Generalized Fake Audio Detection via Deep Stable Learning

0
Sign in to get full access
Overview
- The paper proposes a method called "Generalized Fake Audio Detection via Deep Stable Learning" to detect fake audio generated by deepfake technologies.
- The method aims to improve the generalization capabilities of deepfake audio detection models, allowing them to perform well on a wider range of unseen data.
- The key contributions include a novel training strategy, model architecture, and evaluation methodology to enhance the robustness and generalization of deepfake audio detection.
Plain English Explanation
The paper introduces a new way to detect fake audio that has been generated using deepfake technology. Deepfakes are audio or video manipulations that make it seem like a person said or did something they didn't actually do. This can be used to spread misinformation or create fake content.
The researchers developed a method that helps detection models become more "generalized," meaning they can accurately identify deepfake audio even when it's quite different from the training data they were exposed to. This is important because deepfake techniques are constantly evolving, so detection models need to be able to adapt and work well on a wide variety of fake audio samples.
The method involves a novel training strategy, a unique model architecture, and a thorough evaluation process to ensure the detection system is robust and can generalize well. By making the detection models more flexible and adaptable, the researchers aim to stay ahead of advancing deepfake technologies and better protect against the spread of misinformation.
Technical Explanation
The paper proposes a "Generalized Fake Audio Detection via Deep Stable Learning" (GFAD-DSL) method to improve the generalization capabilities of deepfake audio detection models. The key technical components include:
-
Training Strategy: The researchers introduce a "deep stable learning" approach that encourages the detection model to learn stable and robust representations. This involves optimizing the model to maintain similar outputs when small perturbations are applied to the input audio.
-
Model Architecture: The GFAD-DSL method uses a convolutional neural network (CNN) as the base model, with additional "stability branches" that enforce the stability objective during training. This helps the model learn representations that are less sensitive to variations in the input data.
-
Evaluation Methodology: The paper introduces a comprehensive evaluation protocol that tests the detection model's performance on a wide range of unseen deepfake audio samples, including ones with different acoustic conditions, speakers, and deepfake generation techniques. This allows the researchers to rigorously assess the model's generalization abilities.
Through these technical innovations, the GFAD-DSL method aims to enhance the robustness and generalization of deepfake audio detection, enabling the models to maintain high performance even as deepfake technologies continue to evolve.
Critical Analysis
The paper presents a well-designed and thorough approach to improving the generalization of deepfake audio detection models. The authors acknowledge that while existing detection methods have achieved strong performance on specific datasets, their ability to generalize to diverse, unseen deepfake samples remains a significant challenge.
One potential limitation of the research is that the evaluation is still conducted on a relatively limited set of deepfake audio samples, even though the protocol is more comprehensive than previous studies. The authors mention that further diversifying the evaluation data, including real-world scenarios, would be an important next step to fully assess the method's practical applicability.
Additionally, the paper does not provide a detailed analysis of the computational and resource requirements of the GFAD-DSL method, which could be an important consideration for real-world deployment. Exploring the trade-offs between model complexity, performance, and efficiency would be valuable for understanding the practical implications of the proposed approach.
Overall, the research represents a significant contribution to the field of deepfake audio detection, demonstrating the importance of developing generalized and robust detection models to stay ahead of the rapidly evolving deepfake landscape. The technical innovations and evaluation methodology presented in this paper provide a solid foundation for future research in this area.
Conclusion
The paper introduces a novel "Generalized Fake Audio Detection via Deep Stable Learning" (GFAD-DSL) method to improve the generalization capabilities of deepfake audio detection models. By incorporating a deep stable learning training strategy, a specialized model architecture, and a comprehensive evaluation protocol, the researchers have developed a more robust and adaptable detection system.
This work is particularly important as deepfake technologies continue to advance, making it increasingly challenging for detection models to maintain high performance on diverse, unseen samples. The GFAD-DSL method represents a significant step forward in addressing this challenge and provides a valuable foundation for future research in this critical area of protecting against the spread of misinformation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generalized Fake Audio Detection via Deep Stable Learning
Zhiyong Wang, Ruibo Fu, Zhengqi Wen, Yuankun Xie, Yukun Liu, Xiaopeng Wang, Xuefei Liu, Yongwei Li, Jianhua Tao, Yi Lu, Xin Qi, Shuchen Shi
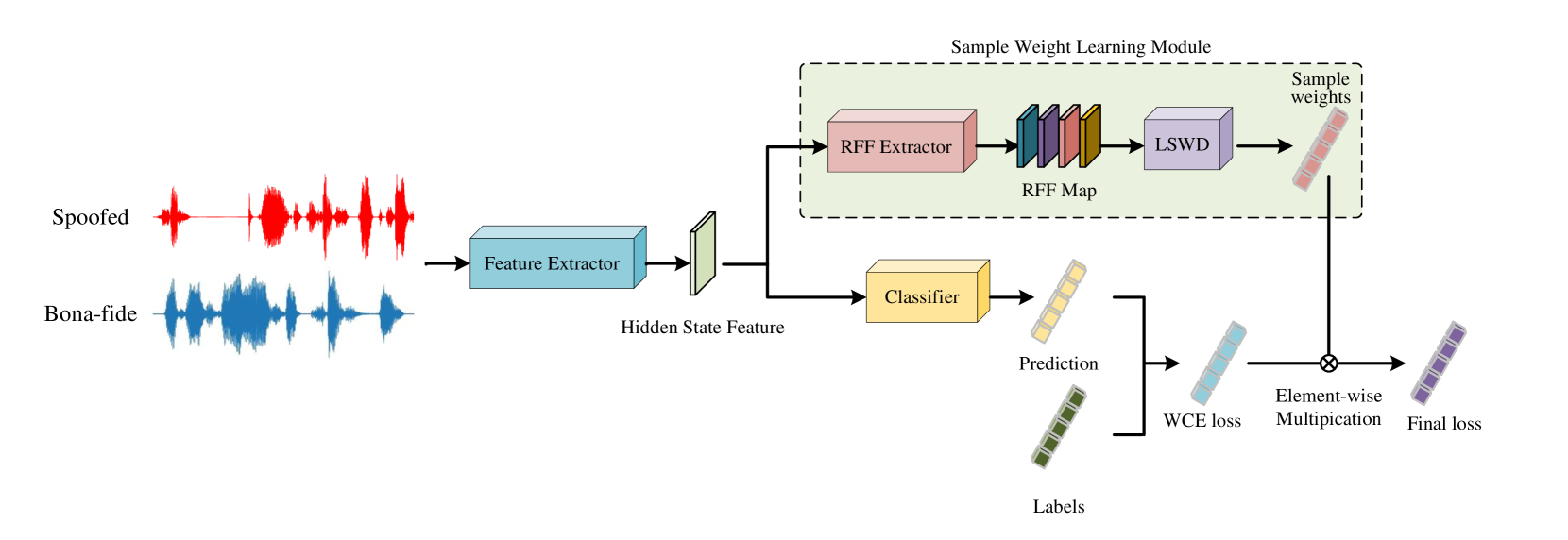
Although current fake audio detection approaches have achieved remarkable success on specific datasets, they often fail when evaluated with datasets from different distributions. Previous studies typically address distribution shift by focusing on using extra data or applying extra loss restrictions during training. However, these methods either require a substantial amount of data or complicate the training process. In this work, we propose a stable learning-based training scheme that involves a Sample Weight Learning (SWL) module, addressing distribution shift by decorrelating all selected features via learning weights from training samples. The proposed portable plug-in-like SWL is easy to apply to multiple base models and generalizes them without using extra data during training. Experiments conducted on the ASVspoof datasets clearly demonstrate the effectiveness of SWL in generalizing different models across three evaluation datasets from different distributions.
Read more6/6/2024

0
Advancing Continual Learning for Robust Deepfake Audio Classification
Feiyi Dong, Qingchen Tang, Yichen Bai, Zihan Wang
The emergence of new spoofing attacks poses an increasing challenge to audio security. Current detection methods often falter when faced with unseen spoofing attacks. Traditional strategies, such as retraining with new data, are not always feasible due to extensive storage. This paper introduces a novel continual learning method Continual Audio Defense Enhancer (CADE). First, by utilizing a fixed memory size to store randomly selected samples from previous datasets, our approach conserves resources and adheres to privacy constraints. Additionally, we also apply two distillation losses in CADE. By distillation in classifiers, CADE ensures that the student model closely resembles that of the teacher model. This resemblance helps the model retain old information while facing unseen data. We further refine our model's performance with a novel embedding similarity loss that extends across multiple depth layers, facilitating superior positive sample alignment. Experiments conducted on the ASVspoof2019 dataset show that our proposed method outperforms the baseline methods.
Read more7/16/2024
0
Enhancing Generalization in Audio Deepfake Detection: A Neural Collapse based Sampling and Training Approach
Mohammed Yousif, Jonat John Mathew, Huzaifa Pallan, Agamjeet Singh Padda, Syed Daniyal Shah, Sara Adamski, Madhu Reddiboina, Arjun Pankajakshan
Generalization in audio deepfake detection presents a significant challenge, with models trained on specific datasets often struggling to detect deepfakes generated under varying conditions and unknown algorithms. While collectively training a model using diverse datasets can enhance its generalization ability, it comes with high computational costs. To address this, we propose a neural collapse-based sampling approach applied to pre-trained models trained on distinct datasets to create a new training database. Using ASVspoof 2019 dataset as a proof-of-concept, we implement pre-trained models with Resnet and ConvNext architectures. Our approach demonstrates comparable generalization on unseen data while being computationally efficient, requiring less training data. Evaluation is conducted using the In-the-wild dataset.
Read more4/22/2024

0
Toward Improving Synthetic Audio Spoofing Detection Robustness via Meta-Learning and Disentangled Training With Adversarial Examples
Zhenyu Wang, John H. L. Hansen
Advances in automatic speaker verification (ASV) promote research into the formulation of spoofing detection systems for real-world applications. The performance of ASV systems can be degraded severely by multiple types of spoofing attacks, namely, synthetic speech (SS), voice conversion (VC), replay, twins and impersonation, especially in the case of unseen synthetic spoofing attacks. A reliable and robust spoofing detection system can act as a security gate to filter out spoofing attacks instead of having them reach the ASV system. A weighted additive angular margin loss is proposed to address the data imbalance issue, and different margins has been assigned to improve generalization to unseen spoofing attacks in this study. Meanwhile, we incorporate a meta-learning loss function to optimize differences between the embeddings of support versus query set in order to learn a spoofing-category-independent embedding space for utterances. Furthermore, we craft adversarial examples by adding imperceptible perturbations to spoofing speech as a data augmentation strategy, then we use an auxiliary batch normalization (BN) to guarantee that corresponding normalization statistics are performed exclusively on the adversarial examples. Additionally, A simple attention module is integrated into the residual block to refine the feature extraction process. Evaluation results on the Logical Access (LA) track of the ASVspoof 2019 corpus provides confirmation of our proposed approaches' effectiveness in terms of a pooled EER of 0.87%, and a min t-DCF of 0.0277. These advancements offer effective options to reduce the impact of spoofing attacks on voice recognition/authentication systems.
Read more8/27/2024