PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
2312.09069
0
0

Abstract
Diffusion models trained on large-scale text-image datasets have demonstrated a strong capability of controllable high-quality image generation from arbitrary text prompts. However, the generation quality and generalization ability of 3D diffusion models is hindered by the scarcity of high-quality and large-scale 3D datasets. In this paper, we present PI3D, a framework that fully leverages the pre-trained text-to-image diffusion models' ability to generate high-quality 3D shapes from text prompts in minutes. The core idea is to connect the 2D and 3D domains by representing a 3D shape as a set of Pseudo RGB Images. We fine-tune an existing text-to-image diffusion model to produce such pseudo-images using a small number of text-3D pairs. Surprisingly, we find that it can already generate meaningful and consistent 3D shapes given complex text descriptions. We further take the generated shapes as the starting point for a lightweight iterative refinement using score distillation sampling to achieve high-quality generation under a low budget. PI3D generates a single 3D shape from text in only 3 minutes and the quality is validated to outperform existing 3D generative models by a large margin.
Create account to get full access
Overview
- Introduces a new text-to-3D generation model called PI3D that uses a "pseudo-image" approach for efficient 3D generation
- Leverages diffusion models, which have shown impressive results in 2D image generation, and adapts them for 3D shape generation
- Demonstrates state-of-the-art performance on several 3D generation benchmarks compared to existing methods
Plain English Explanation
The paper presents a new way to generate 3D shapes from text descriptions, called PI3D. Instead of trying to directly generate 3D data, which can be computationally expensive, the researchers use a clever trick. They first generate a "pseudo-image" - a 2D representation that captures the key features of the 3D shape. Then, they use a diffusion model, a powerful AI technique for generating images, to turn this pseudo-image into the final 3D shape.
This pseudo-image approach makes the 3D generation process much more efficient and scalable compared to previous methods. The diffusion model is able to leverage its impressive 2D generation capabilities to create high-quality 3D shapes from text in a fast and reliable way.
The paper shows that PI3D outperforms other state-of-the-art 3D generation models on several standard benchmarks. This suggests the pseudo-image technique is a promising direction for making text-to-3D generation more practical and accessible.
Technical Explanation
The paper introduces a new model called PI3D (Pseudo-Image 3D) that generates 3D shapes from text descriptions. PI3D leverages the success of diffusion models in 2D image generation and adapts them for efficient 3D shape generation.
Instead of directly generating 3D data, which can be computationally expensive, PI3D first generates a "pseudo-image" - a 2D representation that captures the key features of the 3D shape. It then uses a diffusion model to turn this pseudo-image into the final 3D shape. This pseudo-image approach allows PI3D to benefit from the powerful 2D generation capabilities of diffusion models while avoiding the complexities of directly generating 3D data.
The paper evaluates PI3D on several 3D generation benchmarks and demonstrates state-of-the-art performance compared to existing text-to-3D methods, such as DiffusionGAN3D, RealMDreamer, MVDream, and Diffusion Models for 3D Annotations. The results suggest that the pseudo-image approach is a promising direction for making text-to-3D generation more efficient and practical.
Critical Analysis
The paper provides a compelling approach to text-to-3D generation, but there are a few potential limitations and areas for further research:
-
Evaluation on Diverse 3D Data: The paper primarily evaluates PI3D on synthetic 3D shape datasets, such as ShapeNet. It would be valuable to see how the model performs on more diverse and realistic 3D data, such as Portrait3D, which focuses on generating 3D portraits from text.
-
Interpretability and Controllability: The paper does not explore the interpretability and controllability of the generated 3D shapes. It would be interesting to investigate how the text input maps to specific features of the output 3D shape and whether users can fine-tune or manipulate the generation process.
-
Computational Efficiency: While the pseudo-image approach is claimed to be more efficient than direct 3D generation, the paper does not provide a detailed analysis of the computational costs and runtime performance of PI3D compared to other methods. Quantifying these aspects would help better assess the practical benefits of the proposed approach.
-
Generalization to Other 3D Tasks: The paper focuses on the task of text-to-3D generation. It would be valuable to explore whether the pseudo-image technique can be extended to other 3D-related tasks, such as 3D scene generation, 3D object manipulation, or 3D-aware text-to-image generation.
Overall, the PI3D model presents an innovative approach to text-to-3D generation that leverages the power of diffusion models in an efficient manner. Further research addressing the above considerations could help strengthen the model's capabilities and applicability in real-world scenarios.
Conclusion
The paper introduces PI3D, a new text-to-3D generation model that uses a "pseudo-image" approach to leverage the impressive generation capabilities of diffusion models. By first generating a 2D pseudo-image representation and then turning it into a 3D shape, PI3D demonstrates state-of-the-art performance on several 3D generation benchmarks while being more computationally efficient than previous methods.
This work suggests that the pseudo-image technique is a promising direction for making text-to-3D generation more practical and accessible. As the field of 3D AI continues to advance, innovative approaches like PI3D that can generate high-quality 3D content from text descriptions could have significant implications for a wide range of applications, from virtual design and entertainment to assistive technologies and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
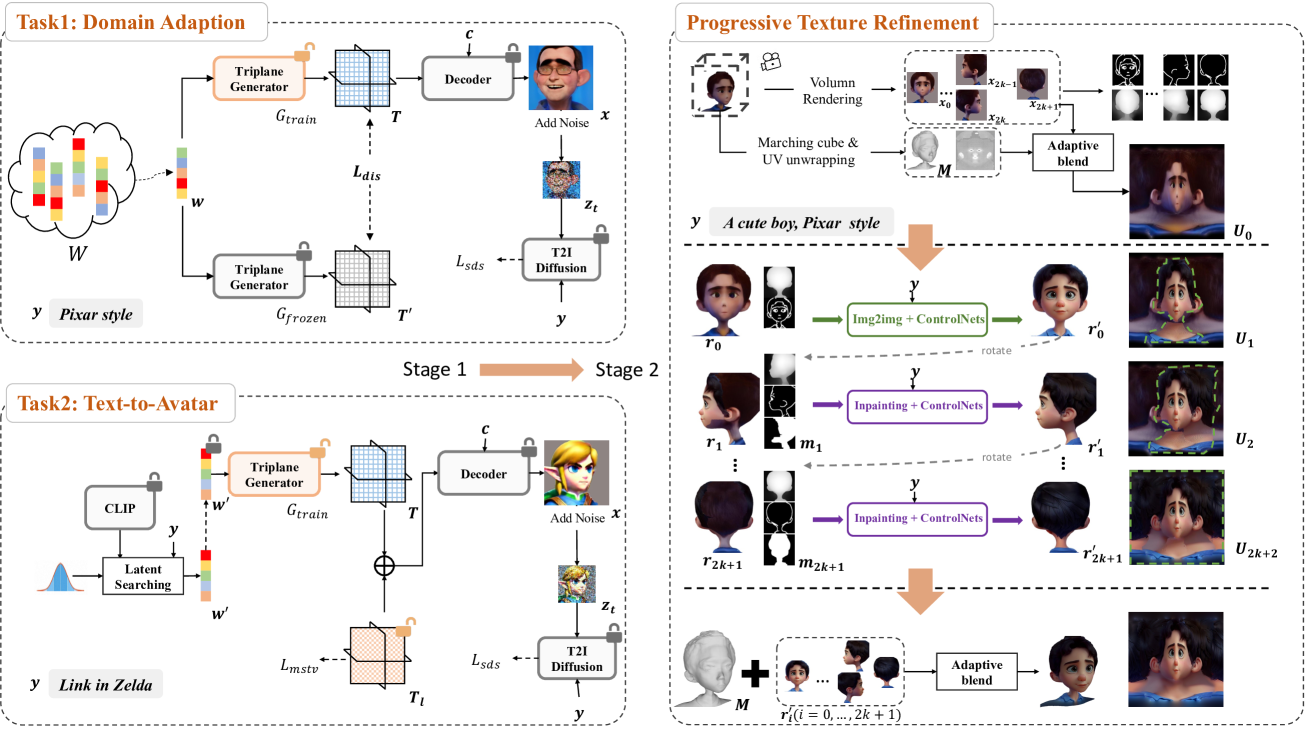
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaptation by Combining 3D GANs and Diffusion Priors
Biwen Lei, Kai Yu, Mengyang Feng, Miaomiao Cui, Xuansong Xie
0
0
Text-guided domain adaptation and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaptation and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaptation. To enhance the diversity in domain adaptation and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaptation and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
4/15/2024

VividDreamer: Towards High-Fidelity and Efficient Text-to-3D Generation
Zixuan Chen, Ruijie Su, Jiahao Zhu, Lingxiao Yang, Jian-Huang Lai, Xiaohua Xie
0
0
Text-to-3D generation aims to create 3D assets from text-to-image diffusion models. However, existing methods face an inherent bottleneck in generation quality because the widely-used objectives such as Score Distillation Sampling (SDS) inappropriately omit U-Net jacobians for swift generation, leading to significant bias compared to the true gradient obtained by full denoising sampling. This bias brings inconsistent updating direction, resulting in implausible 3D generation e.g., color deviation, Janus problem, and semantically inconsistent details). In this work, we propose Pose-dependent Consistency Distillation Sampling (PCDS), a novel yet efficient objective for diffusion-based 3D generation tasks. Specifically, PCDS builds the pose-dependent consistency function within diffusion trajectories, allowing to approximate true gradients through minimal sampling steps (1-3). Compared to SDS, PCDS can acquire a more accurate updating direction with the same sampling time (1 sampling step), while enabling few-step (2-3) sampling to trade compute for higher generation quality. For efficient generation, we propose a coarse-to-fine optimization strategy, which first utilizes 1-step PCDS to create the basic structure of 3D objects, and then gradually increases PCDS steps to generate fine-grained details. Extensive experiments demonstrate that our approach outperforms the state-of-the-art in generation quality and training efficiency, conspicuously alleviating the implausible 3D generation issues caused by the deviated updating direction. Moreover, it can be simply applied to many 3D generative applications to yield impressive 3D assets, please see our project page: https://narcissusex.github.io/VividDreamer.
6/24/2024
🛸
Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, Yao Yao
0
0
Generating high-quality 3D assets from text and images has long been challenging, primarily due to the absence of scalable 3D representations capable of capturing intricate geometry distributions. In this work, we introduce Direct3D, a native 3D generative model scalable to in-the-wild input images, without requiring a multiview diffusion model or SDS optimization. Our approach comprises two primary components: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). D3D-VAE efficiently encodes high-resolution 3D shapes into a compact and continuous latent triplane space. Notably, our method directly supervises the decoded geometry using a semi-continuous surface sampling strategy, diverging from previous methods relying on rendered images as supervision signals. D3D-DiT models the distribution of encoded 3D latents and is specifically designed to fuse positional information from the three feature maps of the triplane latent, enabling a native 3D generative model scalable to large-scale 3D datasets. Additionally, we introduce an innovative image-to-3D generation pipeline incorporating semantic and pixel-level image conditions, allowing the model to produce 3D shapes consistent with the provided conditional image input. Extensive experiments demonstrate the superiority of our large-scale pre-trained Direct3D over previous image-to-3D approaches, achieving significantly better generation quality and generalization ability, thus establishing a new state-of-the-art for 3D content creation. Project page: https://nju-3dv.github.io/projects/Direct3D/.
6/4/2024
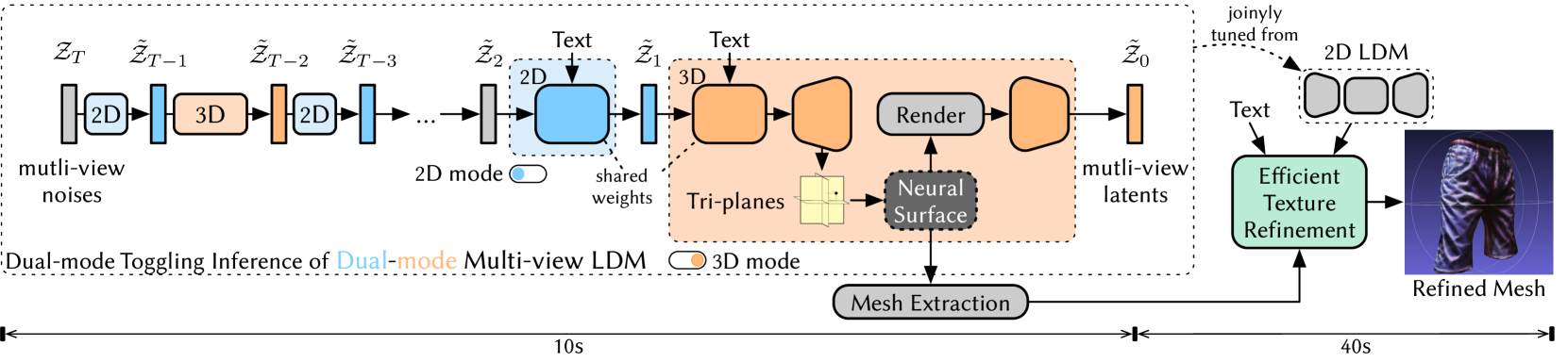
Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
Xinyang Li, Zhangyu Lai, Linning Xu, Jianfei Guo, Liujuan Cao, Shengchuan Zhang, Bo Dai, Rongrong Ji
0
0
We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only $1$ minute.The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only $1/10$ denoising steps with 3D mode, successfully generating a 3D asset in just $10$ seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time. Our project page is available at https://dual3d.github.io
5/17/2024