Generating Illustrated Instructions
2312.04552
0
0
⚙️
Abstract
We introduce the new task of generating Illustrated Instructions, i.e., visual instructions customized to a user's needs. We identify desiderata unique to this task, and formalize it through a suite of automatic and human evaluation metrics, designed to measure the validity, consistency, and efficacy of the generations. We combine the power of large language models (LLMs) together with strong text-to-image generation diffusion models to propose a simple approach called StackedDiffusion, which generates such illustrated instructions given text as input. The resulting model strongly outperforms baseline approaches and state-of-the-art multimodal LLMs; and in 30% of cases, users even prefer it to human-generated articles. Most notably, it enables various new and exciting applications far beyond what static articles on the web can provide, such as personalized instructions complete with intermediate steps and pictures in response to a user's individual situation.
Create account to get full access
Overview
- Introduces a new task of generating Illustrated Instructions - visual instructions customized to a user's needs
- Identifies unique desiderata for this task and formalizes it through a suite of evaluation metrics
- Proposes a simple approach called StackedDiffusion that combines large language models (LLMs) and text-to-image diffusion models to generate such illustrated instructions
- StackedDiffusion significantly outperforms baseline approaches and state-of-the-art multimodal LLMs, and in 30% of cases, users even prefer it to human-generated articles
- Enables new and exciting applications beyond static web articles, such as personalized instructions with intermediate steps and pictures tailored to a user's situation
Plain English Explanation
The paper introduces a new task of generating "Illustrated Instructions" - visual instructions that are customized to a user's specific needs. This is an exciting new area that goes beyond the standard static articles we see on the web today.
The researchers first identify important characteristics that make this task unique, and then develop a suite of evaluation metrics to measure how well the generated instructions perform in terms of validity, consistency, and effectiveness.
To tackle this task, the researchers combine the power of large language models (LLMs), which are great at understanding and generating text, with strong text-to-image diffusion models, which can create high-quality images from textual descriptions. They call their approach "StackedDiffusion."
The results show that StackedDiffusion significantly outperforms other baseline methods and even state-of-the-art multimodal LLMs. Remarkably, in 30% of cases, users actually preferred StackedDiffusion's generated instructions over instructions written by humans!
This new capability opens up all sorts of exciting applications. Instead of just getting a static set of instructions, users could now receive personalized, step-by-step guides complete with tailored illustrations to match their specific situation. This could be incredibly useful for all sorts of tasks, from assembling furniture to following a complex recipe.
Technical Explanation
The paper proposes the new task of "Illustrated Instructions" - generating visual instructions that are customized to a user's needs. To formalize this task, the researchers identify a set of desiderata, such as ensuring the generated instructions are valid, consistent, and effective at guiding the user.
They then develop a suite of automatic and human evaluation metrics to assess these properties of the generated instructions. This includes measures like semantic similarity between the text and images, coherence between consecutive steps, and user preferences compared to human-written instructions.
To tackle this task, the researchers introduce a simple yet powerful approach called StackedDiffusion. This combines the strengths of large language models (LLMs) and text-to-image diffusion models. The LLM generates the textual instructions, while the diffusion model translates this into corresponding illustrated steps.
Experiments show that StackedDiffusion significantly outperforms baseline methods as well as state-of-the-art multimodal LLMs on the proposed evaluation metrics. Remarkably, in 30% of cases, users even preferred StackedDiffusion's generated instructions over those written by humans.
This new capability goes beyond the static articles found on the web today. By combining language understanding, text generation, and image synthesis, StackedDiffusion can produce personalized, step-by-step guides with tailored illustrations to match a user's specific situation. This opens up a wide range of exciting new applications, from assembling furniture to following complex recipes.
Critical Analysis
The paper makes a compelling case for the new task of Illustrated Instructions and demonstrates the effectiveness of the StackedDiffusion approach. However, there are a few potential limitations and areas for further research worth considering.
First, the evaluation metrics, while comprehensive, may not fully capture all the nuances of what makes effective illustrated instructions. For example, the metrics don't directly assess factors like ease of comprehension or the quality of the explanations.
Additionally, while StackedDiffusion outperformed other methods, its performance was still not perfect. There may be room for improvement, particularly in ensuring the consistency and coherence of the generated instructions across multiple steps.
It would also be interesting to explore how StackedDiffusion's performance might vary across different domains or task types. The paper focuses on a relatively narrow set of use cases, so expanding the evaluation to a wider range of applications could yield additional insights.
Finally, the ethical implications of such a powerful text-to-image generation system should be carefully considered. While the paper focuses on beneficial applications, there is always the potential for misuse, such as the creation of misleading or deceptive content.
Overall, the paper introduces an exciting new research direction with significant real-world potential. By continuing to refine the approach and exploring its broader implications, the authors could make important contributions to the field of multimodal AI.
Conclusion
The paper presents a novel task of generating Illustrated Instructions - visual instructions tailored to a user's needs. The researchers develop a suite of evaluation metrics to assess the quality of these instructions and propose a simple yet effective approach called StackedDiffusion to tackle the task.
StackedDiffusion combines the strengths of large language models and text-to-image diffusion models, enabling it to significantly outperform baseline methods and even state-of-the-art multimodal LLMs. In some cases, users even preferred StackedDiffusion's generated instructions over those written by humans.
This new capability opens up a wide range of exciting applications that go beyond the static articles found on the web today. By producing personalized, step-by-step guides with tailored illustrations, StackedDiffusion could revolutionize how-to content and provide users with a more engaging and effective learning experience.
As the field of multimodal AI continues to advance, the insights and techniques presented in this paper could have far-reaching implications for a variety of domains, from education and training to consumer assistance and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
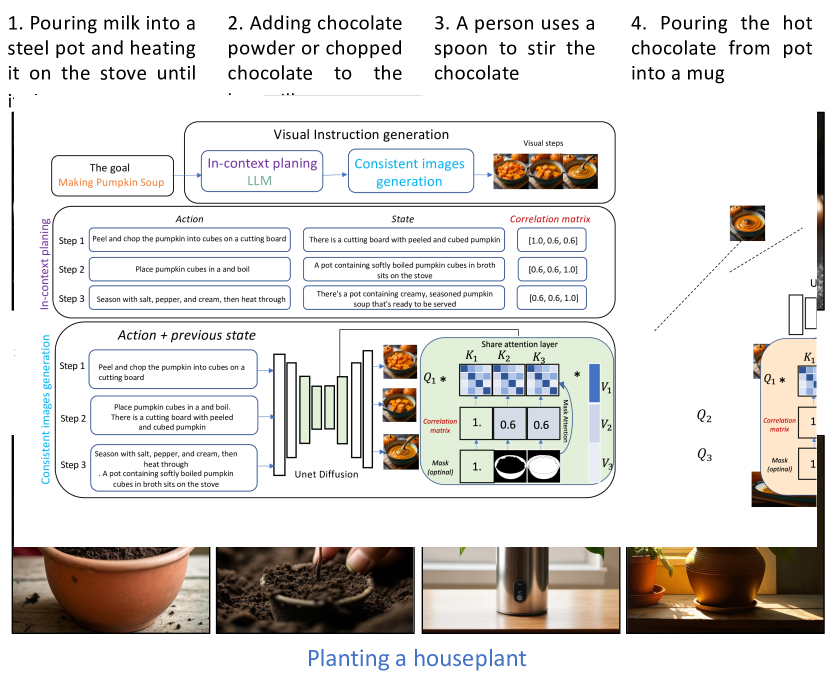
Coherent Zero-Shot Visual Instruction Generation
Quynh Phung, Songwei Ge, Jia-Bin Huang
0
0
Despite the advances in text-to-image synthesis, particularly with diffusion models, generating visual instructions that require consistent representation and smooth state transitions of objects across sequential steps remains a formidable challenge. This paper introduces a simple, training-free framework to tackle the issues, capitalizing on the advancements in diffusion models and large language models (LLMs). Our approach systematically integrates text comprehension and image generation to ensure visual instructions are visually appealing and maintain consistency and accuracy throughout the instruction sequence. We validate the effectiveness by testing multi-step instructions and comparing the text alignment and consistency with several baselines. Our experiments show that our approach can visualize coherent and visually pleasing instructions
6/11/2024
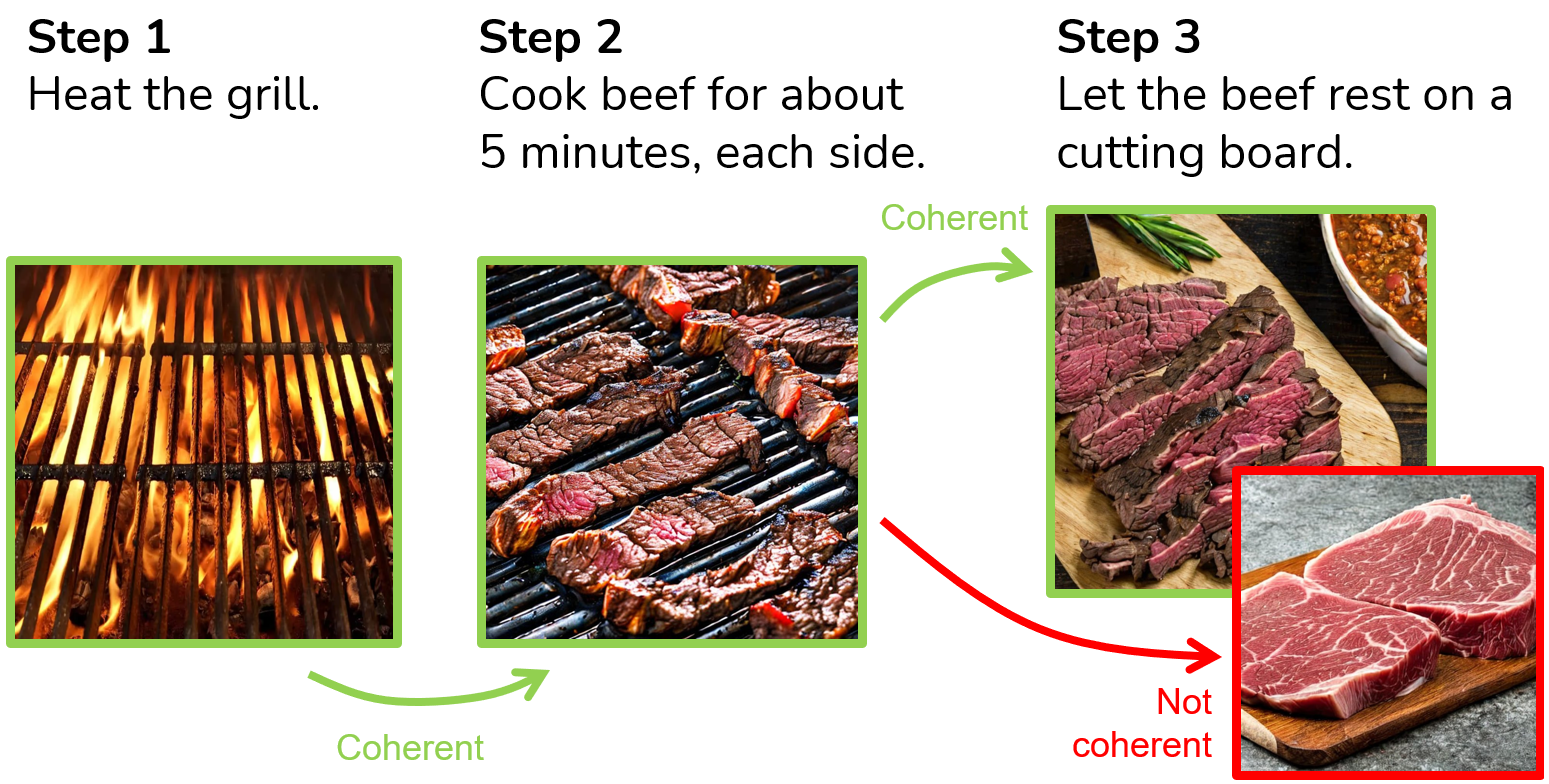
Generating Coherent Sequences of Visual Illustrations for Real-World Manual Tasks
Jo~ao Bordalo, Vasco Ramos, Rodrigo Val'erio, Diogo Gl'oria-Silva, Yonatan Bitton, Michal Yarom, Idan Szpektor, Joao Magalhaes
0
0
Multistep instructions, such as recipes and how-to guides, greatly benefit from visual aids, such as a series of images that accompany the instruction steps. While Large Language Models (LLMs) have become adept at generating coherent textual steps, Large Vision/Language Models (LVLMs) are less capable of generating accompanying image sequences. The most challenging aspect is that each generated image needs to adhere to the relevant textual step instruction, as well as be visually consistent with earlier images in the sequence. To address this problem, we propose an approach for generating consistent image sequences, which integrates a Latent Diffusion Model (LDM) with an LLM to transform the sequence into a caption to maintain the semantic coherence of the sequence. In addition, to maintain the visual coherence of the image sequence, we introduce a copy mechanism to initialise reverse diffusion processes with a latent vector iteration from a previously generated image from a relevant step. Both strategies will condition the reverse diffusion process on the sequence of instruction steps and tie the contents of the current image to previous instruction steps and corresponding images. Experiments show that the proposed approach is preferred by humans in 46.6% of the cases against 26.6% for the second best method. In addition, automatic metrics showed that the proposed method maintains semantic coherence and visual consistency across steps in both domains.
5/17/2024

Automatic Layout Planning for Visually-Rich Documents with Instruction-Following Models
Wanrong Zhu, Jennifer Healey, Ruiyi Zhang, William Yang Wang, Tong Sun
0
0
Recent advancements in instruction-following models have made user interactions with models more user-friendly and efficient, broadening their applicability. In graphic design, non-professional users often struggle to create visually appealing layouts due to limited skills and resources. In this work, we introduce a novel multimodal instruction-following framework for layout planning, allowing users to easily arrange visual elements into tailored layouts by specifying canvas size and design purpose, such as for book covers, posters, brochures, or menus. We developed three layout reasoning tasks to train the model in understanding and executing layout instructions. Experiments on two benchmarks show that our method not only simplifies the design process for non-professionals but also surpasses the performance of few-shot GPT-4V models, with mIoU higher by 12% on Crello. This progress highlights the potential of multimodal instruction-following models to automate and simplify the design process, providing an approachable solution for a wide range of design tasks on visually-rich documents.
4/24/2024
🌿
InstructVid2Vid: Controllable Video Editing with Natural Language Instructions
Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, Yueting Zhuang
0
0
We introduce InstructVid2Vid, an end-to-end diffusion-based methodology for video editing guided by human language instructions. Our approach empowers video manipulation guided by natural language directives, eliminating the need for per-example fine-tuning or inversion. The proposed InstructVid2Vid model modifies a pretrained image generation model, Stable Diffusion, to generate a time-dependent sequence of video frames. By harnessing the collective intelligence of disparate models, we engineer a training dataset rich in video-instruction triplets, which is a more cost-efficient alternative to collecting data in real-world scenarios. To enhance the coherence between successive frames within the generated videos, we propose the Inter-Frames Consistency Loss and incorporate it during the training process. With multimodal classifier-free guidance during the inference stage, the generated videos is able to resonate with both the input video and the accompanying instructions. Experimental results demonstrate that InstructVid2Vid is capable of generating high-quality, temporally coherent videos and performing diverse edits, including attribute editing, background changes, and style transfer. These results underscore the versatility and effectiveness of our proposed method.
5/30/2024