GaussianDreamer: Fast Generation from Text to 3D Gaussians by Bridging 2D and 3D Diffusion Models
2310.08529
0
0
🛸
Abstract
In recent times, the generation of 3D assets from text prompts has shown impressive results. Both 2D and 3D diffusion models can help generate decent 3D objects based on prompts. 3D diffusion models have good 3D consistency, but their quality and generalization are limited as trainable 3D data is expensive and hard to obtain. 2D diffusion models enjoy strong abilities of generalization and fine generation, but 3D consistency is hard to guarantee. This paper attempts to bridge the power from the two types of diffusion models via the recent explicit and efficient 3D Gaussian splatting representation. A fast 3D object generation framework, named as GaussianDreamer, is proposed, where the 3D diffusion model provides priors for initialization and the 2D diffusion model enriches the geometry and appearance. Operations of noisy point growing and color perturbation are introduced to enhance the initialized Gaussians. Our GaussianDreamer can generate a high-quality 3D instance or 3D avatar within 15 minutes on one GPU, much faster than previous methods, while the generated instances can be directly rendered in real time. Demos and code are available at https://taoranyi.com/gaussiandreamer/.
Create account to get full access
Overview
- Recent advancements in text-to-3D generation have produced impressive results using both 2D and 3D diffusion models.
- 3D diffusion models provide good 3D consistency but are limited in quality and generalization due to the scarcity of trainable 3D data.
- 2D diffusion models excel at generalization and fine generation but struggle to guarantee 3D consistency.
- This paper introduces a framework called GaussianDreamer that combines the strengths of 2D and 3D diffusion models to generate high-quality 3D instances quickly.
Plain English Explanation
The paper describes a new method for generating 3D objects from text prompts. This is an active area of research, as being able to create 3D content from simple text descriptions would be very useful for a variety of applications, such as 3D modeling, game development, and virtual reality.
The key insight of this work is that by combining the strengths of two different types of AI models - 3D diffusion models and 2D diffusion models - the researchers were able to create a system that generates high-quality 3D objects much faster than previous methods. 3D diffusion models are good at maintaining the overall 3D structure of the objects, but they are limited in their ability to capture fine details and generate diverse shapes. 2D diffusion models, on the other hand, are excellent at generating detailed and varied 2D imagery, but they struggle to ensure that the 3D geometry is consistent.
The GaussianDreamer framework proposed in this paper uses the 3D diffusion model to provide an initial 3D structure, and then refines and enhances this structure using the 2D diffusion model. This allows the system to generate detailed and varied 3D objects that maintain a consistent 3D shape. The researchers also introduce some additional techniques, like "noisy point growing" and "color perturbation," to further improve the quality of the generated 3D content.
The end result is a system that can generate high-quality 3D instances or avatars in a matter of minutes, much faster than previous methods. This could have a significant impact on industries that rely on 3D content creation, as it would greatly reduce the time and effort required to produce 3D models from scratch.
Technical Explanation
The paper introduces a novel framework called GaussianDreamer that combines the strengths of 2D and 3D diffusion models to generate high-quality 3D instances efficiently.
The key components of the GaussianDreamer framework are:
-
3D Diffusion Model: The 3D diffusion model is used to provide an initial 3D structure for the generated objects. This helps maintain the overall 3D consistency of the output.
-
2D Diffusion Model: The 2D diffusion model is then used to enrich the geometry and appearance of the 3D object, leveraging its strong abilities in generalization and fine-grained generation.
-
Noisy Point Growing and Color Perturbation: To further enhance the quality of the generated 3D objects, the researchers introduce two additional techniques:
- Noisy point growing: This operation adds noise to the 3D points, encouraging the model to explore more diverse shapes.
- Color perturbation: This operation introduces color variations to the 3D object, improving its appearance.
The researchers demonstrate that this combined approach, which takes advantage of both 3D and 2D diffusion models, can generate high-quality 3D instances or avatars in as little as 15 minutes on a single GPU, which is significantly faster than previous methods.
The GaussianDreamer framework leverages the Gaussian splatting representation, which is an efficient and explicit way to represent 3D geometry. This representation, combined with the strengths of 2D and 3D diffusion models, allows the system to generate 3D content that can be directly rendered in real-time.
Critical Analysis
The paper presents a promising approach to text-to-3D generation, but it also acknowledges several limitations and areas for further research:
-
Trainable 3D Data Scarcity: The authors note that the quality and generalization of 3D diffusion models are limited due to the scarcity of high-quality 3D training data. Addressing this data challenge could further improve the performance of the 3D diffusion model component.
-
Geometry and Appearance Tradeoffs: While the combination of 3D and 2D diffusion models helps improve both the geometry and appearance of the generated 3D objects, there may still be inherent tradeoffs between these two aspects that need to be better understood and addressed.
-
Rendering Quality and Performance: The paper states that the generated 3D instances can be directly rendered in real-time, but it does not provide a detailed evaluation of the rendering quality and performance. Further research is needed to assess the practical viability of the generated 3D content for real-world applications.
-
Broader Applicability: The paper focuses on generating individual 3D objects or avatars, but it would be interesting to explore how the GaussianDreamer framework could be extended to generate more complex 3D scenes, as explored in related works like RealMDreamer and DiffusionGAN3D.
Overall, the GaussianDreamer framework represents a significant step forward in text-to-3D generation, but there are still opportunities for further research and development to address the limitations and expand the capabilities of this approach.
Conclusion
This paper presents a novel framework called GaussianDreamer that combines the strengths of 2D and 3D diffusion models to generate high-quality 3D objects from text prompts. By leveraging the 3D consistency of 3D diffusion models and the generalization and fine-grained generation capabilities of 2D diffusion models, the system can create detailed and varied 3D instances much faster than previous methods.
The key innovations of the GaussianDreamer framework include the use of a 3D diffusion model for initial 3D structure, the incorporation of a 2D diffusion model to enhance the geometry and appearance, and the introduction of techniques like noisy point growing and color perturbation to further improve the quality of the generated 3D content.
This research represents an important step forward in the field of text-to-3D generation, which has the potential to revolutionize various industries that rely on 3D content creation, such as game development, virtual reality, and product design. By making the process of generating high-quality 3D models more efficient and accessible, the GaussianDreamer framework could have a significant impact on the way we create and interact with 3D digital content in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GaussianDreamerPro: Text to Manipulable 3D Gaussians with Highly Enhanced Quality
Taoran Yi, Jiemin Fang, Zanwei Zhou, Junjie Wang, Guanjun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Xinggang Wang, Qi Tian
0
0
Recently, 3D Gaussian splatting (3D-GS) has achieved great success in reconstructing and rendering real-world scenes. To transfer the high rendering quality to generation tasks, a series of research works attempt to generate 3D-Gaussian assets from text. However, the generated assets have not achieved the same quality as those in reconstruction tasks. We observe that Gaussians tend to grow without control as the generation process may cause indeterminacy. Aiming at highly enhancing the generation quality, we propose a novel framework named GaussianDreamerPro. The main idea is to bind Gaussians to reasonable geometry, which evolves over the whole generation process. Along different stages of our framework, both the geometry and appearance can be enriched progressively. The final output asset is constructed with 3D Gaussians bound to mesh, which shows significantly enhanced details and quality compared with previous methods. Notably, the generated asset can also be seamlessly integrated into downstream manipulation pipelines, e.g. animation, composition, and simulation etc., greatly promoting its potential in wide applications. Demos are available at https://taoranyi.com/gaussiandreamerpro/.
6/27/2024

GradeADreamer: Enhanced Text-to-3D Generation Using Gaussian Splatting and Multi-View Diffusion
Trapoom Ukarapol, Kevin Pruvost
0
0
Text-to-3D generation has shown promising results, yet common challenges such as the Multi-face Janus problem and extended generation time for high-quality assets. In this paper, we address these issues by introducing a novel three-stage training pipeline called GradeADreamer. This pipeline is capable of producing high-quality assets with a total generation time of under 30 minutes using only a single RTX 3090 GPU. Our proposed method employs a Multi-view Diffusion Model, MVDream, to generate Gaussian Splats as a prior, followed by refining geometry and texture using StableDiffusion. Experimental results demonstrate that our approach significantly mitigates the Multi-face Janus problem and achieves the highest average user preference ranking compared to previous state-of-the-art methods. The project code is available at https://github.com/trapoom555/GradeADreamer.
6/17/2024
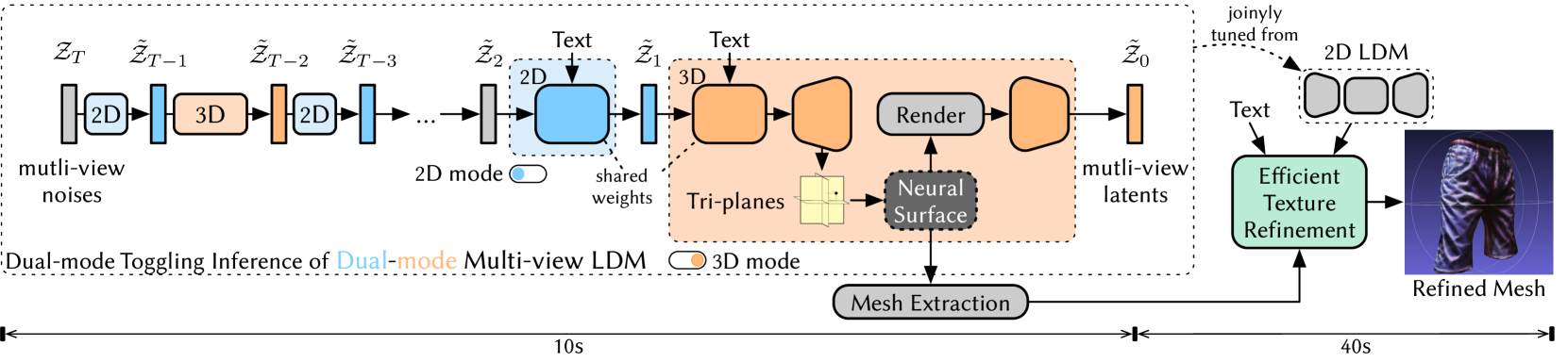
Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
Xinyang Li, Zhangyu Lai, Linning Xu, Jianfei Guo, Liujuan Cao, Shengchuan Zhang, Bo Dai, Rongrong Ji
0
0
We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only $1$ minute.The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only $1/10$ denoising steps with 3D mode, successfully generating a 3D asset in just $10$ seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time. Our project page is available at https://dual3d.github.io
5/17/2024

PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
Ying-Tian Liu, Yuan-Chen Guo, Guan Luo, Heyi Sun, Wei Yin, Song-Hai Zhang
0
0
Diffusion models trained on large-scale text-image datasets have demonstrated a strong capability of controllable high-quality image generation from arbitrary text prompts. However, the generation quality and generalization ability of 3D diffusion models is hindered by the scarcity of high-quality and large-scale 3D datasets. In this paper, we present PI3D, a framework that fully leverages the pre-trained text-to-image diffusion models' ability to generate high-quality 3D shapes from text prompts in minutes. The core idea is to connect the 2D and 3D domains by representing a 3D shape as a set of Pseudo RGB Images. We fine-tune an existing text-to-image diffusion model to produce such pseudo-images using a small number of text-3D pairs. Surprisingly, we find that it can already generate meaningful and consistent 3D shapes given complex text descriptions. We further take the generated shapes as the starting point for a lightweight iterative refinement using score distillation sampling to achieve high-quality generation under a low budget. PI3D generates a single 3D shape from text in only 3 minutes and the quality is validated to outperform existing 3D generative models by a large margin.
4/23/2024