GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting

0
Sign in to get full access
Overview
• This paper presents a novel method called GSTalker for real-time, high-fidelity audio-driven talking face generation using deformable Gaussian splatting. • GSTalker is designed to synthesize realistic, speaker-specific talking heads that can be driven by audio input in real-time. • The key ideas include using a neural radiance field (NeRF) to represent the 3D face geometry and a deformable Gaussian splatting technique to generate the video frames.
Plain English Explanation
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting is a system that can create realistic 3D talking heads that move in sync with audio. The researchers developed a new technique called deformable Gaussian splatting to generate the talking face video in real-time.
The key idea is to use a neural radiance field (NeRF) to represent the 3D shape and appearance of the face. NeRFs are a powerful way to capture the 3D structure of objects using a machine learning model. By deforming and "splatting" the NeRF in response to the audio, GSTalker can generate high-quality video of a talking face that matches the input speech.
This is an important advance because prior methods for audio-driven talking face synthesis either produced lower quality results or required significant computational resources. GSTalker can generate realistic talking heads in real-time, which opens up new possibilities for applications like virtual avatars, video conferencing, and dubbing foreign language content.
Technical Explanation
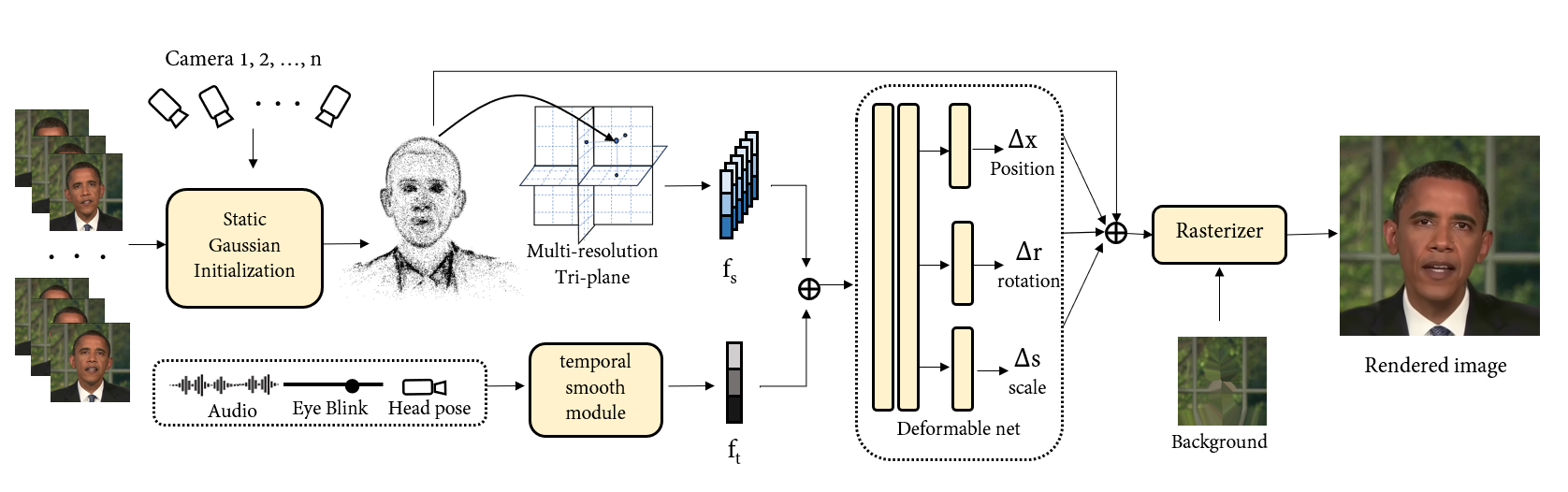
GSTalker uses a neural radiance field (NeRF) to represent the 3D geometry and appearance of a speaker-specific face. The NeRF is deformed based on the input audio features using a deformable Gaussian splatting technique. This allows GSTalker to synthesize high-fidelity, photorealistic talking face videos that are driven by the audio in real-time.
The key technical components are:
-
NeRF-based Face Representation: The 3D face geometry and appearance are encoded using a NeRF model that is trained on images of the target speaker. This allows the system to capture the fine-grained details of the individual's face.
-
Audio-Driven Deformation: The NeRF is deformed in response to the input audio features using a set of learned, speaker-specific deformation parameters. This deformation is performed efficiently using a Gaussian splatting operation.
-
Real-time Rendering: The deformed NeRF is then rendered into a video frame using a differentiable rendering process. This allows the entire pipeline to run in real-time, generating talking face videos that are synchronized to the input audio.
The researchers demonstrate that GSTalker can produce high-quality, photorealistic talking face videos that outperform prior audio-driven talking head synthesis methods in terms of both visual quality and computational efficiency.
Critical Analysis
The GSTalker paper presents an impressive technical achievement in audio-driven talking face synthesis. The use of a NeRF to capture the 3D face geometry and the novel deformable Gaussian splatting technique enable real-time, high-fidelity video generation.
However, the paper does not extensively discuss some potential limitations and avenues for future work. For example, the system is trained and evaluated on a single target speaker, so it is unclear how well it would generalize to diverse speakers or faces. Additionally, the paper does not address potential issues around bias, fairness, or ethical concerns that could arise from deploying such a system.
Further research could explore techniques to make the system more robust, scalable, and inclusive. Investigating ways to adapt the model to new speakers, handle occlusions or extreme head poses, and ensure fair and unbiased outputs would be valuable extensions of this work.
Overall, GSTalker represents an important advancement in audio-driven talking face synthesis, but there is still room for improvement and further research to address the technology's limitations and societal implications.
Conclusion
The GSTalker paper presents a novel method for generating high-quality, real-time audio-driven talking face videos using a neural radiance field and deformable Gaussian splatting. This work advances the state-of-the-art in talking head synthesis, enabling more realistic and computationally efficient video generation that can be driven by audio input.
The key technical innovations, including the use of NeRFs and the deformable Gaussian splatting technique, allow GSTalker to produce photorealistic talking face videos that outperform prior methods. This has important implications for applications like virtual avatars, video conferencing, and content dubbing.
While the paper demonstrates the impressive capabilities of GSTalker, further research is needed to address potential limitations around speaker generalization, robustness, and ethical considerations. Exploring ways to make the system more inclusive and accountable will be important as this technology continues to develop and be deployed.
Overall, GSTalker represents a significant step forward in audio-driven talking face synthesis, showcasing the potential of novel neural rendering techniques to enable realistic and efficient virtual communication experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting
Bo Chen, Shoukang Hu, Qi Chen, Chenpeng Du, Ran Yi, Yanmin Qian, Xie Chen
We present GStalker, a 3D audio-driven talking face generation model with Gaussian Splatting for both fast training (40 minutes) and real-time rendering (125 FPS) with a 3$sim$5 minute video for training material, in comparison with previous 2D and 3D NeRF-based modeling frameworks which require hours of training and seconds of rendering per frame. Specifically, GSTalker learns an audio-driven Gaussian deformation field to translate and transform 3D Gaussians to synchronize with audio information, in which multi-resolution hashing grid-based tri-plane and temporal smooth module are incorporated to learn accurate deformation for fine-grained facial details. In addition, a pose-conditioned deformation field is designed to model the stabilized torso. To enable efficient optimization of the condition Gaussian deformation field, we initialize 3D Gaussians by learning a coarse static Gaussian representation. Extensive experiments in person-specific videos with audio tracks validate that GSTalker can generate high-fidelity and audio-lips synchronized results with fast training and real-time rendering speed.
Read more5/1/2024
0
GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting
Kyusun Cho, Joungbin Lee, Heeji Yoon, Yeobin Hong, Jaehoon Ko, Sangjun Ahn, Seungryong Kim
We propose GaussianTalker, a novel framework for real-time generation of pose-controllable talking heads. It leverages the fast rendering capabilities of 3D Gaussian Splatting (3DGS) while addressing the challenges of directly controlling 3DGS with speech audio. GaussianTalker constructs a canonical 3DGS representation of the head and deforms it in sync with the audio. A key insight is to encode the 3D Gaussian attributes into a shared implicit feature representation, where it is merged with audio features to manipulate each Gaussian attribute. This design exploits the spatial-aware features and enforces interactions between neighboring points. The feature embeddings are then fed to a spatial-audio attention module, which predicts frame-wise offsets for the attributes of each Gaussian. It is more stable than previous concatenation or multiplication approaches for manipulating the numerous Gaussians and their intricate parameters. Experimental results showcase GaussianTalker's superiority in facial fidelity, lip synchronization accuracy, and rendering speed compared to previous methods. Specifically, GaussianTalker achieves a remarkable rendering speed up to 120 FPS, surpassing previous benchmarks. Our code is made available at https://github.com/KU-CVLAB/GaussianTalker/ .
Read more4/26/2024

0
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
Read more8/12/2024

0
GMTalker: Gaussian Mixture-based Audio-Driven Emotional talking video Portraits
Yibo Xia, Lizhen Wang, Xiang Deng, Xiaoyan Luo, Yebin Liu
Synthesizing high-fidelity and emotion-controllable talking video portraits, with audio-lip sync, vivid expressions, realistic head poses, and eye blinks, has been an important and challenging task in recent years. Most existing methods suffer in achieving personalized and precise emotion control, smooth transitions between different emotion states, and the generation of diverse motions. To tackle these challenges, we present GMTalker, a Gaussian mixture-based emotional talking portraits generation framework. Specifically, we propose a Gaussian mixture-based expression generator that can construct a continuous and disentangled latent space, achieving more flexible emotion manipulation. Furthermore, we introduce a normalizing flow-based motion generator pretrained on a large dataset with a wide-range motion to generate diverse head poses, blinks, and eyeball movements. Finally, we propose a personalized emotion-guided head generator with an emotion mapping network that can synthesize high-fidelity and faithful emotional video portraits. Both quantitative and qualitative experiments demonstrate our method outperforms previous methods in image quality, photo-realism, emotion accuracy, and motion diversity.
Read more5/29/2024