Gaussian Stochastic Weight Averaging for Bayesian Low-Rank Adaptation of Large Language Models
2405.03425
0
0
💬
Abstract
Fine-tuned Large Language Models (LLMs) often suffer from overconfidence and poor calibration, particularly when fine-tuned on small datasets. To address these challenges, we propose a simple combination of Low-Rank Adaptation (LoRA) with Gaussian Stochastic Weight Averaging (SWAG), facilitating approximate Bayesian inference in LLMs. Through extensive testing across several Natural Language Processing (NLP) benchmarks, we demonstrate that our straightforward and computationally efficient approach improves model generalization and calibration. We further show that our method exhibits greater robustness against distribution shift, as reflected in its performance on out-of-distribution tasks.
Create account to get full access
Overview
- Fine-tuned large language models (LLMs) often suffer from overconfidence and poor calibration, especially when trained on small datasets.
- The researchers propose a combination of Low-Rank Adaptation (LoRA) and Gaussian Stochastic Weight Averaging (SWAG) to address these challenges.
- This approach facilitates approximate Bayesian inference in LLMs, improving model generalization and calibration.
- The method also exhibits greater robustness against distribution shift, performing better on out-of-distribution tasks.
Plain English Explanation
Large language models (LLMs) are powerful AI systems trained on vast amounts of text data to understand and generate human-like language. When these models are fine-tuned, or further trained, on smaller datasets, they can become overconfident in their predictions and struggle to properly quantify their uncertainty. This can lead to poor performance, especially when the model is tested on data that is different from what it was trained on.
To address these issues, the researchers combined two techniques: Low-Rank Adaptation (LoRA) and Gaussian Stochastic Weight Averaging (SWAG). LoRA is a method for efficiently fine-tuning LLMs by only updating a small number of parameters, which can help prevent overfitting. SWAG is a way of approximating Bayesian inference, a statistical technique that can better capture the model's uncertainty.
By using this combination of LoRA and SWAG, the researchers were able to create fine-tuned LLMs that were more accurate, better calibrated, and more robust to changes in the data distribution. In other words, the models were less likely to be overconfident in their predictions and more likely to perform well on new, unseen data.
Technical Explanation
The researchers proposed a simple yet effective approach to improve the generalization and calibration of fine-tuned LLMs. They combined Low-Rank Adaptation (LoRA) with Gaussian Stochastic Weight Averaging (SWAG) to facilitate approximate Bayesian inference in LLMs.
LoRA is a technique for efficiently fine-tuning large models by only updating a small subset of the model parameters. This helps prevent overfitting and maintains the model's original performance on its original tasks. NOLA, a compressed version of LoRA, was also explored.
SWAG is a method for approximating Bayesian inference, which can help the model better quantify its uncertainty. By combining LoRA and SWAG, the researchers were able to fine-tune LLMs in a way that improved both their generalization and calibration.
The researchers evaluated their approach on several natural language processing (NLP) benchmarks, including text classification, question answering, and natural language inference tasks. They found that their method outperformed standard fine-tuning techniques in terms of model performance, calibration, and robustness to distribution shift.
Critical Analysis
The researchers provide a thorough evaluation of their proposed approach, testing it across a range of NLP tasks and benchmarks. However, the paper does not address some potential limitations or areas for further research.
For example, the experiments were conducted on a limited set of LLM architectures and datasets. It would be valuable to see how the method performs on a wider range of models and tasks, especially in more real-world, application-specific settings.
Additionally, the paper does not delve into the computational and memory requirements of the combined LoRA and SWAG approach. This information would be useful for practitioners considering the trade-offs between performance improvements and computational costs.
While the researchers demonstrate the method's robustness to distribution shift, further investigation into the underlying reasons for this improved performance would be of interest. Understanding the specific mechanisms by which the approach enhances out-of-distribution generalization could lead to additional insights and improvements.
Overall, the researchers have presented a compelling and practical solution to the challenge of overconfidence and poor calibration in fine-tuned LLMs. Continued exploration of this approach, as well as its limitations and potential refinements, could yield valuable advancements in the field of large language model development and deployment.
Conclusion
The researchers have developed a simple yet effective method to improve the generalization and calibration of fine-tuned large language models. By combining Low-Rank Adaptation (LoRA) and Gaussian Stochastic Weight Averaging (SWAG), they were able to create LLMs that were more accurate, better calibrated, and more robust to distribution shift.
This approach has the potential to significantly enhance the real-world applicability of large language models, as overconfidence and poor calibration can severely limit their usefulness in many practical scenarios. The researchers' work contributes to the ongoing efforts to develop more reliable and trustworthy AI systems, which is crucial for the broader adoption and responsible use of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
New!Adaptive Stochastic Weight Averaging
Caglar Demir, Arnab Sharma, Axel-Cyrille Ngonga Ngomo
0
0
Ensemble models often improve generalization performances in challenging tasks. Yet, traditional techniques based on prediction averaging incur three well-known disadvantages: the computational overhead of training multiple models, increased latency, and memory requirements at test time. To address these issues, the Stochastic Weight Averaging (SWA) technique maintains a running average of model parameters from a specific epoch onward. Despite its potential benefits, maintaining a running average of parameters can hinder generalization, as an underlying running model begins to overfit. Conversely, an inadequately chosen starting point can render SWA more susceptible to underfitting compared to an underlying running model. In this work, we propose Adaptive Stochastic Weight Averaging (ASWA) technique that updates a running average of model parameters, only when generalization performance is improved on the validation dataset. Hence, ASWA can be seen as a combination of SWA with the early stopping technique, where the former accepts all updates on a parameter ensemble model and the latter rejects any update on an underlying running model. We conducted extensive experiments ranging from image classification to multi-hop reasoning over knowledge graphs. Our experiments over 11 benchmark datasets with 7 baseline models suggest that ASWA leads to a statistically better generalization across models and datasets
6/28/2024

Personalized Collaborative Fine-Tuning for On-Device Large Language Models
Nicolas Wagner, Dongyang Fan, Martin Jaggi
0
0
We explore on-device self-supervised collaborative fine-tuning of large language models with limited local data availability. Taking inspiration from the collaborative learning community, we introduce three distinct trust-weighted gradient aggregation schemes: weight similarity-based, prediction similarity-based and validation performance-based. To minimize communication overhead, we integrate Low-Rank Adaptation (LoRA) and only exchange LoRA weight updates. Our protocols, driven by prediction and performance metrics, surpass both FedAvg and local fine-tuning methods, which is particularly evident in realistic scenarios with more diverse local data distributions. The results underscore the effectiveness of our approach in addressing heterogeneity and scarcity within local datasets.
4/16/2024
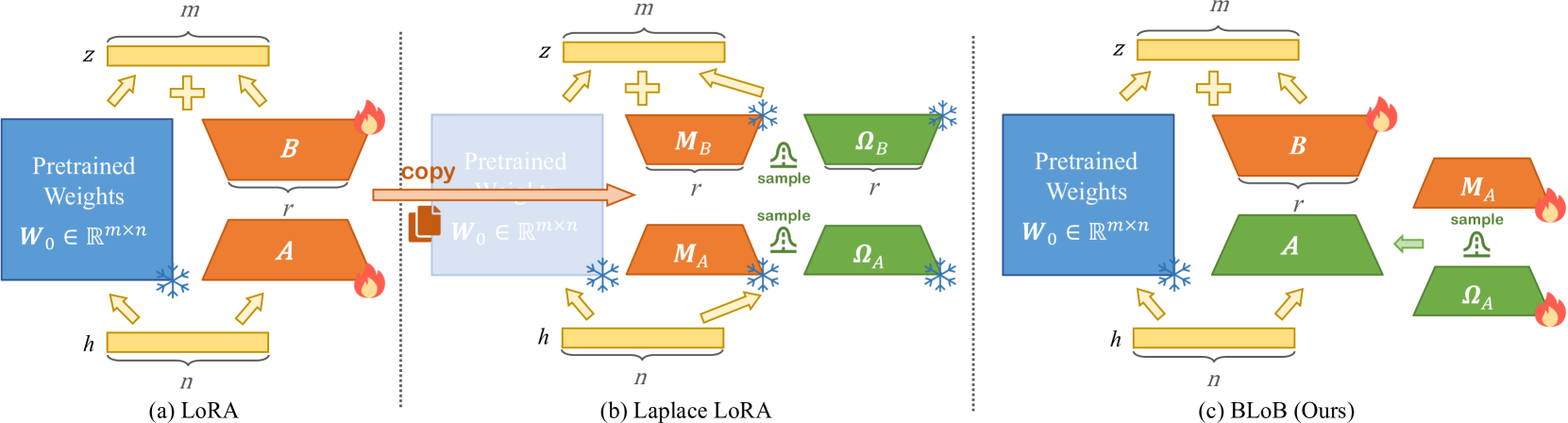
BLoB: Bayesian Low-Rank Adaptation by Backpropagation for Large Language Models
Yibin Wang, Haizhou Shi, Ligong Han, Dimitris Metaxas, Hao Wang
0
0
Large Language Models (LLMs) often suffer from overconfidence during inference, particularly when adapted to downstream domain-specific tasks with limited data. Previous work addresses this issue by employing approximate Bayesian estimation after the LLMs are trained, enabling them to quantify uncertainty. However, such post-training approaches' performance is severely limited by the parameters learned during training. In this paper, we go beyond post-training Bayesianization and propose Bayesian Low-Rank Adaptation by Backpropagation (BLoB), an algorithm that continuously and jointly adjusts both the mean and covariance of LLM parameters throughout the whole fine-tuning process. Our empirical results verify the effectiveness of BLoB in terms of generalization and uncertainty estimation, when evaluated on both in-distribution and out-of-distribution data.
6/19/2024

OLoRA: Orthonormal Low-Rank Adaptation of Large Language Models
Kerim Buyukakyuz
0
0
The advent of large language models (LLMs) has revolutionized natural language processing, enabling unprecedented capabilities in understanding and generating human-like text. However, the computational cost and convergence times associated with fine-tuning these models remain significant challenges. Low-Rank Adaptation (LoRA) has emerged as a promising method to mitigate these issues by introducing efficient fine-tuning techniques with a reduced number of trainable parameters. In this paper, we present OLoRA, an enhancement to the LoRA method that leverages orthonormal matrix initialization through QR decomposition. OLoRA significantly accelerates the convergence of LLM training while preserving the efficiency benefits of LoRA, such as the number of trainable parameters and GPU memory footprint. Our empirical evaluations demonstrate that OLoRA not only converges faster but also exhibits improved performance compared to standard LoRA across a variety of language modeling tasks. This advancement opens new avenues for more efficient and accessible fine-tuning of LLMs, potentially enabling broader adoption and innovation in natural language applications.
6/5/2024