Generalized Regression with Conditional GANs
2404.13500
0
0
↗️
Abstract
Regression is typically treated as a curve-fitting process where the goal is to fit a prediction function to data. With the help of conditional generative adversarial networks, we propose to solve this age-old problem in a different way; we aim to learn a prediction function whose outputs, when paired with the corresponding inputs, are indistinguishable from feature-label pairs in the training dataset. We show that this approach to regression makes fewer assumptions on the distribution of the data we are fitting to and, therefore, has better representation capabilities. We draw parallels with generalized linear models in statistics and show how our proposal serves as an extension of them to neural networks. We demonstrate the superiority of this new approach to standard regression with experiments on multiple synthetic and publicly available real-world datasets, finding encouraging results, especially with real-world heavy-tailed regression datasets. To make our work more reproducible, we release our source code. Link to repository: https://anonymous.4open.science/r/regressGAN-7B71/
Create account to get full access
Overview
- This paper introduces a new method called Generalized Regression with Conditional GANs (GReCon) for modeling heavy-tailed distributions in regression problems.
- The approach uses a conditional generative adversarial network (GAN) architecture to learn a flexible mapping between input features and target variables, allowing it to capture complex nonlinear relationships.
- The authors demonstrate the effectiveness of GReCon on several benchmark datasets, showing that it outperforms traditional regression methods in terms of predictive accuracy, especially for heavy-tailed target variables.
Plain English Explanation
Generalized Regression with Conditional GANs tackles the challenge of modeling real-world data that doesn't follow a simple, well-behaved distribution. In many applications, the target variable we want to predict may have a "heavy-tailed" distribution, meaning there's a higher chance of observing very large or small values compared to a normal distribution.
The authors propose using a type of machine learning model called a conditional generative adversarial network (cGAN) to handle these complex, non-standard distributions. A cGAN works by training two neural networks to compete with each other - one tries to generate realistic-looking data, while the other tries to distinguish the generated data from real data. This adversarial training process allows the cGAN to learn a flexible mapping between the input features and the target variable, capturing nonlinear relationships that traditional regression methods might miss.
The key innovation in this paper is applying the cGAN framework to regression problems, where the goal is to predict a continuous target variable rather than generate new data. The authors call their approach Generalized Regression with Conditional GANs (GReCon), and show through experiments on benchmark datasets that it outperforms standard regression techniques, especially when the target variable has a heavy-tailed distribution.
Technical Explanation
Generalized Regression with Conditional GANs presents a new method for tackling regression problems with non-Gaussian target variables. The authors introduce Generalized Regression with Conditional GANs (GReCon), which leverages the flexibility of conditional generative adversarial networks (cGANs) to learn a mapping between input features and target variables.
In a standard regression setup, the goal is to predict a continuous target variable y given a set of input features x. Traditional regression techniques, such as linear or polynomial regression, make assumptions about the underlying distribution of y (e.g., Gaussian). However, many real-world datasets exhibit heavy-tailed distributions, where there is a higher probability of observing very large or small values compared to a normal distribution.
To address this, the authors propose using a cGAN architecture, where the generator network learns to map the input features x to the target variable y, while the discriminator network tries to distinguish the generator's outputs from the true training data. This adversarial training process allows the cGAN to capture complex, nonlinear relationships between x and y, without making restrictive assumptions about the distribution of y.
The authors evaluate GReCon on several benchmark regression datasets, including both synthetic and real-world examples with heavy-tailed target variables. The results show that GReCon outperforms traditional regression methods, such as Causal Representation Learning from Multiple Distributions, MCL-GAN: Generative Adversarial Networks for Multiple Specialized Classifiers, and SAN: Inducing Metrizability in GAN Discriminative Normalized Linear, particularly when the target variable has a heavy-tailed distribution.
Critical Analysis
The key strength of Generalized Regression with Conditional GANs is its ability to model complex, non-Gaussian target variables, which are common in many real-world regression problems. By leveraging the flexible mapping capabilities of cGANs, the GReCon method can capture nonlinear relationships and heavy-tailed distributions that would be challenging for traditional regression techniques.
However, the paper also acknowledges several limitations and areas for further research. First, the training of cGANs can be notoriously unstable, and the authors note that careful hyperparameter tuning is required to ensure convergence. Additionally, the interpretation of the learned mapping between inputs and outputs in a cGAN-based model is less straightforward compared to more interpretable regression methods, such as Advancing Ante-hoc Explainable Models through Generative Approaches.
Another potential concern is the computational complexity of GReCon, as training a cGAN can be more resource-intensive than traditional regression approaches. The authors do not provide a detailed analysis of the runtime or memory requirements of their method, which would be useful for practitioners considering its real-world applicability.
Overall, Generalized Regression with Conditional GANs presents an interesting and promising approach for modeling complex regression problems with non-standard target variable distributions. However, further research is needed to address the stability, interpretability, and computational efficiency of the GReCon method, as well as to explore its performance on a wider range of real-world datasets.
Conclusion
Generalized Regression with Conditional GANs introduces a novel approach for tackling regression problems with heavy-tailed target variable distributions. By leveraging the flexible mapping capabilities of conditional generative adversarial networks, the GReCon method can capture complex, nonlinear relationships between input features and outputs, outperforming traditional regression techniques.
The key innovation of this work is the application of cGANs to regression problems, demonstrating the potential of adversarial training to model non-Gaussian target variables. While the method has some limitations in terms of stability, interpretability, and computational complexity, the results presented in the paper suggest that GReCon could be a valuable tool for a wide range of real-world regression tasks, particularly those involving heavy-tailed or otherwise non-standard target variable distributions.
Overall, this research advances the state of the art in regression modeling, offering a new perspective on how generative adversarial networks can be used to tackle complex, real-world prediction problems. As the field of machine learning continues to evolve, approaches like GReCon may become increasingly important for extracting insights from the growing abundance of complex, non-Gaussian data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MCGAN: Enhancing GAN Training with Regression-Based Generator Loss
Baoren Xiao, Hao Ni, Weixin Yang
0
0
Generative adversarial networks (GANs) have emerged as a powerful tool for generating high-fidelity data. However, the main bottleneck of existing approaches is the lack of supervision on the generator training, which often results in undamped oscillation and unsatisfactory performance. To address this issue, we propose an algorithm called Monte Carlo GAN (MCGAN). This approach, utilizing an innovative generative loss function, termly the regression loss, reformulates the generator training as a regression task and enables the generator training by minimizing the mean squared error between the discriminator's output of real data and the expected discriminator of fake data. We demonstrate the desirable analytic properties of the regression loss, including discriminability and optimality, and show that our method requires a weaker condition on the discriminator for effective generator training. These properties justify the strength of this approach to improve the training stability while retaining the optimality of GAN by leveraging strong supervision of the regression loss. Numerical results on CIFAR-10 and CIFAR-100 datasets demonstrate that the proposed MCGAN significantly and consistently improves the existing state-of-the-art GAN models in terms of quality, accuracy, training stability, and learned latent space. Furthermore, the proposed algorithm exhibits great flexibility for integrating with a variety of backbone models to generate spatial images, temporal time-series, and spatio-temporal video data.
5/28/2024
✨
Automatically Adaptive Conformal Risk Control
Vincent Blot (LISN, CNRS), Anastasios N Angelopoulos (UC Berkeley), Michael I Jordan (UC Berkeley, Inria), Nicolas J-B Brunel (ENSIIE)
0
0
Science and technology have a growing need for effective mechanisms that ensure reliable, controlled performance from black-box machine learning algorithms. These performance guarantees should ideally hold conditionally on the input-that is the performance guarantees should hold, at least approximately, no matter what the input. However, beyond stylized discrete groupings such as ethnicity and gender, the right notion of conditioning can be difficult to define. For example, in problems such as image segmentation, we want the uncertainty to reflect the intrinsic difficulty of the test sample, but this may be difficult to capture via a conditioning event. Building on the recent work of Gibbs et al. [2023], we propose a methodology for achieving approximate conditional control of statistical risks-the expected value of loss functions-by adapting to the difficulty of test samples. Our framework goes beyond traditional conditional risk control based on user-provided conditioning events to the algorithmic, data-driven determination of appropriate function classes for conditioning. We apply this framework to various regression and segmentation tasks, enabling finer-grained control over model performance and demonstrating that by continuously monitoring and adjusting these parameters, we can achieve superior precision compared to conventional risk-control methods.
6/27/2024
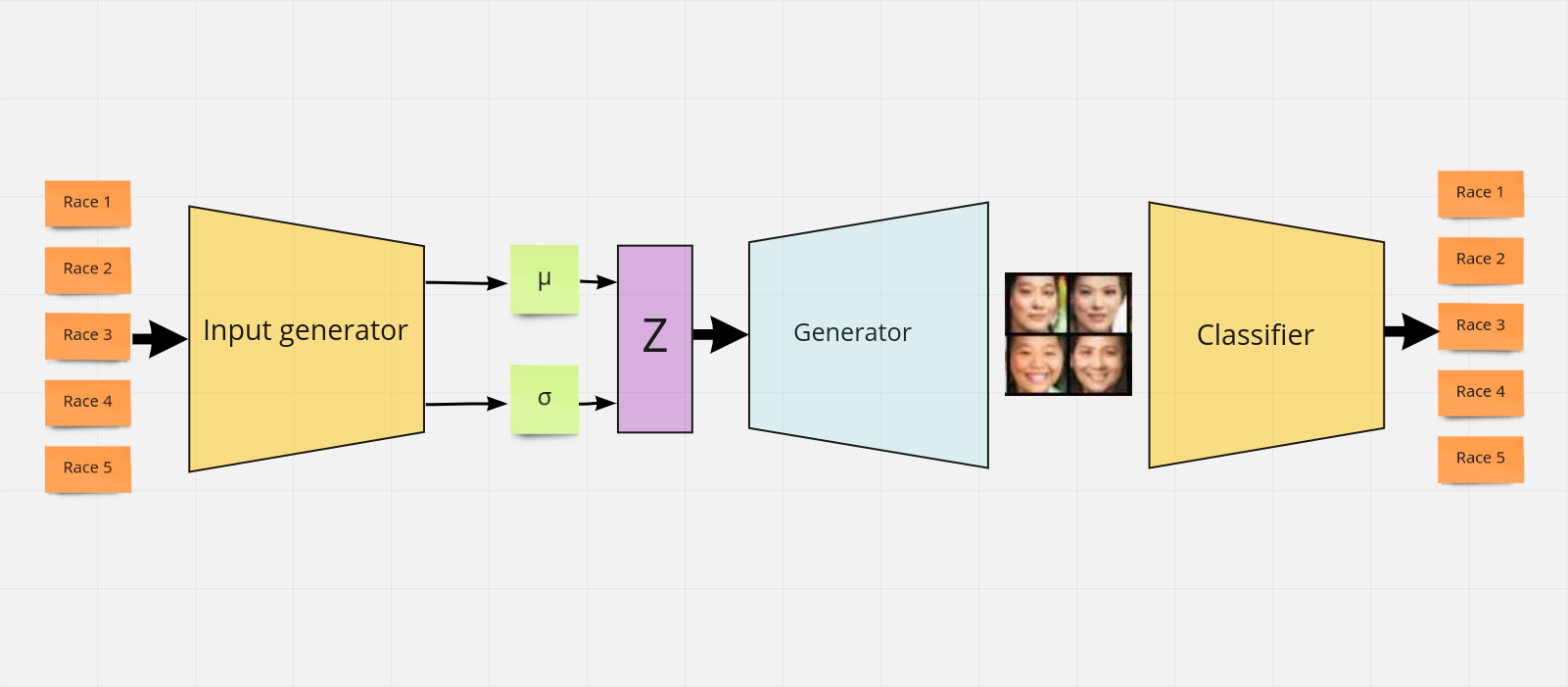
Conditioning GAN Without Training Dataset
Kidist Amde Mekonnen
0
0
Deep learning algorithms have a large number of trainable parameters often with sizes of hundreds of thousands or more. Training this algorithm requires a large amount of training data and generating a sufficiently large dataset for these algorithms is costlycite{noguchi2019image}. GANs are generative neural networks that use two deep learning networks that are competing with each other. The networks are generator and discriminator networks. The generator tries to generate realistic images which resemble the actual training dataset by approximating the training data distribution and the discriminator is trained to classify images as real or fake(generated)cite{goodfellow2016nips}. Training these GAN algorithms also requires a large amount of training datasetcite{noguchi2019image}. In this study, the aim is to address the question, Given an unconditioned pretrained generator network and a pretrained classifier, is it feasible to develop a conditioned generator without relying on any training dataset? The paper begins with a general introduction to the problem. The subsequent sections are structured as follows: Section 2 provides background information on the problem. Section 3 reviews relevant literature on the topic. Section 4 outlines the methodology employed in this study. Section 5 presents the experimental results. Section 6 discusses the findings and proposes potential future research directions. Finally, Section 7 offers concluding remarks. The implementation can be accessed href{https://github.com/kidist-amde/BigGAN-PyTorch}{here}.
6/3/2024

Gradient Aligned Regression via Pairwise Losses
Dixian Zhu, Tianbao Yang, Livnat Jerby
0
0
Regression is a fundamental task in machine learning that has garnered extensive attention over the past decades. The conventional approach for regression involves employing loss functions that primarily concentrate on aligning model prediction with the ground truth for each individual data sample. Recent research endeavors have introduced novel perspectives by incorporating label similarity to regression via imposing extra pairwise regularization on the latent feature space and demonstrated the effectiveness. However, there are two drawbacks for those approaches: i) their pairwise operation in latent feature space is computationally more expensive than conventional regression losses; ii) it lacks of theoretical justifications behind such regularization. In this work, we propose GAR (Gradient Aligned Regression) as a competitive alternative method in label space, which is constituted by a conventional regression loss and two pairwise label difference losses for gradient alignment including magnitude and direction. GAR enjoys: i) the same level efficiency as conventional regression loss because the quadratic complexity for the proposed pairwise losses can be reduced to linear complexity; ii) theoretical insights from learning the pairwise label difference to learning the gradient of the ground truth function. We limit our current scope as regression on the clean data setting without noises, outliers or distributional shifts, etc. We demonstrate the effectiveness of the proposed method practically on two synthetic datasets and on eight extensive real-world tasks from six benchmark datasets with other eight competitive baselines. Running time experiments demonstrate the superior efficiency of the proposed GAR over existing methods with pairwise regularization in latent feature space and ablation studies demonstrate the effectiveness of each component for GAR.
5/24/2024