GANmut: Generating and Modifying Facial Expressions
2406.11079
0
0
Abstract
In the realm of emotion synthesis, the ability to create authentic and nuanced facial expressions continues to gain importance. The GANmut study discusses a recently introduced advanced GAN framework that, instead of relying on predefined labels, learns a dynamic and interpretable emotion space. This methodology maps each discrete emotion as vectors starting from a neutral state, their magnitude reflecting the emotion's intensity. The current project aims to extend the study of this framework by benchmarking across various datasets, image resolutions, and facial detection methodologies. This will involve conducting a series of experiments using two emotional datasets: Aff-Wild2 and AffNet. Aff-Wild2 contains videos captured in uncontrolled environments, which include diverse camera angles, head positions, and lighting conditions, providing a real-world challenge. AffNet offers images with labelled emotions, improving the diversity of emotional expressions available for training. The first two experiments will focus on training GANmut using the Aff-Wild2 dataset, processed with either RetinaFace or MTCNN, both of which are high-performance deep learning face detectors. This setup will help determine how well GANmut can learn to synthesise emotions under challenging conditions and assess the comparative effectiveness of these face detection technologies. The subsequent two experiments will merge the Aff-Wild2 and AffNet datasets, combining the real world variability of Aff-Wild2 with the diverse emotional labels of AffNet. The same face detectors, RetinaFace and MTCNN, will be employed to evaluate whether the enhanced diversity of the combined datasets improves GANmut's performance and to compare the impact of each face detection method in this hybrid setup.
Create account to get full access
Overview
- This paper introduces a novel generative adversarial network (GAN) called GANmut that can generate and modify facial expressions.
- The system is able to generate photorealistic facial expressions from a neutral face, as well as perform expression transfer, where the expression of one face is applied to another.
- The authors demonstrate the capabilities of GANmut on a range of facial expressions and show that it outperforms state-of-the-art methods in terms of both generation and transfer quality.
Plain English Explanation
The researchers have developed a new artificial intelligence (AI) system called GANmut that can create and change facial expressions in images. GANmut uses a type of AI called a generative adversarial network (GAN) to generate highly realistic facial expressions.
With GANmut, the researchers can start with a neutral face and generate a range of different emotional expressions, like happiness, sadness, or anger. They can also take one person's face and apply a different expression to it, like transferring a smile from one face to another.
Compared to previous methods, GANmut is able to produce more natural and convincing facial expressions. This could have applications in areas like computer animation, virtual reality, and human-computer interaction, where realistic facial expressions are important.
Technical Explanation
The core of GANmut is a generative adversarial network (GAN) architecture. The generator component of the GAN is trained to take a neutral face as input and generate a photorealistic facial expression. The discriminator component is trained to distinguish between real and generated facial expressions.
Through this adversarial training process, the generator learns to produce increasingly realistic and diverse facial expressions. The authors also incorporate additional techniques, such as landmark-guided generation and expression disentanglement, to improve the quality and controllability of the generated expressions.
To enable expression transfer, the researchers use a second GAN that takes the source and target faces as input and learns to apply the expression from the source to the target. This allows the system to transfer a wide range of expressions between different individuals.
The authors evaluate GANmut on several facial expression benchmarks and show that it outperforms state-of-the-art methods in terms of both generation and transfer quality. They also demonstrate the system's ability to generate emotional expressions and apply them to various face images.
Critical Analysis
The paper presents a compelling and technically sophisticated approach to generating and modifying facial expressions using GANs. The authors have made several notable contributions, such as the use of landmark guidance and expression disentanglement, which help improve the realism and controllability of the generated expressions.
However, the paper does not address some potential limitations or areas for further research. For example, the system's performance may be sensitive to the diversity and quality of the training data, and it is unclear how well it would generalize to more diverse or challenging facial expressions or identities.
Additionally, while the authors demonstrate the system's capabilities, they do not explore the potential ethical implications of being able to generate and manipulate facial expressions so convincingly. This is an important consideration, as such technologies could be misused for deceptive or harmful purposes.
Further research could investigate ways to ensure the responsible development and deployment of such systems, such as through the use of watermarking or other safeguards to prevent misuse.
Conclusion
The GANmut system presented in this paper represents a significant advance in the field of facial expression generation and modification. By leveraging the power of generative adversarial networks, the researchers have developed a system capable of producing highly realistic and controllable facial expressions.
The potential applications of this technology are wide-ranging, from computer animation and virtual reality to human-computer interaction and social robotics. However, it is crucial that the development of such systems be accompanied by careful consideration of the ethical implications and appropriate safeguards to prevent misuse.
As the field of AI continues to progress, it will be important for researchers, developers, and policymakers to work together to ensure that these powerful technologies are used in a responsible and beneficial manner for society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluation and Comparison of Emotionally Evocative Image Augmentation Methods
Jan Ignatowicz, Krzysztof Kutt, Grzegorz J. Nalepa
0
0
Experiments in affective computing are based on stimulus datasets that, in the process of standardization, receive metadata describing which emotions each stimulus evokes. In this paper, we explore an approach to creating stimulus datasets for affective computing using generative adversarial networks (GANs). Traditional dataset preparation methods are costly and time consuming, prompting our investigation of alternatives. We conducted experiments with various GAN architectures, including Deep Convolutional GAN, Conditional GAN, Auxiliary Classifier GAN, Progressive Augmentation GAN, and Wasserstein GAN, alongside data augmentation and transfer learning techniques. Our findings highlight promising advances in the generation of emotionally evocative synthetic images, suggesting significant potential for future research and improvements in this domain.
6/26/2024

Emotional Conversation: Empowering Talking Faces with Cohesive Expression, Gaze and Pose Generation
Jiadong Liang, Feng Lu
0
0
Vivid talking face generation holds immense potential applications across diverse multimedia domains, such as film and game production. While existing methods accurately synchronize lip movements with input audio, they typically ignore crucial alignments between emotion and facial cues, which include expression, gaze, and head pose. These alignments are indispensable for synthesizing realistic videos. To address these issues, we propose a two-stage audio-driven talking face generation framework that employs 3D facial landmarks as intermediate variables. This framework achieves collaborative alignment of expression, gaze, and pose with emotions through self-supervised learning. Specifically, we decompose this task into two key steps, namely speech-to-landmarks synthesis and landmarks-to-face generation. The first step focuses on simultaneously synthesizing emotionally aligned facial cues, including normalized landmarks that represent expressions, gaze, and head pose. These cues are subsequently reassembled into relocated facial landmarks. In the second step, these relocated landmarks are mapped to latent key points using self-supervised learning and then input into a pretrained model to create high-quality face images. Extensive experiments on the MEAD dataset demonstrate that our model significantly advances the state-of-the-art performance in both visual quality and emotional alignment.
6/13/2024

eMotion-GAN: A Motion-based GAN for Photorealistic and Facial Expression Preserving Frontal View Synthesis
Omar Ikne, Benjamin Allaert, Ioan Marius Bilasco, Hazem Wannous
0
0
Many existing facial expression recognition (FER) systems encounter substantial performance degradation when faced with variations in head pose. Numerous frontalization methods have been proposed to enhance these systems' performance under such conditions. However, they often introduce undesirable deformations, rendering them less suitable for precise facial expression analysis. In this paper, we present eMotion-GAN, a novel deep learning approach designed for frontal view synthesis while preserving facial expressions within the motion domain. Considering the motion induced by head variation as noise and the motion induced by facial expression as the relevant information, our model is trained to filter out the noisy motion in order to retain only the motion related to facial expression. The filtered motion is then mapped onto a neutral frontal face to generate the corresponding expressive frontal face. We conducted extensive evaluations using several widely recognized dynamic FER datasets, which encompass sequences exhibiting various degrees of head pose variations in both intensity and orientation. Our results demonstrate the effectiveness of our approach in significantly reducing the FER performance gap between frontal and non-frontal faces. Specifically, we achieved a FER improvement of up to +5% for small pose variations and up to +20% improvement for larger pose variations. Code available at url{https://github.com/o-ikne/eMotion-GAN.git}.
4/16/2024
EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos Vougioukas, Zoe Landgraf, Stavros Petridis, Maja Pantic
0
0
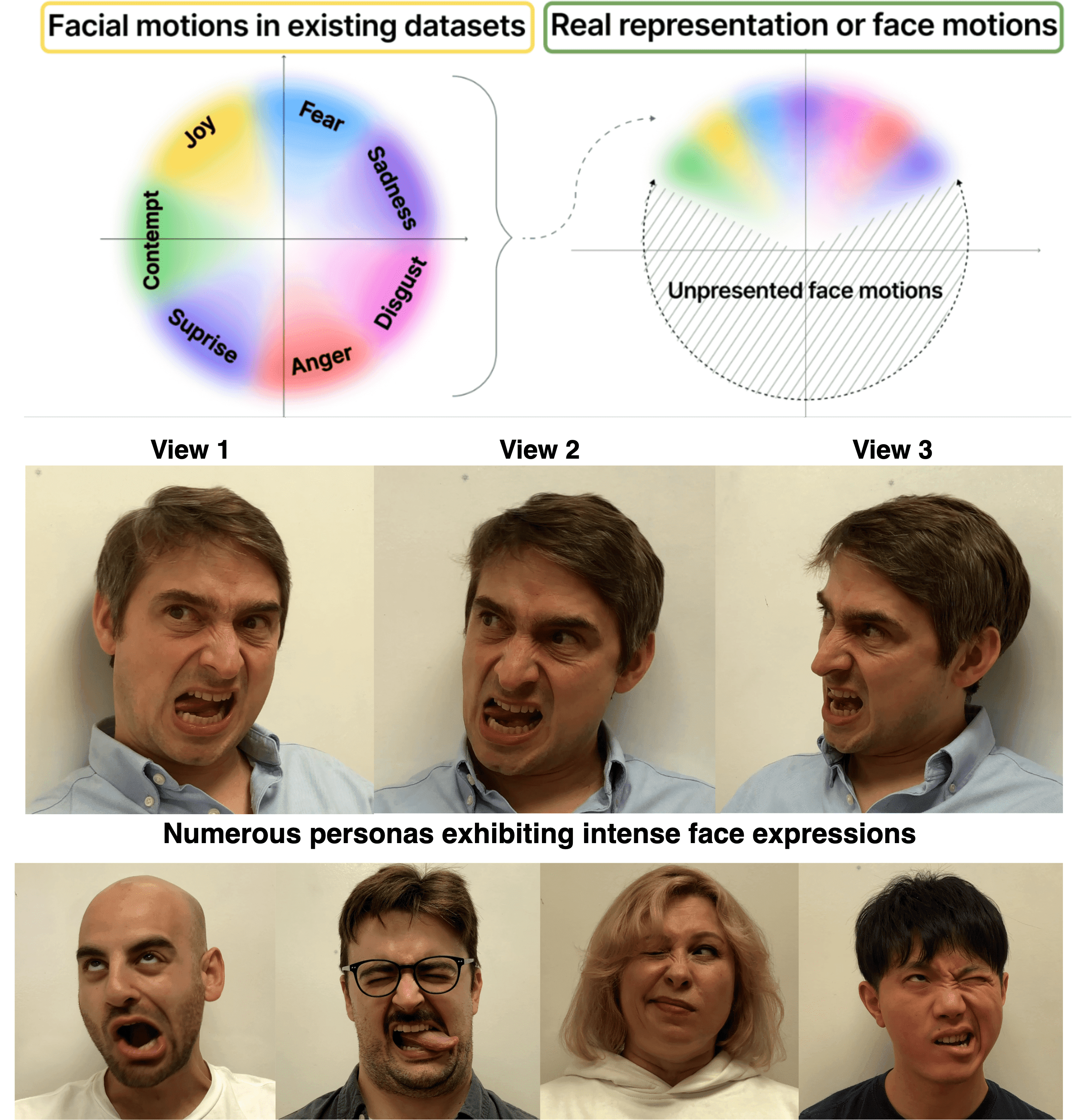
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model's capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
5/1/2024