Causal Representation Learning from Multiple Distributions: A General Setting
2402.05052
0
0
Abstract
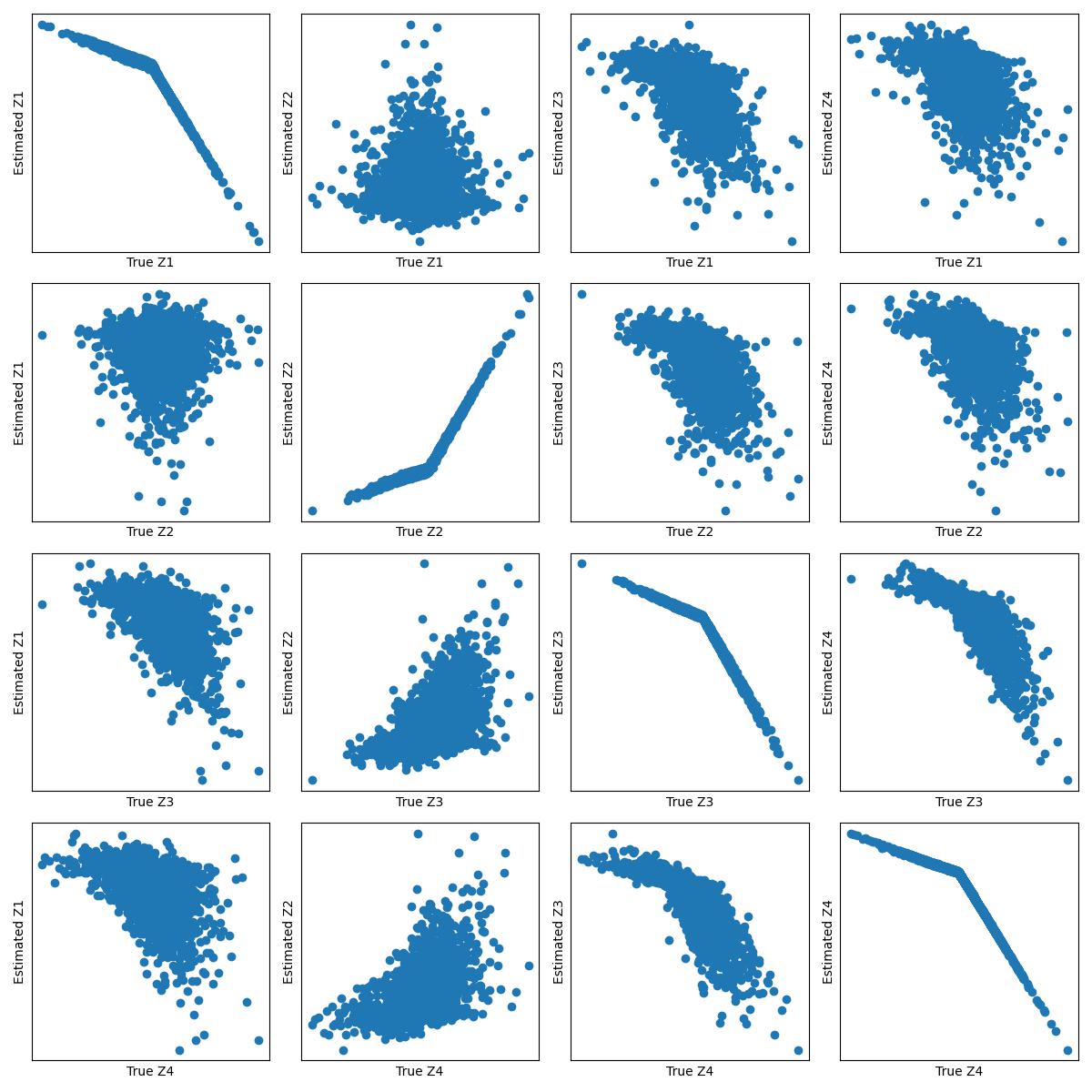
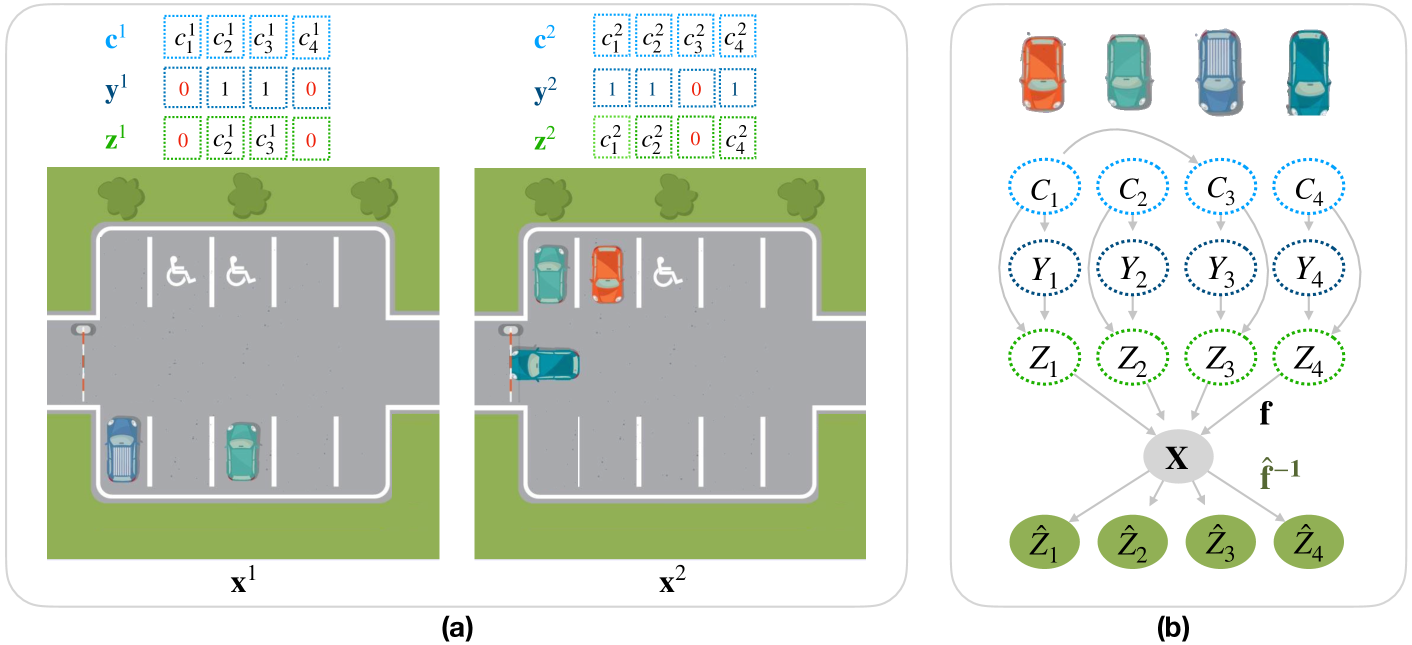
In many problems, the measured variables (e.g., image pixels) are just mathematical functions of the hidden causal variables (e.g., the underlying concepts or objects). For the purpose of making predictions in changing environments or making proper changes to the system, it is helpful to recover the hidden causal variables $Z_i$ and their causal relations represented by graph $mathcal{G}_Z$. This problem has recently been known as causal representation learning. This paper is concerned with a general, completely nonparametric setting of causal representation learning from multiple distributions (arising from heterogeneous data or nonstationary time series), without assuming hard interventions behind distribution changes. We aim to develop general solutions in this fundamental case; as a by product, this helps see the unique benefit offered by other assumptions such as parametric causal models or hard interventions. We show that under the sparsity constraint on the recovered graph over the latent variables and suitable sufficient change conditions on the causal influences, interestingly, one can recover the moralized graph of the underlying directed acyclic graph, and the recovered latent variables and their relations are related to the underlying causal model in a specific, nontrivial way. In some cases, each latent variable can even be recovered up to component-wise transformations. Experimental results verify our theoretical claims.
Create account to get full access
Overview
- This paper proposes a general framework for causal representation learning from multiple distributions.
- It aims to learn a representation that captures the underlying causal structure of the data, which can be useful for tasks like transfer learning, robustness, and interpretability.
- The framework leverages sparsity constraints to encourage the learned representations to align with the true causal structure.
Plain English Explanation
The paper is about a way to learn representations of data that capture the underlying causal relationships in the data, using information from multiple different datasets.
Causal relationships are the real-world connections between different variables - for example, the amount of rain causing the growth of plants. Learning representations that reflect these causal connections can be very useful, as it allows us to better understand the data, make more robust predictions, and transfer knowledge to new situations.
The key idea of the paper is to learn representations that are "sparse" - meaning they only capture the most important causal connections, and discard irrelevant information. This is done by adding special constraints during the representation learning process. The authors show that this approach can successfully recover the true causal structure of the data, even when the data comes from different distributions (i.e. different settings or environments).
Technical Explanation
The paper proposes a general framework for learning causal representations from multiple distributions. The core idea is to learn a low-dimensional representation of the data that captures the underlying causal structure, by incorporating sparsity constraints during the representation learning process.
Specifically, the framework assumes access to data from multiple different distributions (e.g. different environments or settings). The goal is to learn a representation that is (1) predictive of the target variable in each distribution, and (2) has a sparse dependence structure that aligns with the true causal structure.
To achieve this, the authors introduce a regularized optimization objective that encourages the learned representation to satisfy these two properties. The sparsity constraint is crucial, as it helps the model focus on extracting the most relevant causal features while discarding irrelevant information.
The authors provide theoretical analysis to show that under certain assumptions, the learned representation will converge to the true causal representation as the number of environments increases. They also demonstrate the effectiveness of their approach through experiments on both synthetic and real-world datasets.
Critical Analysis
The proposed framework is a promising approach for learning causal representations from diverse data sources. By leveraging sparsity constraints, it can extract the underlying causal structure in a robust and interpretable way.
However, the paper does make some assumptions that limit the generality of the approach. For example, it assumes the data-generating process is linear and additive, and that the causal graph is acyclic. Real-world data may not always satisfy these assumptions, so further research is needed to relax these constraints.
Additionally, the theoretical analysis relies on strong assumptions, such as the existence of a unique sparse representation that aligns with the true causal structure. In practice, this may not always be the case, and the algorithm may converge to local optima or fail to identify the true causal structure.
Future work could explore ways to make the framework more robust to violations of the assumptions, or to incorporate additional prior knowledge about the causal structure to guide the representation learning process. Investigating the performance of this approach on a wider range of real-world applications would also be valuable.
Conclusion
This paper presents a general framework for learning causal representations from multiple distributions, leveraging sparsity constraints to capture the underlying causal structure of the data. By learning representations that align with the true causal relationships, this approach can enable more robust, interpretable, and transferable machine learning models.
While the proposed method has some limitations, it represents an important step towards developing machine learning systems that can better understand and reason about the causal mechanisms generating the data they are trained on. As the field of causal representation learning continues to evolve, this work could have significant implications for a wide range of applications, from transfer learning to causal discovery and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Sparsity Principle for Partially Observable Causal Representation Learning
Danru Xu, Dingling Yao, S'ebastien Lachapelle, Perouz Taslakian, Julius von Kugelgen, Francesco Locatello, Sara Magliacane
0
0
Causal representation learning aims at identifying high-level causal variables from perceptual data. Most methods assume that all latent causal variables are captured in the high-dimensional observations. We instead consider a partially observed setting, in which each measurement only provides information about a subset of the underlying causal state. Prior work has studied this setting with multiple domains or views, each depending on a fixed subset of latents. Here, we focus on learning from unpaired observations from a dataset with an instance-dependent partial observability pattern. Our main contribution is to establish two identifiability results for this setting: one for linear mixing functions without parametric assumptions on the underlying causal model, and one for piecewise linear mixing functions with Gaussian latent causal variables. Based on these insights, we propose two methods for estimating the underlying causal variables by enforcing sparsity in the inferred representation. Experiments on different simulated datasets and established benchmarks highlight the effectiveness of our approach in recovering the ground-truth latents.
6/18/2024
🔎
Identifiable Causal Representation Learning: Unsupervised, Multi-View, and Multi-Environment
Julius von Kugelgen
0
0
Causal models provide rich descriptions of complex systems as sets of mechanisms by which each variable is influenced by its direct causes. They support reasoning about manipulating parts of the system and thus hold promise for addressing some of the open challenges of artificial intelligence (AI), such as planning, transferring knowledge in changing environments, or robustness to distribution shifts. However, a key obstacle to more widespread use of causal models in AI is the requirement that the relevant variables be specified a priori, which is typically not the case for the high-dimensional, unstructured data processed by modern AI systems. At the same time, machine learning (ML) has proven quite successful at automatically extracting useful and compact representations of such complex data. Causal representation learning (CRL) aims to combine the core strengths of ML and causality by learning representations in the form of latent variables endowed with causal model semantics. In this thesis, we study and present new results for different CRL settings. A central theme is the question of identifiability: Given infinite data, when are representations satisfying the same learning objective guaranteed to be equivalent? This is an important prerequisite for CRL, as it formally characterises if and when a learning task is, at least in principle, feasible. Since learning causal models, even without a representation learning component, is notoriously difficult, we require additional assumptions on the model class or rich data beyond the classical i.i.d. setting. By partially characterising identifiability for different settings, this thesis investigates what is possible for CRL without direct supervision, and thus contributes to its theoretical foundations. Ideally, the developed insights can help inform data collection practices or inspire the design of new practical estimation methods.
6/21/2024

Learning Discrete Concepts in Latent Hierarchical Models
Lingjing Kong, Guangyi Chen, Biwei Huang, Eric P. Xing, Yuejie Chi, Kun Zhang
0
0
Learning concepts from natural high-dimensional data (e.g., images) holds potential in building human-aligned and interpretable machine learning models. Despite its encouraging prospect, formalization and theoretical insights into this crucial task are still lacking. In this work, we formalize concepts as discrete latent causal variables that are related via a hierarchical causal model that encodes different abstraction levels of concepts embedded in high-dimensional data (e.g., a dog breed and its eye shapes in natural images). We formulate conditions to facilitate the identification of the proposed causal model, which reveals when learning such concepts from unsupervised data is possible. Our conditions permit complex causal hierarchical structures beyond latent trees and multi-level directed acyclic graphs in prior work and can handle high-dimensional, continuous observed variables, which is well-suited for unstructured data modalities such as images. We substantiate our theoretical claims with synthetic data experiments. Further, we discuss our theory's implications for understanding the underlying mechanisms of latent diffusion models and provide corresponding empirical evidence for our theoretical insights.
6/4/2024
🔎
Causal Representation Learning Made Identifiable by Grouping of Observational Variables
Hiroshi Morioka, Aapo Hyvarinen
0
0
A topic of great current interest is Causal Representation Learning (CRL), whose goal is to learn a causal model for hidden features in a data-driven manner. Unfortunately, CRL is severely ill-posed since it is a combination of the two notoriously ill-posed problems of representation learning and causal discovery. Yet, finding practical identifiability conditions that guarantee a unique solution is crucial for its practical applicability. Most approaches so far have been based on assumptions on the latent causal mechanisms, such as temporal causality, or existence of supervision or interventions; these can be too restrictive in actual applications. Here, we show identifiability based on novel, weak constraints, which requires no temporal structure, intervention, nor weak supervision. The approach is based on assuming the observational mixing exhibits a suitable grouping of the observational variables. We also propose a novel self-supervised estimation framework consistent with the model, prove its statistical consistency, and experimentally show its superior CRL performances compared to the state-of-the-art baselines. We further demonstrate its robustness against latent confounders and causal cycles.
6/10/2024