GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting
2404.16012
0
0
Abstract
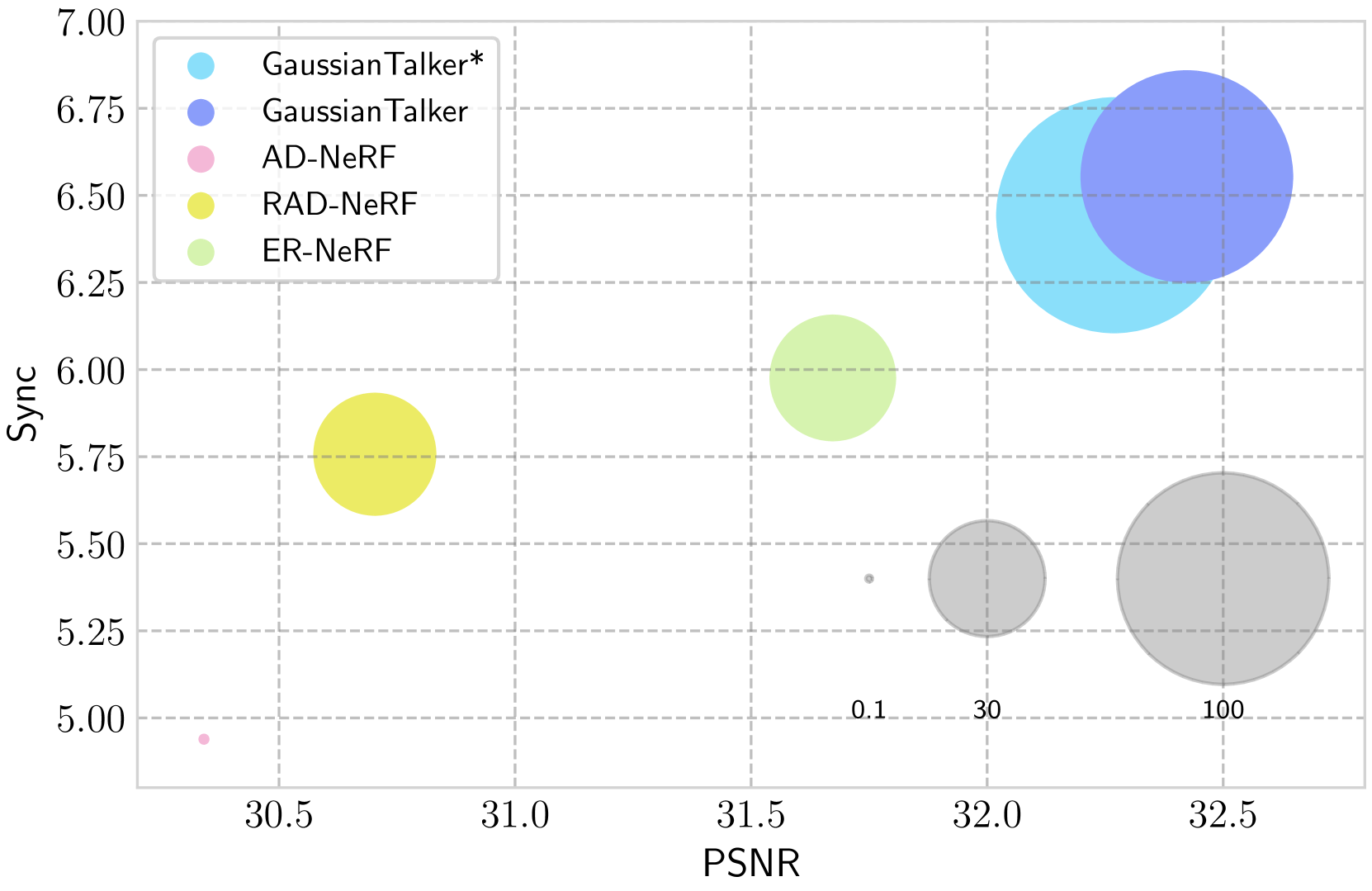
We propose GaussianTalker, a novel framework for real-time generation of pose-controllable talking heads. It leverages the fast rendering capabilities of 3D Gaussian Splatting (3DGS) while addressing the challenges of directly controlling 3DGS with speech audio. GaussianTalker constructs a canonical 3DGS representation of the head and deforms it in sync with the audio. A key insight is to encode the 3D Gaussian attributes into a shared implicit feature representation, where it is merged with audio features to manipulate each Gaussian attribute. This design exploits the spatial-aware features and enforces interactions between neighboring points. The feature embeddings are then fed to a spatial-audio attention module, which predicts frame-wise offsets for the attributes of each Gaussian. It is more stable than previous concatenation or multiplication approaches for manipulating the numerous Gaussians and their intricate parameters. Experimental results showcase GaussianTalker's superiority in facial fidelity, lip synchronization accuracy, and rendering speed compared to previous methods. Specifically, GaussianTalker achieves a remarkable rendering speed up to 120 FPS, surpassing previous benchmarks. Our code is made available at https://github.com/KU-CVLAB/GaussianTalker/ .
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a new method called GaussianTalker for real-time, high-fidelity 3D talking head synthesis driven by audio input.
- The key innovation is the use of 3D Gaussian splatting to generate a smooth, controllable 3D head model that can be rendered from any viewpoint.
- The system is trained on a large dataset of speaker-specific videos, allowing it to capture the unique facial movements and expressions of each individual.
- GaussianTalker can generate talking head videos in real-time, making it suitable for interactive applications like video conferencing and virtual avatars.
Plain English Explanation
GaussianTalker is a new technology that can create realistic 3D animations of a person's head and face, driven by just the audio of that person speaking. This means you can take a recording of someone talking and use it to automatically generate a 3D computer-animated version of their head, with the mouth, eyes, and other facial features moving in sync with the audio.
The key innovation in GaussianTalker is the use of "3D Gaussian splatting." This is a technique that allows the system to generate a smooth, three-dimensional model of the head that can be viewed from any angle. Previous talking head systems were often limited to a fixed camera viewpoint, but GaussianTalker can seamlessly render the 3D head from different perspectives.
The system is trained on a large dataset of videos featuring many different speakers. This allows it to learn the unique facial movements and expressions of each individual, so the resulting animations look very natural and realistic. GaussianTalker can generate these talking head videos in real-time, making it useful for interactive applications like video conferencing, virtual assistants, and animated avatars.
Technical Explanation
The core of the GaussianTalker system is a neural network architecture that takes audio input and generates a 3D, controllable head model as output. The key innovation is the use of 3D Gaussian splatting, which allows the system to produce a smooth, continuous 3D representation of the head that can be rendered from any viewpoint.
The network is trained on a large dataset of speaker-specific videos, similar to the approach used in Talk3D and Learn2Talk. This enables the system to capture the unique facial dynamics and expressions of each individual speaker. The 3D Gaussian splatting representation allows for real-time synthesis of talking head animations, which is a key advantage over previous methods.
The authors also introduce a novel SpaceTime Gaussian Feature Splatting module that efficiently encodes temporal information and improves the temporal coherence of the generated animations.
Critical Analysis
The GaussianTalker system represents a significant advance in real-time, high-fidelity 3D talking head synthesis. The use of 3D Gaussian splatting is a clever solution to the challenge of generating smooth, controllable 3D head models from audio input.
However, the paper does not fully address the potential for bias and lack of diversity in the training data. The authors mention that the system is trained on speaker-specific videos, which could mean the resulting animations may only faithfully represent a limited set of individuals. Further research is needed to understand the system's performance on a more diverse range of speakers.
Additionally, while the real-time capability is a key strength, the paper does not provide a thorough analysis of the computational efficiency and resource requirements of the system. This information would be valuable for evaluating its suitability for deployment in resource-constrained environments.
Overall, GaussianTalker is a promising step forward in the field of talking head synthesis, but additional work is needed to address potential biases and fully characterize the system's performance and practical limitations.
Conclusion
The GaussianTalker system represents a significant advancement in the field of real-time, high-fidelity 3D talking head synthesis. By leveraging 3D Gaussian splatting, the system can generate smooth, controllable 3D head models that can be rendered from any viewpoint, driven solely by audio input.
The speaker-specific training approach allows the system to capture the unique facial dynamics and expressions of individual speakers, resulting in highly realistic animations. The real-time synthesis capability makes GaussianTalker a promising technology for interactive applications like video conferencing, virtual avatars, and augmented reality experiences.
While the paper demonstrates the technical merits of the approach, further research is needed to address potential biases in the training data and fully characterize the system's computational efficiency and practical limitations. Overall, GaussianTalker is a valuable contribution that pushes the boundaries of what is possible in the field of talking head synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
0
0
Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
4/30/2024
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting
Bo Chen, Shoukang Hu, Qi Chen, Chenpeng Du, Ran Yi, Yanmin Qian, Xie Chen
0
0
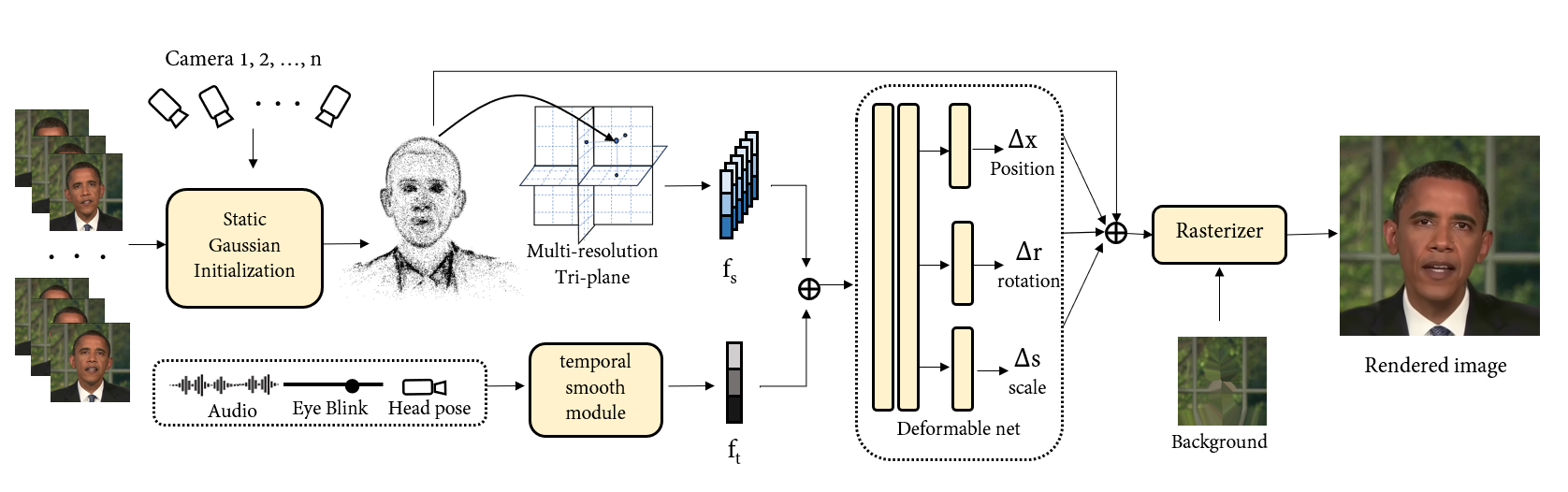
We present GStalker, a 3D audio-driven talking face generation model with Gaussian Splatting for both fast training (40 minutes) and real-time rendering (125 FPS) with a 3$sim$5 minute video for training material, in comparison with previous 2D and 3D NeRF-based modeling frameworks which require hours of training and seconds of rendering per frame. Specifically, GSTalker learns an audio-driven Gaussian deformation field to translate and transform 3D Gaussians to synchronize with audio information, in which multi-resolution hashing grid-based tri-plane and temporal smooth module are incorporated to learn accurate deformation for fine-grained facial details. In addition, a pose-conditioned deformation field is designed to model the stabilized torso. To enable efficient optimization of the condition Gaussian deformation field, we initialize 3D Gaussians by learning a coarse static Gaussian representation. Extensive experiments in person-specific videos with audio tracks validate that GSTalker can generate high-fidelity and audio-lips synchronized results with fast training and real-time rendering speed.
5/1/2024

TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting
Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xin Ning, Jun Zhou, Lin Gu
0
0
Radiance fields have demonstrated impressive performance in synthesizing lifelike 3D talking heads. However, due to the difficulty in fitting steep appearance changes, the prevailing paradigm that presents facial motions by directly modifying point appearance may lead to distortions in dynamic regions. To tackle this challenge, we introduce TalkingGaussian, a deformation-based radiance fields framework for high-fidelity talking head synthesis. Leveraging the point-based Gaussian Splatting, facial motions can be represented in our method by applying smooth and continuous deformations to persistent Gaussian primitives, without requiring to learn the difficult appearance change like previous methods. Due to this simplification, precise facial motions can be synthesized while keeping a highly intact facial feature. Under such a deformation paradigm, we further identify a face-mouth motion inconsistency that would affect the learning of detailed speaking motions. To address this conflict, we decompose the model into two branches separately for the face and inside mouth areas, therefore simplifying the learning tasks to help reconstruct more accurate motion and structure of the mouth region. Extensive experiments demonstrate that our method renders high-quality lip-synchronized talking head videos, with better facial fidelity and higher efficiency compared with previous methods.
4/24/2024

Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Jaehoon Ko, Kyusun Cho, Joungbin Lee, Heeji Yoon, Sangmin Lee, Sangjun Ahn, Seungryong Kim
0
0
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
4/1/2024