A General Online Algorithm for Optimizing Complex Performance Metrics

0
Sign in to get full access
Overview
- Presents a general online algorithm for optimizing complex performance metrics
- Applicable to a wide range of classification and prediction tasks
- Aims to improve upon existing methods for optimizing non-convex, non-differentiable performance measures
Plain English Explanation
This paper introduces a new algorithm that can be used to optimize complex performance metrics in online learning settings. Many real-world machine learning problems involve optimizing measures of performance that are difficult to work with, such as metrics that are non-convex or non-differentiable. The proposed algorithm provides a general framework for addressing these challenges and improving model performance on a variety of classification and prediction tasks.
The key idea is to reformulate the optimization problem in a way that allows for efficient online updates, even for complex performance measures. This involves decomposing the metric into a set of simpler, differentiable components that can be optimized jointly. By doing so, the algorithm can learn to directly optimize the target metric, rather than relying on proxy losses that may not align well with the desired performance objectives.
The authors demonstrate the effectiveness of their approach on several benchmark datasets and tasks, showing significant improvements over existing online learning methods for optimizing non-convex metrics. This work has the potential to enable more powerful and flexible machine learning models that can be tailored to the specific needs of different applications.
Technical Explanation
The paper presents a general online algorithm for optimizing complex performance metrics in classification and prediction tasks. The key innovation is a framework for decomposing non-convex, non-differentiable performance measures into a set of simpler, differentiable components that can be optimized jointly in an online manner.
The algorithm works by maintaining a set of expert models, each of which specializes in optimizing a particular component of the overall performance metric. These experts are combined using a weighted majority voting scheme, with the weights updated based on the relative performance of each expert on the current task. By updating the expert weights and model parameters in an online fashion, the algorithm is able to learn to directly optimize the target metric, rather than relying on proxy losses.
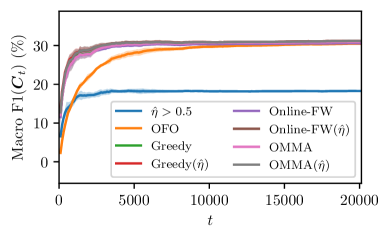
The authors demonstrate the effectiveness of their approach on several benchmark datasets and tasks, including multi-label classification, image classification, and online prediction. They show that their algorithm outperforms existing online learning methods for optimizing non-convex metrics, such as F1-score and macro-averaged accuracy.
Critical Analysis
The paper presents a novel and promising approach for optimizing complex performance metrics in online learning settings. The authors have done a thorough job of evaluating their algorithm on a range of benchmark tasks and demonstrating its advantages over existing methods.
One potential limitation of the approach is that it relies on the ability to decompose the target performance metric into a set of differentiable components. While the authors show that this is possible for several common metrics, it may not be straightforward to apply the method to all types of non-convex, non-differentiable measures. Further research may be needed to explore the limits of this decomposition approach and investigate alternative techniques for optimizing such metrics.
Additionally, the paper does not provide much analysis of the computational and memory requirements of the proposed algorithm. As the number of expert models grows, the computational overhead may become a bottleneck, especially for large-scale or real-time applications. The authors could have explored strategies for managing the complexity of the algorithm, such as techniques for pruning or compressing the expert ensemble.
Overall, this work represents an important step forward in the field of online learning and optimization of complex performance metrics. The authors have presented a principled and effective framework that could have significant impact on a wide range of machine learning applications.
Conclusion
This paper introduces a novel online algorithm for optimizing complex performance metrics in classification and prediction tasks. By decomposing non-convex, non-differentiable measures into a set of differentiable components, the algorithm is able to learn to directly optimize the target metric in an efficient, online manner.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing significant improvements over existing online learning methods for optimizing non-convex metrics. This work has the potential to enable more powerful and flexible machine learning models that can be tailored to the specific needs of different applications, ultimately leading to better real-world performance and more reliable predictions.
While the paper presents a promising new direction, further research is needed to explore the limits of the decomposition approach and to address potential computational and memory challenges. Overall, this work represents an important contribution to the field of online learning and optimization, with applications across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A General Online Algorithm for Optimizing Complex Performance Metrics
Wojciech Kot{l}owski, Marek Wydmuch, Erik Schultheis, Rohit Babbar, Krzysztof Dembczy'nski
We consider sequential maximization of performance metrics that are general functions of a confusion matrix of a classifier (such as precision, F-measure, or G-mean). Such metrics are, in general, non-decomposable over individual instances, making their optimization very challenging. While they have been extensively studied under different frameworks in the batch setting, their analysis in the online learning regime is very limited, with only a few distinguished exceptions. In this paper, we introduce and analyze a general online algorithm that can be used in a straightforward way with a variety of complex performance metrics in binary, multi-class, and multi-label classification problems. The algorithm's update and prediction rules are appealingly simple and computationally efficient without the need to store any past data. We show the algorithm attains $mathcal{O}(frac{ln n}{n})$ regret for concave and smooth metrics and verify the efficiency of the proposed algorithm in empirical studies.
Read more6/24/2024
🏷️
0
Consistent algorithms for multi-label classification with macro-at-$k$ metrics
Erik Schultheis, Wojciech Kot{l}owski, Marek Wydmuch, Rohit Babbar, Strom Borman, Krzysztof Dembczy'nski
We consider the optimization of complex performance metrics in multi-label classification under the population utility framework. We mainly focus on metrics linearly decomposable into a sum of binary classification utilities applied separately to each label with an additional requirement of exactly $k$ labels predicted for each instance. These macro-at-$k$ metrics possess desired properties for extreme classification problems with long tail labels. Unfortunately, the at-$k$ constraint couples the otherwise independent binary classification tasks, leading to a much more challenging optimization problem than standard macro-averages. We provide a statistical framework to study this problem, prove the existence and the form of the optimal classifier, and propose a statistically consistent and practical learning algorithm based on the Frank-Wolfe method. Interestingly, our main results concern even more general metrics being non-linear functions of label-wise confusion matrices. Empirical results provide evidence for the competitive performance of the proposed approach.
Read more7/2/2024
🛠️
0
Faster Margin Maximization Rates for Generic and Adversarially Robust Optimization Methods
Guanghui Wang, Zihao Hu, Claudio Gentile, Vidya Muthukumar, Jacob Abernethy
First-order optimization methods tend to inherently favor certain solutions over others when minimizing an underdetermined training objective that has multiple global optima. This phenomenon, known as implicit bias, plays a critical role in understanding the generalization capabilities of optimization algorithms. Recent research has revealed that in separable binary classification tasks gradient-descent-based methods exhibit an implicit bias for the $ell_2$-maximal margin classifier. Similarly, generic optimization methods, such as mirror descent and steepest descent, have been shown to converge to maximal margin classifiers defined by alternative geometries. While gradient-descent-based algorithms provably achieve fast implicit bias rates, corresponding rates in the literature for generic optimization methods are relatively slow. To address this limitation, we present a series of state-of-the-art implicit bias rates for mirror descent and steepest descent algorithms. Our primary technique involves transforming a generic optimization algorithm into an online optimization dynamic that solves a regularized bilinear game, providing a unified framework for analyzing the implicit bias of various optimization methods. Our accelerated rates are derived by leveraging the regret bounds of online learning algorithms within this game framework. We then show the flexibility of this framework by analyzing the implicit bias in adversarial training, and again obtain significantly improved convergence rates.
Read more4/9/2024
🛠️
0
A Generalized Approach to Online Convex Optimization
Mohammad Pedramfar, Vaneet Aggarwal
In this paper, we analyze the problem of online convex optimization in different settings. We show that any algorithm for online linear optimization with fully adaptive adversaries is an algorithm for online convex optimization. We also show that any such algorithm that requires full-information feedback may be transformed to an algorithm with semi-bandit feedback with comparable regret bound. We further show that algorithms that are designed for fully adaptive adversaries using deterministic semi-bandit feedback can obtain similar bounds using only stochastic semi-bandit feedback when facing oblivious adversaries. We use this to describe general meta-algorithms to convert first order algorithms to zeroth order algorithms with comparable regret bounds. Our framework allows us to analyze online optimization in various settings, such full-information feedback, bandit feedback, stochastic regret, adversarial regret and various forms of non-stationary regret.
Read more5/15/2024