FusionANNS: An Efficient CPU/GPU Cooperative Processing Architecture for Billion-scale Approximate Nearest Neighbor Search

0
Sign in to get full access
Overview
- FusionANNS is an efficient CPU/GPU cooperative processing architecture for billion-scale approximate nearest neighbor search (ANNS)
- It leverages the strengths of both CPUs and GPUs to achieve high performance and scalability
- The paper presents the design and implementation of FusionANNS, along with a comprehensive evaluation on large-scale datasets
Plain English Explanation
FusionANNS is a new system that combines the processing power of both CPUs and GPUs to quickly find the nearest neighbors for very large datasets.
Imagine you have a huge collection of images, and you want to find the images that are most similar to a given query image. This is called approximate nearest neighbor search, and it's a common task in many AI and data analysis applications.
Traditionally, this kind of search has been done using either CPUs or GPUs, but FusionANNS takes a different approach. It divides the work between the CPU and GPU, with the CPU handling the high-level coordination and the GPU doing the intensive computations. This allows FusionANNS to take advantage of the strengths of both types of hardware, resulting in much faster search times compared to using just a CPU or just a GPU.
The key insight behind FusionANNS is that the CPU and GPU can work together in a way that minimizes the amount of data that needs to be transferred between them. This reduces the overall processing time and makes the system more efficient. The paper also describes some clever techniques for organizing and partitioning the data to further improve the performance of the system.
Technical Explanation
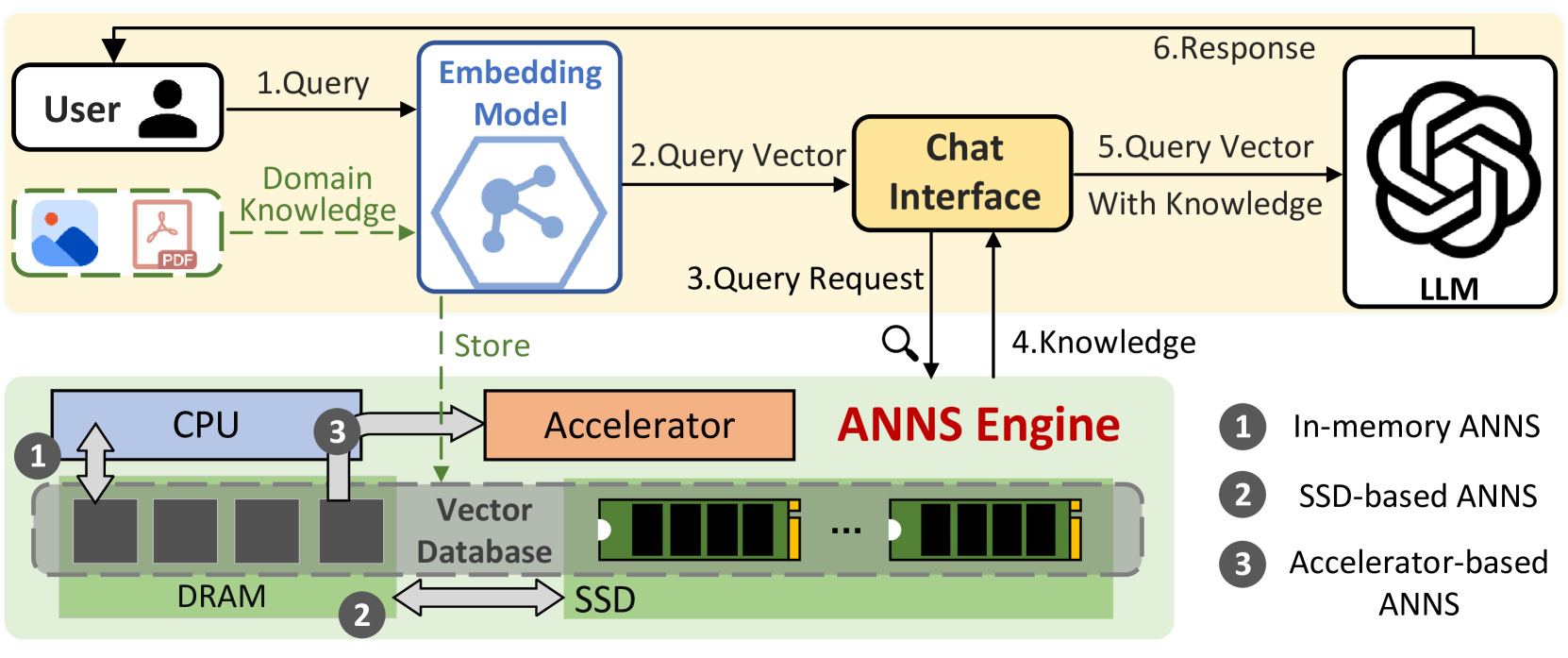
FusionANNS is a novel CPU/GPU cooperative processing architecture for performing approximate nearest neighbor search (ANNS) on billion-scale datasets.
The key idea behind FusionANNS is to leverage the strengths of both CPUs and GPUs in a complementary manner. The CPU handles the high-level coordination and task scheduling, while the GPU performs the computationally intensive operations required for the ANNS algorithm.
To achieve this, FusionANNS employs several innovative techniques:
- Adaptive Task Partitioning: FusionANNS dynamically partitions the ANNS tasks between the CPU and GPU based on their respective capabilities and the characteristics of the input data. This allows it to adapt to different workloads and hardware configurations.
- Efficient Data Management: FusionANNS uses a novel data organization and transfer scheme to minimize the amount of data that needs to be moved between the CPU and GPU, reducing the overall latency.
- Asynchronous Execution: The CPU and GPU operate asynchronously, overlapping their computations to maximize the overall system throughput.
The paper provides a detailed evaluation of FusionANNS on large-scale datasets, demonstrating its ability to outperform state-of-the-art ANNS systems by a significant margin in terms of both query latency and overall throughput.
Critical Analysis
The FusionANNS paper presents a compelling solution for tackling the challenge of billion-scale approximate nearest neighbor search. By leveraging the complementary strengths of CPUs and GPUs, the system is able to achieve high performance and scalability.
One potential limitation of the approach is the complexity of the system design and the need for careful tuning to balance the workload between the CPU and GPU. The paper does not provide much detail on the process of determining the optimal task partitioning and data management strategies, which could be an area for further research.
Additionally, the evaluation is primarily focused on query latency and throughput, but it would be interesting to see an analysis of the energy efficiency and resource utilization of the FusionANNS system compared to alternative approaches. This could be important for real-world deployment scenarios where power and cost constraints are critical.
Overall, the FusionANNS paper presents a promising contribution to the field of large-scale approximate nearest neighbor search, and the ideas presented could potentially be applied to other domains that require efficient cross-modal retrieval, such as image-text matching.
Conclusion
FusionANNS is an innovative CPU/GPU cooperative processing architecture that addresses the challenge of performing approximate nearest neighbor search on billion-scale datasets. By leveraging the strengths of both CPUs and GPUs, the system is able to achieve high performance and scalability, outperforming state-of-the-art ANNS solutions.
The key contributions of the FusionANNS system include its adaptive task partitioning, efficient data management, and asynchronous execution, which collectively enable it to minimize the overhead of data transfer and maximize the overall system throughput. While the system design is complex, the potential benefits of this approach make it an exciting development in the field of large-scale approximate nearest neighbor search and cross-modal retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FusionANNS: An Efficient CPU/GPU Cooperative Processing Architecture for Billion-scale Approximate Nearest Neighbor Search
Bing Tian, Haikun Liu, Yuhang Tang, Shihai Xiao, Zhuohui Duan, Xiaofei Liao, Xuecang Zhang, Junhua Zhu, Yu Zhang
Approximate nearest neighbor search (ANNS) has emerged as a crucial component of database and AI infrastructure. Ever-increasing vector datasets pose significant challenges in terms of performance, cost, and accuracy for ANNS services. None of modern ANNS systems can address these issues simultaneously. We present FusionANNS, a high-throughput, low-latency, cost-efficient, and high-accuracy ANNS system for billion-scale datasets using SSDs and only one entry-level GPU. The key idea of FusionANNS lies in CPU/GPU collaborative filtering and re-ranking mechanisms, which significantly reduce I/O operations across CPUs, GPU, and SSDs to break through the I/O performance bottleneck. Specifically, we propose three novel designs: (1) multi-tiered indexing to avoid data swapping between CPUs and GPU, (2) heuristic re-ranking to eliminate unnecessary I/Os and computations while guaranteeing high accuracy, and (3) redundant-aware I/O deduplication to further improve I/O efficiency. We implement FusionANNS and compare it with the state-of-the-art SSD-based ANNS system--SPANN and GPU-accelerated in-memory ANNS system--RUMMY. Experimental results show that FusionANNS achieves 1) 9.4-13.1X higher query per second (QPS) and 5.7-8.8X higher cost efficiency compared with SPANN; 2) and 2-4.9X higher QPS and 2.3-6.8X higher cost efficiency compared with RUMMY, while guaranteeing low latency and high accuracy.
Read more9/26/2024

0
BANG: Billion-Scale Approximate Nearest Neighbor Search using a Single GPU
Karthik V., Saim Khan, Somesh Singh, Harsha Vardhan Simhadri, Jyothi Vedurada
Approximate Nearest Neighbour Search (ANNS) is a subroutine in algorithms routinely employed in information retrieval, pattern recognition, data mining, image processing, and beyond. Recent works have established that graph-based ANNS algorithms are practically more efficient than the other methods proposed in the literature. The growing volume and dimensionality of data necessitates designing scalable techniques for ANNS. To this end, the prior art has explored parallelizing graph-based ANNS on GPU leveraging its massive parallelism. The current state-of-the-art GPU-based ANNS algorithms either (i) require both the dataset and the generated graph index to reside entirely in the GPU memory, or (ii) they partition the dataset into small independent shards, each of which can fit in GPU memory, and perform the search on these shards on the GPU. While the first approach fails to handle large datasets due to the limited memory available on the GPU, the latter delivers poor performance on large datasets due to high data traffic over the low-bandwidth PCIe bus. We introduce BANG, a first-of-its-kind technique for graph-based ANNS on GPU for billion-scale datasets that cannot entirely fit in the GPU memory. BANG stands out by harnessing a compressed form of the dataset on a single GPU to perform distance computations while efficiently accessing the graph index kept on the host memory, enabling efficient ANNS on large graphs within the limited GPU memory. BANG incorporates highly optimized GPU kernels and proceeds in phases that run concurrently on the GPU and CPU. Notably, on the billion-size datasets, we achieve throughputs 40x-200x more than the competing methods for a high recall value of 0.9. Additionally, BANG is the best in cost- and power-efficiency among the competing methods from the recent Billion-Scale Approximate Nearest Neighbour Search Challenge.
Read more7/22/2024

0
A Real-Time Adaptive Multi-Stream GPU System for Online Approximate Nearest Neighborhood Search
Yiping Sun, Yang Shi, Jiaolong Du
In recent years, Approximate Nearest Neighbor Search (ANNS) has played a pivotal role in modern search and recommendation systems, especially in emerging LLM applications like Retrieval-Augmented Generation. There is a growing exploration into harnessing the parallel computing capabilities of GPUs to meet the substantial demands of ANNS. However, existing systems primarily focus on offline scenarios, overlooking the distinct requirements of online applications that necessitate real-time insertion of new vectors. This limitation renders such systems inefficient for real-world scenarios. Moreover, previous architectures struggled to effectively support real-time insertion due to their reliance on serial execution streams. In this paper, we introduce a novel Real-Time Adaptive Multi-Stream GPU ANNS System (RTAMS-GANNS). Our architecture achieves its objectives through three key advancements: 1) We initially examined the real-time insertion mechanisms in existing GPU ANNS systems and discovered their reliance on repetitive copying and memory allocation, which significantly hinders real-time effectiveness on GPUs. As a solution, we introduce a dynamic vector insertion algorithm based on memory blocks, which includes in-place rearrangement. 2) To enable real-time vector insertion in parallel, we introduce a multi-stream parallel execution mode, which differs from existing systems that operate serially within a single stream. Our system utilizes a dynamic resource pool, allowing multiple streams to execute concurrently without additional execution blocking. 3) Through extensive experiments and comparisons, our approach effectively handles varying QPS levels across different datasets, reducing latency by up to 40%-80%. The proposed system has also been deployed in real-world industrial search and recommendation systems, serving hundreds of millions of users daily, and has achieved good results.
Read more8/7/2024
🧪
0
CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs
Hiroyuki Ootomo, Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, Yong Wang
Approximate Nearest Neighbor Search (ANNS) plays a critical role in various disciplines spanning data mining and artificial intelligence, from information retrieval and computer vision to natural language processing and recommender systems. Data volumes have soared in recent years and the computational cost of an exhaustive exact nearest neighbor search is often prohibitive, necessitating the adoption of approximate techniques. The balanced performance and recall of graph-based approaches have more recently garnered significant attention in ANNS algorithms, however, only a few studies have explored harnessing the power of GPUs and multi-core processors despite the widespread use of massively parallel and general-purpose computing. To bridge this gap, we introduce a novel parallel computing hardware-based proximity graph and search algorithm. By leveraging the high-performance capabilities of modern hardware, our approach achieves remarkable efficiency gains. In particular, our method surpasses existing CPU and GPU-based methods in constructing the proximity graph, demonstrating higher throughput in both large- and small-batch searches while maintaining compatible accuracy. In graph construction time, our method, CAGRA, is 2.2~27x faster than HNSW, which is one of the CPU SOTA implementations. In large-batch query throughput in the 90% to 95% recall range, our method is 33~77x faster than HNSW, and is 3.8~8.8x faster than the SOTA implementations for GPU. For a single query, our method is 3.4~53x faster than HNSW at 95% recall.
Read more7/10/2024