Generalizable and Scalable Multistage Biomedical Concept Normalization Leveraging Large Language Models
2405.15122
0
0

Abstract
Background: Biomedical entity normalization is critical to biomedical research because the richness of free-text clinical data, such as progress notes, can often be fully leveraged only after translating words and phrases into structured and coded representations suitable for analysis. Large Language Models (LLMs), in turn, have shown great potential and high performance in a variety of natural language processing (NLP) tasks, but their application for normalization remains understudied. Methods: We applied both proprietary and open-source LLMs in combination with several rule-based normalization systems commonly used in biomedical research. We used a two-step LLM integration approach, (1) using an LLM to generate alternative phrasings of a source utterance, and (2) to prune candidate UMLS concepts, using a variety of prompting methods. We measure results by $F_{beta}$, where we favor recall over precision, and F1. Results: We evaluated a total of 5,523 concept terms and text contexts from a publicly available dataset of human-annotated biomedical abstracts. Incorporating GPT-3.5-turbo increased overall $F_{beta}$ and F1 in normalization systems +9.5 and +7.3 (MetaMapLite), +13.9 and +10.9 (QuickUMLS), and +10.5 and +10.3 (BM25), while the open-source Vicuna model achieved +10.8 and +12.2 (MetaMapLite), +14.7 and +15 (QuickUMLS), and +15.6 and +18.7 (BM25). Conclusions: Existing general-purpose LLMs, both propriety and open-source, can be leveraged at scale to greatly improve normalization performance using existing tools, with no fine-tuning.
Create account to get full access
Overview
- This paper presents a generalizable and scalable multistage biomedical concept normalization approach that leverages large language models (LLMs).
- The proposed method aims to address the challenges of concept normalization, which is the process of mapping text mentions to their corresponding biomedical concepts in a knowledge base.
- The authors develop a flexible framework that can be applied to different biomedical domains and datasets, and demonstrate its effectiveness on several benchmark tasks.
Plain English Explanation
The paper describes a new way to automatically link text references to biomedical concepts, such as diseases, treatments, or genes. This process, called "concept normalization," is important for tasks like medical record analysis and drug discovery.
The key idea is to use large language models (LLMs) - advanced AI systems trained on vast amounts of text data - to help with this task. The authors develop a multi-stage approach that first uses the LLMs to suggest possible concept matches, and then refines those suggestions using additional techniques.
This approach has several advantages. It is generalizable, meaning it can be applied to different biomedical domains and datasets, rather than being tailored to a specific use case. It is also scalable, allowing it to handle large volumes of text efficiently. The use of powerful LLMs helps improve the accuracy of the concept normalization process.
By making concept normalization more effective and broadly applicable, this research could have important implications for a wide range of biomedical applications, from improved analysis of patient records to accelerated drug discovery. The methods described in this paper build on previous work using LLMs for biomedical natural language processing tasks.
Technical Explanation
The authors propose a multistage biomedical concept normalization framework that leverages the capabilities of large language models (LLMs). The framework consists of several key components:
- Candidate Generation: An initial candidate generation stage uses the LLM to produce a list of potential concept matches for each text mention.
- Candidate Ranking: A ranking model, also based on the LLM, is then used to score and order the candidate concepts.
- Disambiguation: Finally, a disambiguation stage employs additional techniques, such as contextual information and knowledge base lookup, to refine the final concept normalization result.
The authors evaluate this approach on several benchmark datasets covering different biomedical domains, including clinical named entity recognition and public health classification. They demonstrate that the multistage framework outperforms previous state-of-the-art methods, particularly in terms of generalizability and scalability.
The authors also present an analysis of the impact of various design choices, such as the specific LLM architecture and the techniques used in the disambiguation stage. This provides insights into the key factors driving the performance of the proposed approach.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed concept normalization framework, considering multiple biomedical domains and datasets. The use of LLMs is a promising direction, as these models have shown strong performance on a variety of natural language processing tasks, including those in the biomedical field.
However, the authors do acknowledge some limitations of their approach. For example, the framework still relies on the availability of high-quality training data and knowledge bases, which may not be readily available for all biomedical sub-domains. Additionally, the authors note that the disambiguation stage could potentially be improved by incorporating more advanced techniques, such as those leveraging cross-source information.
It would also be valuable to see the framework evaluated on more diverse datasets, including those with lesser-known or rare biomedical concepts, to further assess its generalizability. Additionally, the authors could explore the framework's performance on long-tail entities, which can be particularly challenging for concept normalization systems.
Conclusion
This paper presents a highly promising approach to biomedical concept normalization that leverages the power of large language models. The proposed multistage framework demonstrates strong performance across multiple benchmarks, while also offering the benefits of generalizability and scalability.
By advancing the state-of-the-art in this important task, the authors' work could have significant implications for a wide range of biomedical applications, from improved clinical decision support to accelerated drug discovery. The insights and techniques described in this paper build upon and complement related research in the field of biomedical natural language processing.
Overall, this paper represents an important contribution to the ongoing efforts to develop more effective and versatile tools for processing and extracting meaningful insights from the vast and ever-expanding corpus of biomedical literature and data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
Duygu Altinok
0
0
Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
5/8/2024
👁️
LLMs in Biomedicine: A study on clinical Named Entity Recognition
Masoud Monajatipoor, Jiaxin Yang, Joel Stremmel, Melika Emami, Fazlolah Mohaghegh, Mozhdeh Rouhsedaghat, Kai-Wei Chang
0
0
Large Language Models (LLMs) demonstrate remarkable versatility in various NLP tasks but encounter distinct challenges in biomedicine due to medical language complexities and data scarcity. This paper investigates the application of LLMs in the medical domain by exploring strategies to enhance their performance for the Named-Entity Recognition (NER) task. Specifically, our study reveals the importance of meticulously designed prompts in biomedicine. Strategic selection of in-context examples yields a notable improvement, showcasing ~15-20% increase in F1 score across all benchmark datasets for few-shot clinical NER. Additionally, our findings suggest that integrating external resources through prompting strategies can bridge the gap between general-purpose LLM proficiency and the specialized demands of medical NER. Leveraging a medical knowledge base, our proposed method inspired by Retrieval-Augmented Generation (RAG) can boost the F1 score of LLMs for zero-shot clinical NER. We will release the code upon publication.
4/12/2024
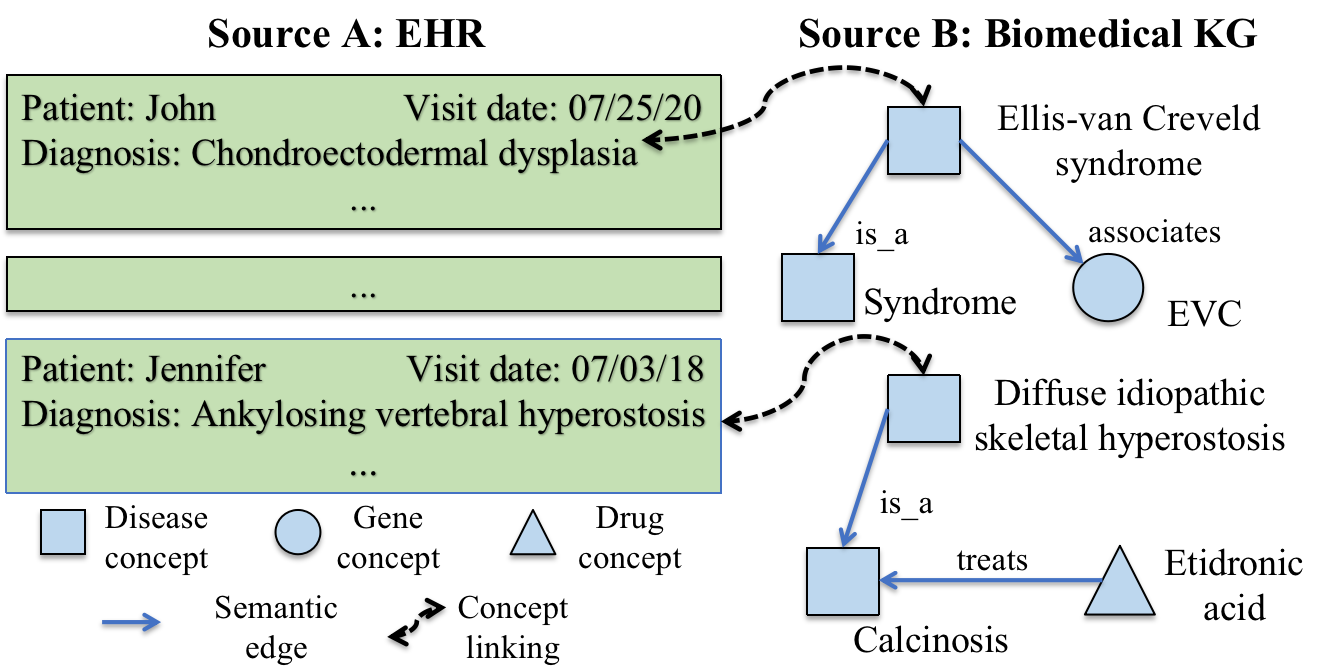
PromptLink: Leveraging Large Language Models for Cross-Source Biomedical Concept Linking
Yuzhang Xie, Jiaying Lu, Joyce Ho, Fadi Nahab, Xiao Hu, Carl Yang
0
0
Linking (aligning) biomedical concepts across diverse data sources enables various integrative analyses, but it is challenging due to the discrepancies in concept naming conventions. Various strategies have been developed to overcome this challenge, such as those based on string-matching rules, manually crafted thesauri, and machine learning models. However, these methods are constrained by limited prior biomedical knowledge and can hardly generalize beyond the limited amounts of rules, thesauri, or training samples. Recently, large language models (LLMs) have exhibited impressive results in diverse biomedical NLP tasks due to their unprecedentedly rich prior knowledge and strong zero-shot prediction abilities. However, LLMs suffer from issues including high costs, limited context length, and unreliable predictions. In this research, we propose PromptLink, a novel biomedical concept linking framework that leverages LLMs. It first employs a biomedical-specialized pre-trained language model to generate candidate concepts that can fit in the LLM context windows. Then it utilizes an LLM to link concepts through two-stage prompts, where the first-stage prompt aims to elicit the biomedical prior knowledge from the LLM for the concept linking task and the second-stage prompt enforces the LLM to reflect on its own predictions to further enhance their reliability. Empirical results on the concept linking task between two EHR datasets and an external biomedical KG demonstrate the effectiveness of PromptLink. Furthermore, PromptLink is a generic framework without reliance on additional prior knowledge, context, or training data, making it well-suited for concept linking across various types of data sources. The source code is available at https://github.com/constantjxyz/PromptLink.
5/14/2024
💬
Comparative Analysis of Open-Source Language Models in Summarizing Medical Text Data
Yuhao Chen, Zhimu Wang, Bo Wen, Farhana Zulkernine
0
0
Unstructured text in medical notes and dialogues contains rich information. Recent advancements in Large Language Models (LLMs) have demonstrated superior performance in question answering and summarization tasks on unstructured text data, outperforming traditional text analysis approaches. However, there is a lack of scientific studies in the literature that methodically evaluate and report on the performance of different LLMs, specifically for domain-specific data such as medical chart notes. We propose an evaluation approach to analyze the performance of open-source LLMs such as Llama2 and Mistral for medical summarization tasks, using GPT-4 as an assessor. Our innovative approach to quantitative evaluation of LLMs can enable quality control, support the selection of effective LLMs for specific tasks, and advance knowledge discovery in digital health.
5/31/2024