EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
2404.19110
0
0
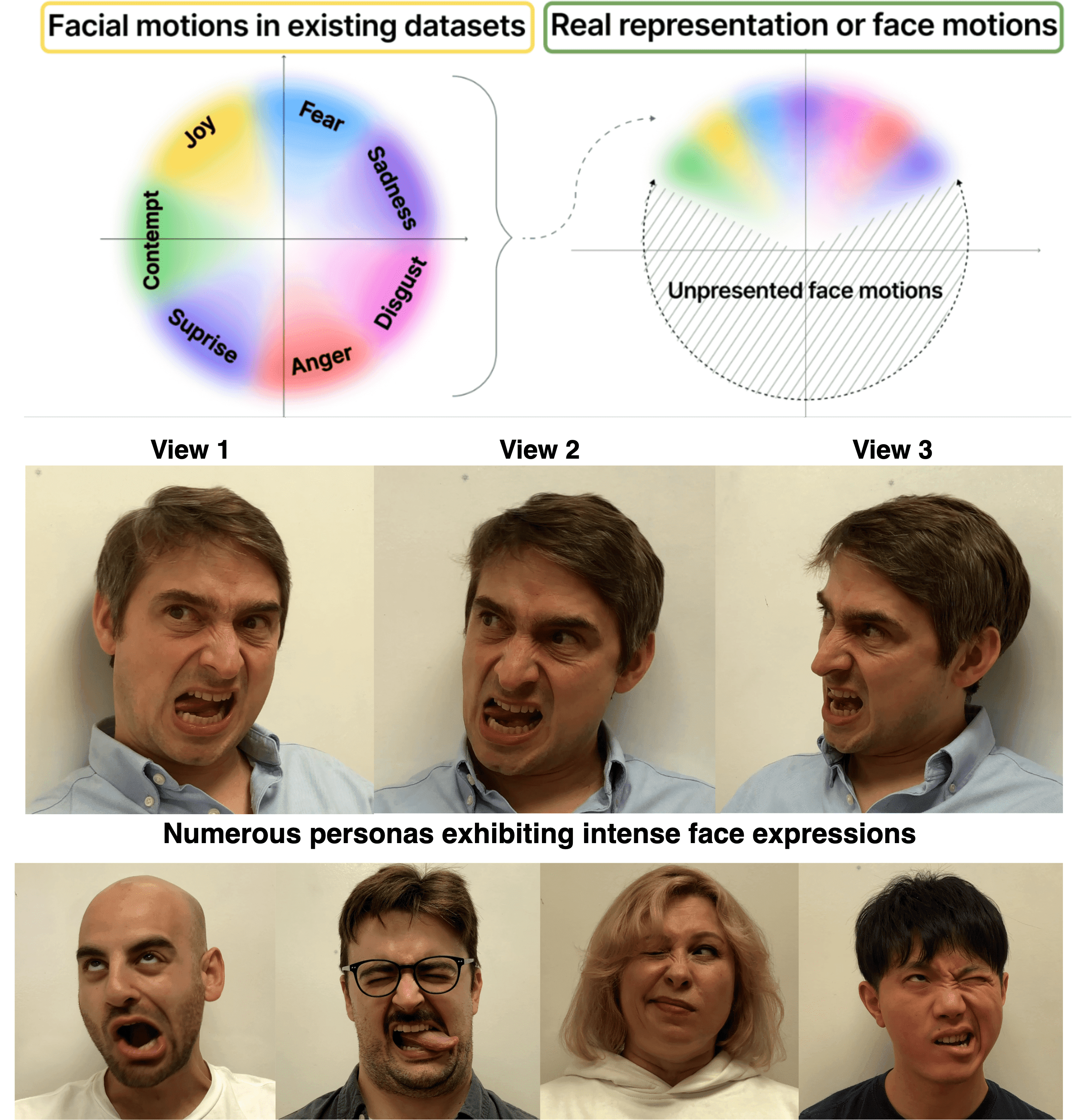
Abstract
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model's capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
Create account to get full access
Overview
- This paper presents EMOPortraits, a system for generating emotion-enhanced multimodal one-shot head avatars.
- EMOPortraits can create personalized 3D head avatars from a single image and control the avatar's facial expressions and emotions.
- The system combines several state-of-the-art technologies, including Towards Simultaneous Granular Identity and Expression Control for Personalized Avatars, GenEAvatar: Generic Expression-Aware Volumetric Head Avatar, and Emotion-GAN: Motion-based GAN for Photorealistic Facial Animations.
Plain English Explanation
The paper introduces EMOPortraits, a system that can create 3D head avatars of people from a single photo. These avatars can then be animated to show different facial expressions and emotions. The key idea is to combine several existing technologies to build a more comprehensive system for generating personalized, emotion-enhanced avatars.
The system takes a single photo of a person's face and uses it to create a 3D model of their head. It can then control the facial expressions and emotions shown by the avatar, allowing it to convey different moods and feelings. This could be useful for things like virtual communication, gaming, or even digital assistants that can show appropriate emotional responses.
The paper builds on previous work in areas like simultaneous control of identity and expression, generic expression-aware head avatars, and photorealistic facial animation. By combining these technologies, the authors create a more comprehensive system for generating personalized, emotion-enhanced avatars from a single photo.
Technical Explanation
The EMOPortraits system consists of several key components. First, it uses a one-shot learning approach to create a 3D head model from a single input image, building on the GenEAvatar system. This allows the system to generate a personalized 3D head avatar without requiring extensive training data.
To control the facial expressions and emotions of the avatar, EMOPortraits integrates an Emotion-GAN model. This GAN-based system can generate photorealistic facial animations driven by motion capture data, allowing for detailed control over the avatar's emotional expressions.
Finally, the system also incorporates techniques from Towards Simultaneous Granular Identity and Expression Control for Personalized Avatars to enable independent control over the avatar's identity and expression. This allows the user to adjust the avatar's facial features and emotions independently, resulting in more nuanced and expressive avatars.
The authors evaluate EMOPortraits through both quantitative and qualitative experiments, demonstrating its ability to generate high-quality, emotion-enhanced avatars from single-shot input. They also discuss potential applications in areas like virtual communication, gaming, and digital assistants.
Critical Analysis
The EMOPortraits system represents an impressive advancement in the field of avatar generation and animation. By combining several state-of-the-art technologies, the authors have created a comprehensive solution for generating personalized, emotion-enhanced head avatars from a single input image.
One potential limitation of the system is that it relies on pre-existing datasets of facial expressions and motion capture data. While the authors demonstrate that their approach can generate realistic animations, the emotional range and nuance of the avatars may be constrained by the available training data. Expanding the diversity and complexity of the training data could be an area for future research.
Additionally, the paper does not address potential privacy and ethical concerns around the use of such personalized avatars. As these technologies become more advanced and widely adopted, it will be important to consider how they can be deployed responsibly and with appropriate safeguards, particularly in sensitive applications like virtual communication or digital assistants.
Overall, the EMOPortraits system represents an exciting development in the field of avatar generation and animation. By enabling the creation of emotion-enhanced, personalized head avatars from a single image, the authors have pushed the boundaries of what is possible in this domain. As the technology continues to evolve, it will be important to address any limitations and carefully consider the societal implications of such advancements.
Conclusion
The EMOPortraits system presented in this paper is a significant advancement in the field of avatar generation and animation. By combining state-of-the-art technologies for 3D head modeling, facial animation, and emotion control, the authors have created a comprehensive system for generating personalized, emotion-enhanced head avatars from a single input image.
The ability to control the avatar's facial expressions and emotional states independently opens up a wide range of potential applications, from virtual communication and gaming to digital assistants and interactive experiences. As these technologies continue to evolve, it will be important to address any limitations and carefully consider the societal implications of such advancements.
Overall, the EMOPortraits system represents an exciting step forward in the field of avatar generation, with the potential to enable more natural, expressive, and personalized digital representations of individuals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Emotional Conversation: Empowering Talking Faces with Cohesive Expression, Gaze and Pose Generation
Jiadong Liang, Feng Lu
0
0
Vivid talking face generation holds immense potential applications across diverse multimedia domains, such as film and game production. While existing methods accurately synchronize lip movements with input audio, they typically ignore crucial alignments between emotion and facial cues, which include expression, gaze, and head pose. These alignments are indispensable for synthesizing realistic videos. To address these issues, we propose a two-stage audio-driven talking face generation framework that employs 3D facial landmarks as intermediate variables. This framework achieves collaborative alignment of expression, gaze, and pose with emotions through self-supervised learning. Specifically, we decompose this task into two key steps, namely speech-to-landmarks synthesis and landmarks-to-face generation. The first step focuses on simultaneously synthesizing emotionally aligned facial cues, including normalized landmarks that represent expressions, gaze, and head pose. These cues are subsequently reassembled into relocated facial landmarks. In the second step, these relocated landmarks are mapped to latent key points using self-supervised learning and then input into a pretrained model to create high-quality face images. Extensive experiments on the MEAD dataset demonstrate that our model significantly advances the state-of-the-art performance in both visual quality and emotional alignment.
6/13/2024
🔮
MegActor: Harness the Power of Raw Video for Vivid Portrait Animation
Shurong Yang, Huadong Li, Juhao Wu, Minhao Jing, Linze Li, Renhe Ji, Jiajun Liang, Haoqiang Fan
0
0
Despite raw driving videos contain richer information on facial expressions than intermediate representations such as landmarks in the field of portrait animation, they are seldom the subject of research. This is due to two challenges inherent in portrait animation driven with raw videos: 1) significant identity leakage; 2) Irrelevant background and facial details such as wrinkles degrade performance. To harnesses the power of the raw videos for vivid portrait animation, we proposed a pioneering conditional diffusion model named as MegActor. First, we introduced a synthetic data generation framework for creating videos with consistent motion and expressions but inconsistent IDs to mitigate the issue of ID leakage. Second, we segmented the foreground and background of the reference image and employed CLIP to encode the background details. This encoded information is then integrated into the network via a text embedding module, thereby ensuring the stability of the background. Finally, we further style transfer the appearance of the reference image to the driving video to eliminate the influence of facial details in the driving videos. Our final model was trained solely on public datasets, achieving results comparable to commercial models. We hope this will help the open-source community.The code is available at https://github.com/megvii-research/MegFaceAnimate.
6/19/2024

GMTalker: Gaussian Mixture-based Audio-Driven Emotional talking video Portraits
Yibo Xia, Lizhen Wang, Xiang Deng, Xiaoyan Luo, Yebin Liu
0
0
Synthesizing high-fidelity and emotion-controllable talking video portraits, with audio-lip sync, vivid expressions, realistic head poses, and eye blinks, has been an important and challenging task in recent years. Most existing methods suffer in achieving personalized and precise emotion control, smooth transitions between different emotion states, and the generation of diverse motions. To tackle these challenges, we present GMTalker, a Gaussian mixture-based emotional talking portraits generation framework. Specifically, we propose a Gaussian mixture-based expression generator that can construct a continuous and disentangled latent space, achieving more flexible emotion manipulation. Furthermore, we introduce a normalizing flow-based motion generator pretrained on a large dataset with a wide-range motion to generate diverse head poses, blinks, and eyeball movements. Finally, we propose a personalized emotion-guided head generator with an emotion mapping network that can synthesize high-fidelity and faithful emotional video portraits. Both quantitative and qualitative experiments demonstrate our method outperforms previous methods in image quality, photo-realism, emotion accuracy, and motion diversity.
5/29/2024
GANmut: Generating and Modifying Facial Expressions
Maria Surani
0
0
In the realm of emotion synthesis, the ability to create authentic and nuanced facial expressions continues to gain importance. The GANmut study discusses a recently introduced advanced GAN framework that, instead of relying on predefined labels, learns a dynamic and interpretable emotion space. This methodology maps each discrete emotion as vectors starting from a neutral state, their magnitude reflecting the emotion's intensity. The current project aims to extend the study of this framework by benchmarking across various datasets, image resolutions, and facial detection methodologies. This will involve conducting a series of experiments using two emotional datasets: Aff-Wild2 and AffNet. Aff-Wild2 contains videos captured in uncontrolled environments, which include diverse camera angles, head positions, and lighting conditions, providing a real-world challenge. AffNet offers images with labelled emotions, improving the diversity of emotional expressions available for training. The first two experiments will focus on training GANmut using the Aff-Wild2 dataset, processed with either RetinaFace or MTCNN, both of which are high-performance deep learning face detectors. This setup will help determine how well GANmut can learn to synthesise emotions under challenging conditions and assess the comparative effectiveness of these face detection technologies. The subsequent two experiments will merge the Aff-Wild2 and AffNet datasets, combining the real world variability of Aff-Wild2 with the diverse emotional labels of AffNet. The same face detectors, RetinaFace and MTCNN, will be employed to evaluate whether the enhanced diversity of the combined datasets improves GANmut's performance and to compare the impact of each face detection method in this hybrid setup.
6/18/2024