develop an accurate object detector for novel domains with minimal labeled examples. While transformer-based open-set detectors, such as DE-ViT, show promise in traditional few-shot object detection, their generalization to CD-FSOD remains unclear: 1) can such open-set detection methods easily generalize to CD-FSOD? 2) If not, how can models be enhanced when facing huge domain gaps? To answer the first question, we employ measures including style, inter-class variance (ICV), and indefinable boundaries (IB) to understand the domain gap. Based on these measures, we establish a new benchmark named CD-FSOD to evaluate object detection methods, revealing that most of the current approaches fail to generalize across domains. Technically, we observe that the performance decline is associated with our proposed measures: style, ICV, and IB. Consequently, we propose several novel modules to address these issues. First, the learnable instance features align initial fixed instances with target categories, enhancing feature distinctiveness. Second, the instance reweighting module assigns higher importance to high-quality instances with slight IB. Third, the domain prompter encourages features resilient to different styles by synthesizing imaginary domains without altering semantic contents. These techniques collectively contribute to the development of the Cross-Domain Vision Transformer for CD-FSOD (CD-ViTO), significantly improving upon the base DE-ViT. Experimental results validate the efficacy of our model.
Read more7/17/2024