BLoB: Bayesian Low-Rank Adaptation by Backpropagation for Large Language Models
2406.11675
0
0
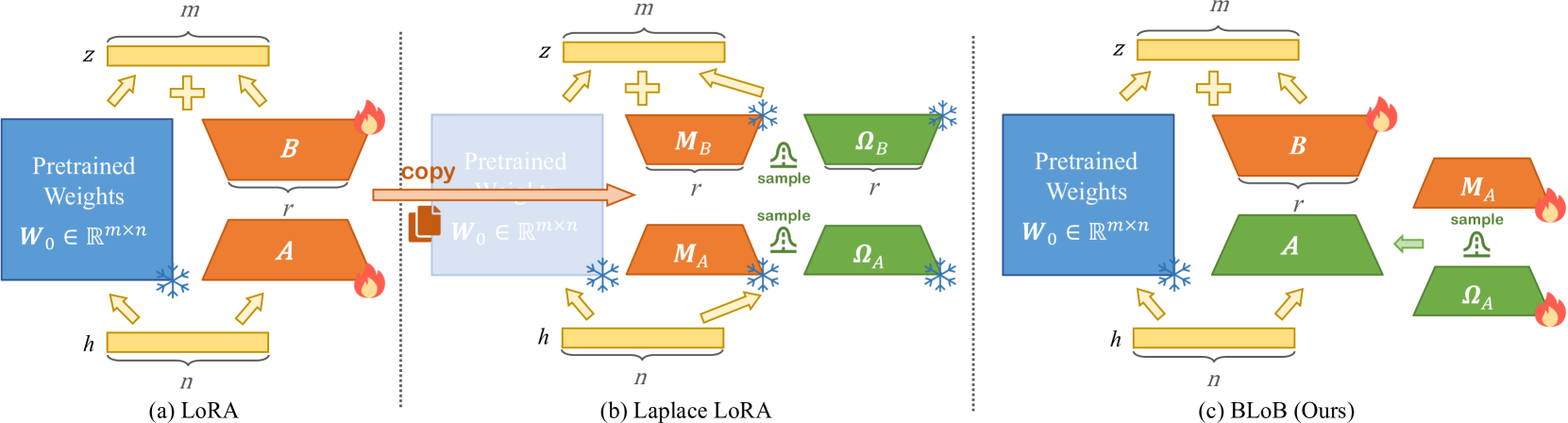
Abstract
Large Language Models (LLMs) often suffer from overconfidence during inference, particularly when adapted to downstream domain-specific tasks with limited data. Previous work addresses this issue by employing approximate Bayesian estimation after the LLMs are trained, enabling them to quantify uncertainty. However, such post-training approaches' performance is severely limited by the parameters learned during training. In this paper, we go beyond post-training Bayesianization and propose Bayesian Low-Rank Adaptation by Backpropagation (BLoB), an algorithm that continuously and jointly adjusts both the mean and covariance of LLM parameters throughout the whole fine-tuning process. Our empirical results verify the effectiveness of BLoB in terms of generalization and uncertainty estimation, when evaluated on both in-distribution and out-of-distribution data.
Create account to get full access
Overview
- This paper introduces BLoB (Bayesian Low-Rank Adaptation by Backpropagation), a novel technique for efficiently adapting large language models to specific tasks or domains.
- BLoB leverages a Bayesian low-rank parameterization to enable rapid task-specific fine-tuning, while maintaining the generalization capabilities of the original large model.
- The method allows for efficient adaptation without the need for costly full fine-tuning of the entire model, making it suitable for resource-constrained settings.
Plain English Explanation
BLoB is a new way to tailor large language models, like GPT-3 or BERT, to specific tasks or datasets. Large language models are powerful but can be costly and time-consuming to fully fine-tune for each new application. BLoB provides a more efficient solution by only fine-tuning a small subset of the model's parameters.
The key idea behind BLoB is to represent the task-specific adaptations using a low-rank matrix. This means that only a few parameters need to be updated, rather than the entire model. The low-rank approach allows the model to rapidly adapt to new tasks while still retaining the broad knowledge and capabilities of the original large language model.
BLoB uses a Bayesian framework to learn these task-specific low-rank adaptations. This Bayesian approach helps to prevent overfitting and ensures the adaptations are well-suited to the target task. The entire process is done through backpropagation, making it easy to implement and integrate into existing machine learning pipelines.
The efficiency of BLoB makes it particularly valuable for resource-constrained settings, such as on-device personalization or rapid adaptation to new domains. By only updating a small portion of the model, BLoB can fine-tune large language models much more quickly and with fewer computational resources than traditional fine-tuning approaches.
Technical Explanation
BLoB builds on previous work in Adaptive Robust Learning Using Latent Bernoulli Variables, Gaussian Stochastic Weight Averaging for Bayesian Low-Rank Adaptation, and BAFTA: Backprop-Free Test-time Adaptation in Zero Shots, which explored low-rank adaptation techniques for deep neural networks.
The core idea of BLoB is to represent the task-specific adaptations as a low-rank matrix that is added to the original model parameters. This low-rank matrix is learned using a Bayesian framework, as described in Scalable Bayesian Learning of Posteriors and Bayesian Learning Rule.
The Bayesian formulation allows BLoB to learn the task-specific adaptations in a principled way, preventing overfitting and ensuring the adaptations are well-suited to the target task. The entire process is done through backpropagation, making it efficient to implement and integrate into existing machine learning pipelines.
Experiments show that BLoB can achieve strong performance on a range of natural language processing tasks while only fine-tuning a small subset of the model parameters. This efficient adaptation makes BLoB particularly useful in resource-constrained settings, such as on-device personalization or rapid adaptation to new domains.
Critical Analysis
The paper provides a thorough evaluation of BLoB, demonstrating its effectiveness across multiple benchmarks. However, a few potential limitations and areas for further research are worth considering:
- The paper focuses on natural language processing tasks, and it would be valuable to explore the performance of BLoB on other domains, such as computer vision or speech recognition.
- The adaptations learned by BLoB are task-specific, which may limit its ability to generalize across similar but distinct tasks. Exploring ways to share or transfer adaptations could further improve the efficiency of the approach.
- The Bayesian formulation of BLoB adds some computational overhead compared to simpler fine-tuning approaches. Investigating ways to further streamline the optimization process could make BLoB even more attractive for resource-constrained settings.
Overall, BLoB represents a promising step towards efficient adaptation of large language models, and the ideas presented in this paper could inspire further research in this important area.
Conclusion
BLoB introduces a novel Bayesian low-rank adaptation technique that allows for efficient fine-tuning of large language models to specific tasks or domains. By only updating a small subset of the model parameters, BLoB can adapt these powerful models quickly and with fewer computational resources than traditional fine-tuning approaches.
The Bayesian formulation of BLoB helps to prevent overfitting and ensures the adaptations are well-suited to the target task. The backpropagation-based optimization makes BLoB easy to implement and integrate into existing machine learning pipelines.
The efficiency and effectiveness of BLoB make it a valuable tool for a wide range of applications, from on-device personalization to rapid adaptation to new domains. As large language models continue to play a central role in natural language processing, techniques like BLoB will be crucial for unlocking their full potential in resource-constrained settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Gaussian Stochastic Weight Averaging for Bayesian Low-Rank Adaptation of Large Language Models
Emre Onal, Klemens Floge, Emma Caldwell, Arsen Sheverdin, Vincent Fortuin
0
0
Fine-tuned Large Language Models (LLMs) often suffer from overconfidence and poor calibration, particularly when fine-tuned on small datasets. To address these challenges, we propose a simple combination of Low-Rank Adaptation (LoRA) with Gaussian Stochastic Weight Averaging (SWAG), facilitating approximate Bayesian inference in LLMs. Through extensive testing across several Natural Language Processing (NLP) benchmarks, we demonstrate that our straightforward and computationally efficient approach improves model generalization and calibration. We further show that our method exhibits greater robustness against distribution shift, as reflected in its performance on out-of-distribution tasks.
5/7/2024

Adaptive Robust Learning using Latent Bernoulli Variables
Aleksandr Karakulev (Uppsala University, Sweden), Dave Zachariah (Uppsala University, Sweden), Prashant Singh (Uppsala University, Sweden, Science for Life Laboratory, Sweden)
0
0
We present an adaptive approach for robust learning from corrupted training sets. We identify corrupted and non-corrupted samples with latent Bernoulli variables and thus formulate the learning problem as maximization of the likelihood where latent variables are marginalized. The resulting problem is solved via variational inference, using an efficient Expectation-Maximization based method. The proposed approach improves over the state-of-the-art by automatically inferring the corruption level, while adding minimal computational overhead. We demonstrate our robust learning method and its parameter-free nature on a wide variety of machine learning tasks including online learning and deep learning where it adapts to different levels of noise and maintains high prediction accuracy.
6/17/2024
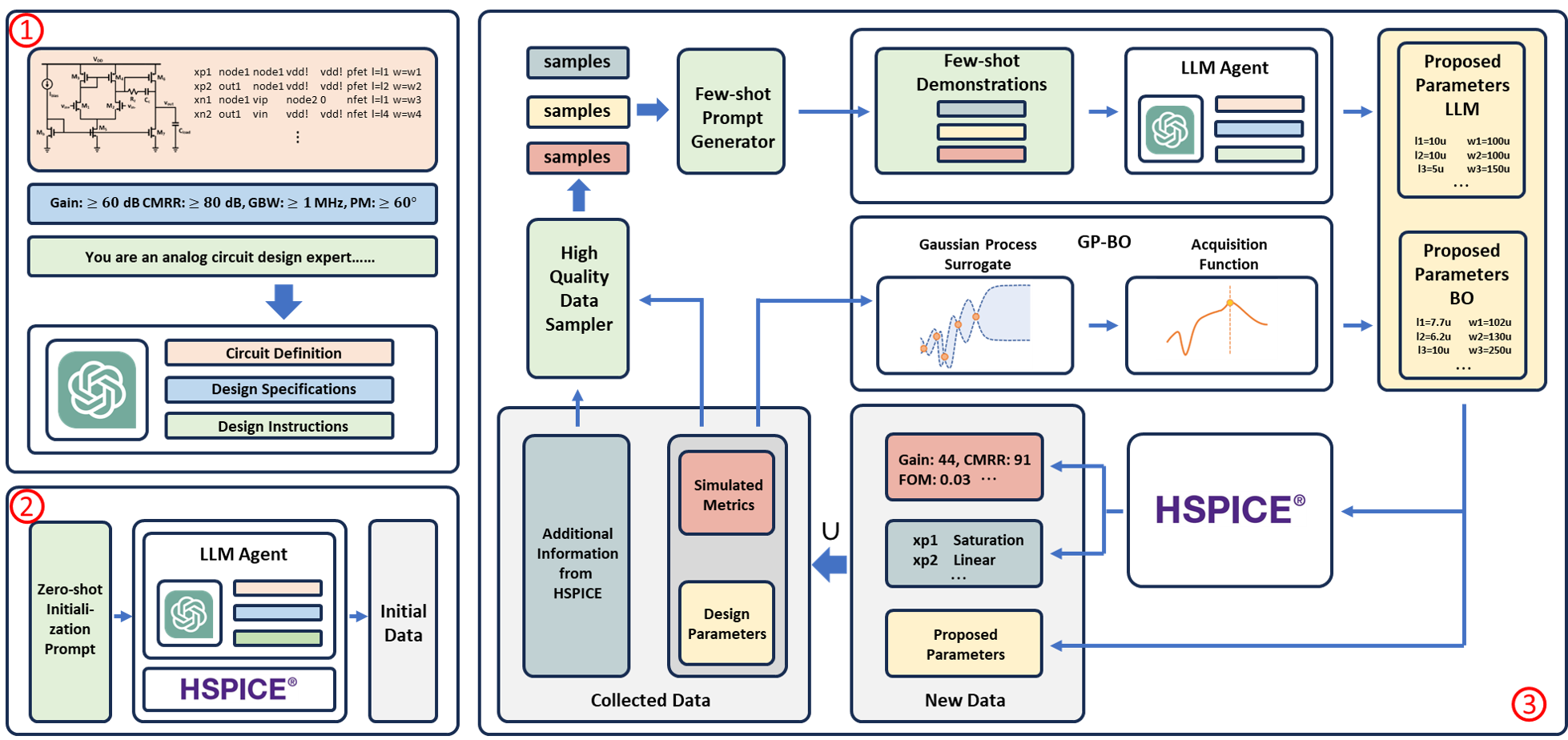
ADO-LLM: Analog Design Bayesian Optimization with In-Context Learning of Large Language Models
Yuxuan Yin, Yu Wang, Boxun Xu, Peng Li
0
0
Analog circuit design requires substantial human expertise and involvement, which is a significant roadblock to design productivity. Bayesian Optimization (BO), a popular machine learning based optimization strategy, has been leveraged to automate analog design given its applicability across various circuit topologies and technologies. Traditional BO methods employ black box Gaussian Process surrogate models and optimized labeled data queries to find optimization solutions by trading off between exploration and exploitation. However, the search for the optimal design solution in BO can be expensive from both a computational and data usage point of view, particularly for high dimensional optimization problems. This paper presents ADO-LLM, the first work integrating large language models (LLMs) with Bayesian Optimization for analog design optimization. ADO-LLM leverages the LLM's ability to infuse domain knowledge to rapidly generate viable design points to remedy BO's inefficiency in finding high value design areas specifically under the limited design space coverage of the BO's probabilistic surrogate model. In the meantime, sampling of design points evaluated in the iterative BO process provides quality demonstrations for the LLM to generate high quality design points while leveraging infused broad design knowledge. Furthermore, the diversity brought by BO's exploration enriches the contextual understanding of the LLM and allows it to more broadly search in the design space and prevent repetitive and redundant suggestions. We evaluate the proposed framework on two different types of analog circuits and demonstrate notable improvements in design efficiency and effectiveness.
6/28/2024

BaFTA: Backprop-Free Test-Time Adaptation For Zero-Shot Vision-Language Models
Xuefeng Hu, Ke Zhang, Min Sun, Albert Chen, Cheng-Hao Kuo, Ram Nevatia
0
0
Large-scale pretrained vision-language models like CLIP have demonstrated remarkable zero-shot image classification capabilities across diverse domains. To enhance CLIP's performance while preserving the zero-shot paradigm, various test-time prompt tuning methods have been introduced to refine class embeddings through unsupervised learning objectives during inference. However, these methods often encounter challenges in selecting appropriate learning rates to prevent collapsed training in the absence of validation data during test-time adaptation. In this study, we propose a novel backpropagation-free algorithm BaFTA for test-time adaptation of vision-language models. Instead of fine-tuning text prompts to refine class embeddings, our approach directly estimates class centroids using online clustering within a projected embedding space that aligns text and visual embeddings. We dynamically aggregate predictions from both estimated and original class embeddings, as well as from distinct augmented views, by assessing the reliability of each prediction using R'enyi Entropy. Through extensive experiments, we demonstrate that BaFTA consistently outperforms state-of-the-art test-time adaptation methods in both effectiveness and efficiency.
6/19/2024