InstructVid2Vid: Controllable Video Editing with Natural Language Instructions
2305.12328
0
0
🌿
Abstract
We introduce InstructVid2Vid, an end-to-end diffusion-based methodology for video editing guided by human language instructions. Our approach empowers video manipulation guided by natural language directives, eliminating the need for per-example fine-tuning or inversion. The proposed InstructVid2Vid model modifies a pretrained image generation model, Stable Diffusion, to generate a time-dependent sequence of video frames. By harnessing the collective intelligence of disparate models, we engineer a training dataset rich in video-instruction triplets, which is a more cost-efficient alternative to collecting data in real-world scenarios. To enhance the coherence between successive frames within the generated videos, we propose the Inter-Frames Consistency Loss and incorporate it during the training process. With multimodal classifier-free guidance during the inference stage, the generated videos is able to resonate with both the input video and the accompanying instructions. Experimental results demonstrate that InstructVid2Vid is capable of generating high-quality, temporally coherent videos and performing diverse edits, including attribute editing, background changes, and style transfer. These results underscore the versatility and effectiveness of our proposed method.
Create account to get full access
Overview
- Introduces InstructVid2Vid, a new diffusion-based method for video editing guided by natural language instructions
- Modifies the Stable Diffusion image generation model to generate time-dependent video sequences
- Leverages diverse video-instruction datasets to enable video editing without per-example fine-tuning or inversion
- Proposes the Inter-Frames Consistency Loss to improve temporal coherence of generated videos
- Demonstrates ability to perform various video editing tasks, including attribute editing, background changes, and style transfer
Plain English Explanation
InstructVid2Vid is a new video editing tool that allows users to modify videos by simply typing in natural language instructions. Unlike previous approaches that required specialized training for each individual video, InstructVid2Vid can be applied more broadly without the need for per-example fine-tuning or inversion.
The key innovation is that the researchers took an existing image generation model, Stable Diffusion, and adapted it to work with videos. This allows the model to generate a sequence of video frames that match the user's instructions, such as "make the person in the video smile" or "change the background to a snowy winter scene."
To train the model, the researchers assembled a diverse dataset of video-instruction pairs, which is a more efficient approach than collecting real-world data for each possible editing task. They also introduced a new technique called the Inter-Frames Consistency Loss to help ensure the generated video frames flow smoothly and coherently from one to the next.
The result is a versatile video editing tool that can perform a wide range of manipulations, from adjusting attributes of objects or people in the video to completely changing the style or background. This technology could be particularly useful for content creators, video editors, and anyone who wants to quickly and easily modify their video footage without specialized skills or extensive training.
Technical Explanation
InstructVid2Vid is an end-to-end diffusion-based methodology for video editing that is guided by natural language instructions. The researchers start with a pre-trained image generation model, Stable Diffusion, and modify it to generate a time-dependent sequence of video frames.
To enable this video-to-video translation, the team leverages a training dataset of diverse video-instruction triplets, which is a more cost-efficient alternative to collecting real-world data for each specific video editing task. This dataset allows the model to learn the mapping between language instructions and corresponding video edits without the need for per-example fine-tuning or inversion.
To further enhance the temporal coherence of the generated videos, the researchers propose the Inter-Frames Consistency Loss. This loss function encourages the model to produce successive frames that are visually consistent, resulting in smoother and more cohesive video sequences.
During the inference stage, the InstructVid2Vid model utilizes multimodal classifier-free guidance to ensure the generated videos align with both the input video and the accompanying language instructions. This technique allows the model to perform a wide range of video editing tasks, including attribute editing, background changes, and style transfer, as demonstrated in the experimental results.
Critical Analysis
The researchers have made a compelling contribution with InstructVid2Vid, showcasing the potential of language-guided video editing. However, the paper does not address some important limitations and areas for further research.
One potential concern is the reliance on a pre-existing image generation model, Stable Diffusion, which may introduce biases or limitations inherent to that model. It would be interesting to see how the approach performs when using alternative image-to-image translation models as a starting point.
Additionally, the dataset used for training, while diverse, may not fully capture the breadth of possible video editing tasks and language instructions. Further research could explore ways to expand the dataset or develop more robust data generation techniques to improve the model's generalization capabilities.
The paper also lacks a detailed discussion of the computational and memory requirements of the InstructVid2Vid model, which could be a practical concern for real-world deployment, especially for resource-constrained devices or applications.
Despite these limitations, the research presented in this paper represents a significant step forward in the field of language-guided video editing. The results demonstrate the potential for models like InstructVid2Vid to empower users with diverse video manipulation capabilities, opening up new possibilities for content creation and video production.
Conclusion
InstructVid2Vid introduces a novel diffusion-based approach for video editing that is guided by natural language instructions. By modifying the pre-trained Stable Diffusion image generation model, the researchers have created a versatile tool that can perform a wide range of video editing tasks, including attribute editing, background changes, and style transfer.
The key innovations of InstructVid2Vid include the use of a diverse video-instruction dataset to enable video editing without per-example fine-tuning or inversion, and the introduction of the Inter-Frames Consistency Loss to improve the temporal coherence of the generated videos.
While the paper highlights the impressive capabilities of the proposed method, it also raises questions about the limitations and potential areas for further research, such as the reliance on a pre-existing model, the breadth of the training dataset, and the computational requirements of the approach.
Overall, the InstructVid2Vid research represents a significant advancement in the field of language-guided video editing, paving the way for more accessible and powerful video manipulation tools that could benefit content creators, video editors, and a wide range of other users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
Zhen Xing, Qi Dai, Zejia Weng, Zuxuan Wu, Yu-Gang Jiang
0
0
Text-guided video prediction (TVP) involves predicting the motion of future frames from the initial frame according to an instruction, which has wide applications in virtual reality, robotics, and content creation. Previous TVP methods make significant breakthroughs by adapting Stable Diffusion for this task. However, they struggle with frame consistency and temporal stability primarily due to the limited scale of video datasets. We observe that pretrained Image2Video diffusion models possess good priors for video dynamics but they lack textual control. Hence, transferring Image2Video models to leverage their video dynamic priors while injecting instruction control to generate controllable videos is both a meaningful and challenging task. To achieve this, we introduce the Multi-Modal Large Language Model (MLLM) to predict future video states based on initial frames and text instructions. More specifically, we design a dual query transformer (DQFormer) architecture, which integrates the instructions and frames into the conditional embeddings for future frame prediction. Additionally, we develop Long-Short Term Temporal Adapters and Spatial Adapters that can quickly transfer general video diffusion models to specific scenarios with minimal training costs. Experimental results show that our method significantly outperforms state-of-the-art techniques on four datasets: Something Something V2, Epic Kitchen-100, Bridge Data, and UCF-101. Notably, AID achieves 91.2% and 55.5% FVD improvements on Bridge and SSv2 respectively, demonstrating its effectiveness in various domains. More examples can be found at our website https://chenhsing.github.io/AID.
6/11/2024
🤿
InstructAny2Pix: Flexible Visual Editing via Multimodal Instruction Following
Shufan Li, Harkanwar Singh, Aditya Grover
0
0
The ability to provide fine-grained control for generating and editing visual imagery has profound implications for computer vision and its applications. Previous works have explored extending controllability in two directions: instruction tuning with text-based prompts and multi-modal conditioning. However, these works make one or more unnatural assumptions on the number and/or type of modality inputs used to express controllability. We propose InstructAny2Pix, a flexible multi-modal instruction-following system that enables users to edit an input image using instructions involving audio, images, and text. InstructAny2Pix consists of three building blocks that facilitate this capability: a multi-modal encoder that encodes different modalities such as images and audio into a unified latent space, a diffusion model that learns to decode representations in this latent space into images, and a multi-modal LLM that can understand instructions involving multiple images and audio pieces and generate a conditional embedding of the desired output, which can be used by the diffusion decoder. Additionally, to facilitate training efficiency and improve generation quality, we include an additional refinement prior module that enhances the visual quality of LLM outputs. These designs are critical to the performance of our system. We demonstrate that our system can perform a series of novel instruction-guided editing tasks. The code is available at https://github.com/jacklishufan/InstructAny2Pix.git
4/29/2024

I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
0
0
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
5/28/2024
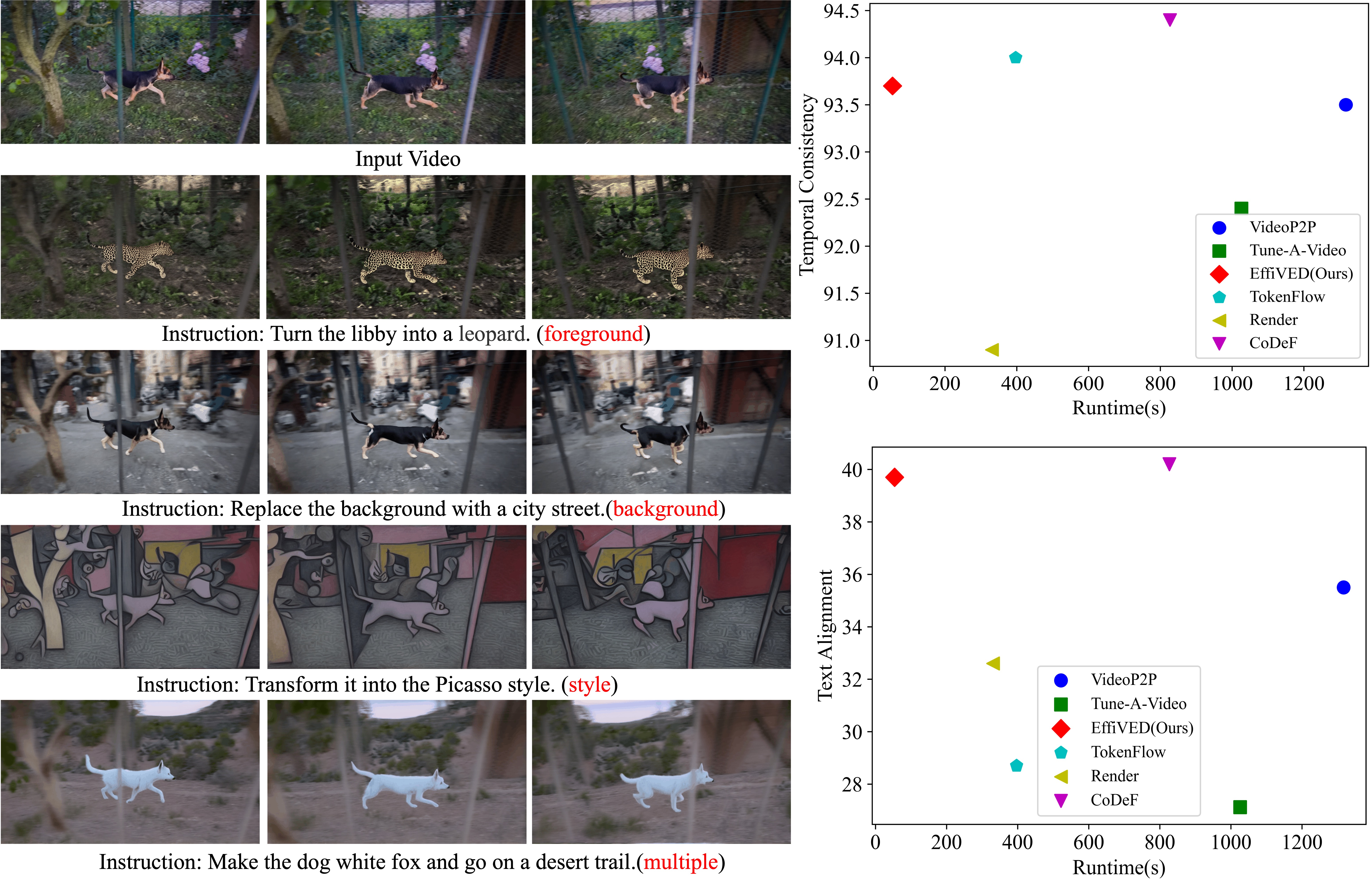
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Zhenghao Zhang, Zuozhuo Dai, Long Qin, Weizhi Wang
0
0
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. Code can be found at https://github.com/alibaba/EffiVED.
6/6/2024