Comparative Analysis of Open-Source Language Models in Summarizing Medical Text Data
2405.16295
0
0
💬
Abstract
Unstructured text in medical notes and dialogues contains rich information. Recent advancements in Large Language Models (LLMs) have demonstrated superior performance in question answering and summarization tasks on unstructured text data, outperforming traditional text analysis approaches. However, there is a lack of scientific studies in the literature that methodically evaluate and report on the performance of different LLMs, specifically for domain-specific data such as medical chart notes. We propose an evaluation approach to analyze the performance of open-source LLMs such as Llama2 and Mistral for medical summarization tasks, using GPT-4 as an assessor. Our innovative approach to quantitative evaluation of LLMs can enable quality control, support the selection of effective LLMs for specific tasks, and advance knowledge discovery in digital health.
Create account to get full access
Overview
- This paper conducts a comparative analysis of open-source language models in summarizing medical text data.
- The researchers evaluate the performance of different large language models, including GPT-2, BART, and T5, on biomedical summarization tasks.
- The goal is to determine which model(s) are most effective at generating concise and informative summaries of medical text data.
Plain English Explanation
This study looks at how well different AI language models can summarize medical text. Language models are machine learning models that can understand and generate human language. The researchers tested several popular open-source language models, including GPT-2, BART, and T5, to see how good they are at summarizing medical articles and other biomedical text.
The key idea is to find out which language model(s) can best capture the important information in medical text and generate a concise, informative summary. This could be very useful for healthcare professionals who need to quickly understand the main points of research papers or patient records. By comparing the performance of different models, the researchers aim to identify the most promising approaches for biomedical text summarization.
Technical Explanation
The paper evaluates the performance of several open-source large language models (LLMs) - including GPT-2, BART, and T5 - on biomedical summarization tasks. LLMs are powerful neural networks trained on massive amounts of text data that can generate human-like language.
The researchers fine-tuned these pre-trained LLMs on a dataset of medical abstracts and evaluated them on several automatic summarization metrics, such as ROUGE and BERTScore. They also compared the models' performance to that of a supervised summarization model trained specifically for the biomedical domain.
The results show that the fine-tuned LLMs, particularly BART and T5, outperformed the domain-specific supervised model on most evaluation metrics. This suggests that adapting large, general-purpose language models can be an effective approach for biomedical text summarization, potentially outperforming models trained solely on medical data. The paper also discusses insights into the strengths and limitations of each LLM architecture.
Critical Analysis
The paper provides a thorough and well-designed evaluation of different language models for the task of biomedical text summarization. The researchers make a strong case for the effectiveness of adapting large, general-purpose language models like BART and T5 for this domain, which is an important finding.
However, the paper does not delve deeply into the potential limitations or challenges of this approach. For example, it does not address how well these models would perform on more specialized or technical medical texts, or how they would handle rare or domain-specific terminology. Additionally, the paper does not discuss the computational resources and training time required to fine-tune these large models, which could be a barrier to practical deployment.
Further research could explore ways to more efficiently adapt LLMs for medical applications or compare their performance to human-written summaries. It would also be valuable to assess the models' performance on a wider range of public health and medical tasks to better understand their broader capabilities and limitations in this domain.
Conclusion
This study demonstrates the potential of adapting large, pre-trained language models for the task of biomedical text summarization. The researchers found that fine-tuned versions of BART and T5 outperformed a domain-specific supervised model, suggesting that leveraging the capabilities of general-purpose LLMs can be an effective approach for this application.
While the results are promising, further research is needed to address the limitations and challenges of this approach, such as handling specialized medical terminology and optimizing the fine-tuning process. Overall, this work contributes valuable insights into the use of advanced language models for summarizing important medical information, which could have significant implications for healthcare professionals and researchers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization
Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, Eduardo Pontes Reis, Anna Seehofnerova, Nidhi Rohatgi, Poonam Hosamani, William Collins, Neera Ahuja, Curtis P. Langlotz, Jason Hom, Sergios Gatidis, John Pauly, Akshay S. Chaudhari
0
0
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP), their effectiveness on a diverse range of clinical summarization tasks remains unproven. In this study, we apply adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Quantitative assessments with syntactic, semantic, and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with ten physicians evaluates summary completeness, correctness, and conciseness; in a majority of cases, summaries from our best adapted LLMs are either equivalent (45%) or superior (36%) compared to summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care.
4/15/2024
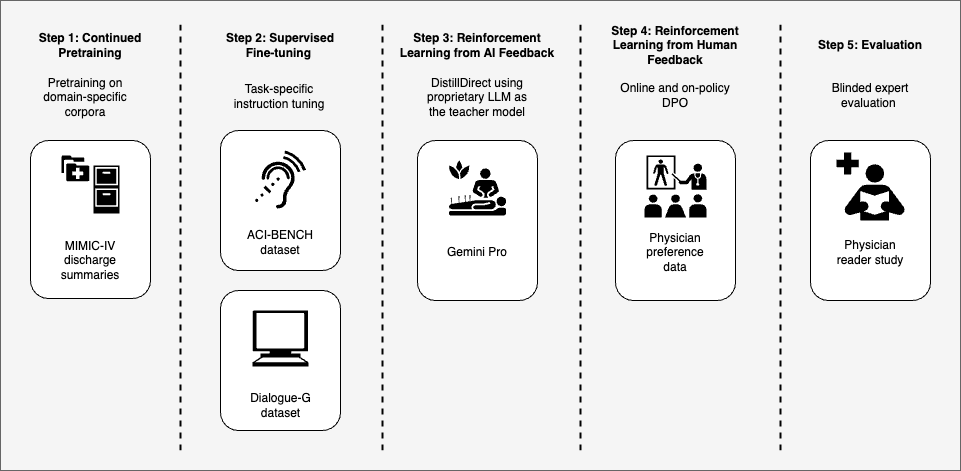
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
0
0
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
6/11/2024
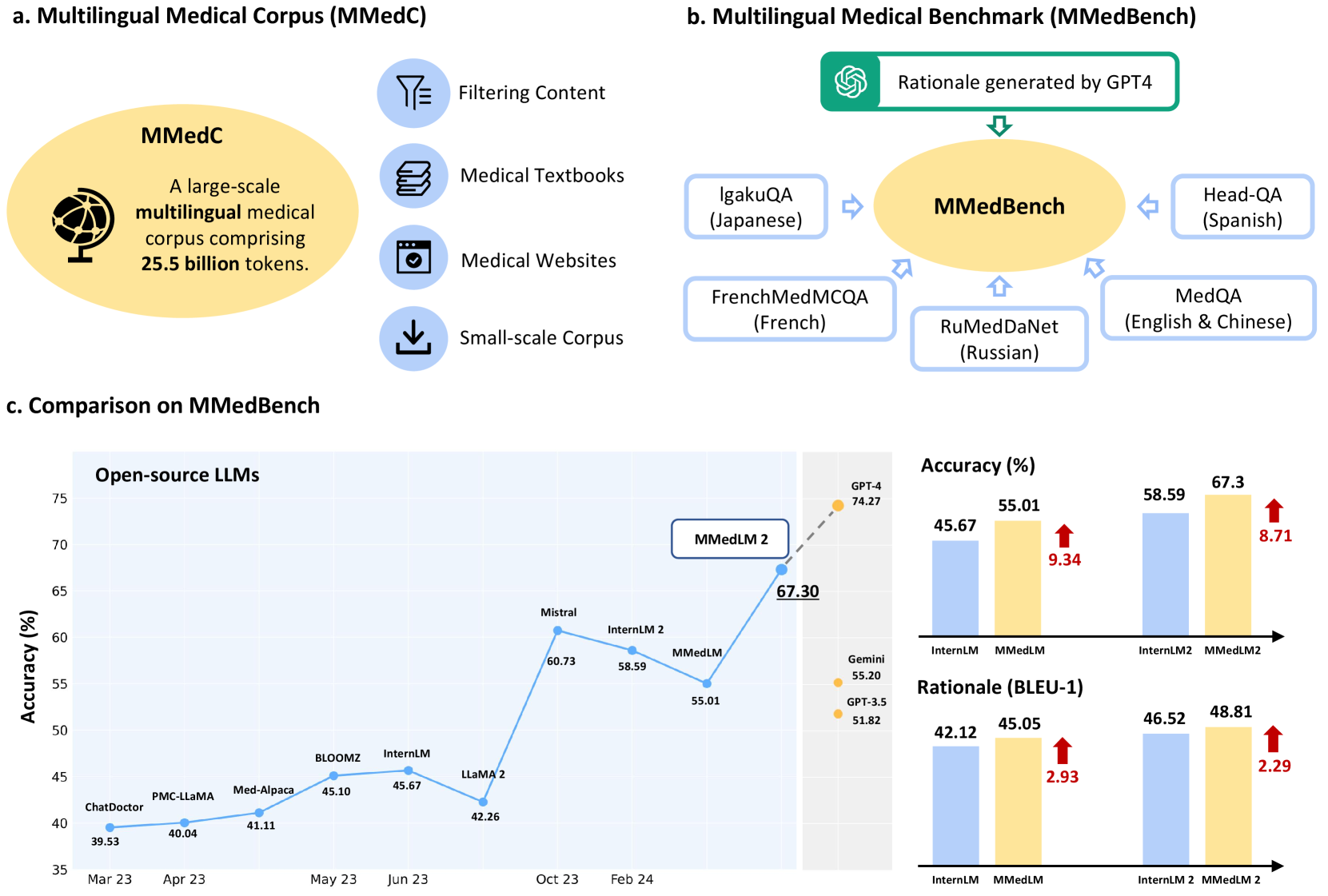
Towards Building Multilingual Language Model for Medicine
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, Weidi Xie
0
0
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
6/4/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024