Generating Unseen Code Tests In Infinitum

0

Sign in to get full access
Overview
- Generating Unseen Code Tests In Infinitum is a research paper that explores a novel approach to automatically generating code test cases.
- The key idea is to leverage abstract syntax trees (ASTs) to generate diverse and unseen test cases, which can help improve the testing and robustness of code.
- The paper presents the design and evaluation of their AST-based benchmark generation system, demonstrating its ability to generate a wide range of unseen tests.
Plain English Explanation
The paper introduces a system that can automatically create new test cases for code by analyzing the code's structure, rather than just its inputs and outputs. The researchers use a technique called abstract syntax trees (ASTs) to represent the code in a way that captures its underlying logic and structure.
By manipulating the AST, the system can generate a large number of new test cases that are quite different from the original ones used to train the system. This helps ensure that the code being tested is robust and can handle a wide range of scenarios, not just the ones it was explicitly trained for.
The key benefit of this approach is that it can create "unseen" test cases - tests that are fundamentally different from the ones used during development or training. This helps uncover potential bugs or edge cases that might have been missed otherwise.
Overall, this research presents a promising approach to improving the testing and reliability of code, which is an important concern as software becomes increasingly complex and ubiquitous in our lives.
Technical Explanation
The paper introduces an AST-based benchmark generation system that can automatically generate diverse and unseen test cases for code. The core idea is to leverage the abstract syntax tree (AST) representation of code to systematically explore the space of possible test cases.
The researchers first extract the AST of the code under test, which captures its underlying structure and logic. They then apply a series of AST transformations to generate new variants of the original AST, each representing a unique test case.
These transformations include operations like inserting, deleting, or modifying nodes in the AST, as well as rearranging the structure of the tree. By applying these transformations in a controlled and systematic way, the system can generate a large number of test cases that are fundamentally different from the original ones used during development.
The researchers evaluate their system on a range of benchmark tasks, demonstrating its ability to generate diverse and unseen test cases that are effective at uncovering bugs and improving the robustness of the code under test.
Critical Analysis
The paper presents a novel and promising approach to automatically generating diverse test cases for code. By leveraging the AST representation, the system can explore a much larger space of possible test cases than traditional approaches that focus only on the inputs and outputs.
However, the paper does not address the potential limitations of this approach. For example, the generated test cases may not be representative of real-world usage scenarios, or they may not be sufficient to uncover certain types of bugs. Additionally, the computational cost of generating and running a large number of test cases may be prohibitive in some contexts.
Furthermore, the paper does not discuss the potential biases or blind spots that may be inherent in the AST-based transformations used to generate the test cases. It's possible that certain types of code structures or logic may be underrepresented in the generated tests, leading to incomplete coverage.
Overall, the research presented in this paper is a significant contribution to the field of software testing and quality assurance. However, further research is needed to address the potential limitations and explore the broader implications of this approach.
Conclusion
The paper introduces a novel AST-based benchmark generation system that can automatically create diverse and unseen test cases for code. By leveraging the underlying structure of the code, represented as an abstract syntax tree, the system can systematically explore the space of possible test cases, generating a wide range of scenarios that are fundamentally different from the original ones.
The researchers demonstrate the effectiveness of their approach through extensive evaluation, showing that the generated test cases are effective at uncovering bugs and improving the robustness of the code under test. This work represents an important step forward in the field of software testing, paving the way for more reliable and comprehensive assessment of code quality.
As software systems become increasingly complex and ubiquitous in our lives, the need for robust and comprehensive testing is more important than ever. The techniques presented in this paper offer a promising avenue for addressing this challenge, and further research in this area could have significant implications for the future of software development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generating Unseen Code Tests In Infinitum
Marcel Zalmanovici, Orna Raz, Eitan Farchi, Iftach Freund
Large Language Models (LLMs) are used for many tasks, including those related to coding. An important aspect of being able to utilize LLMs is the ability to assess their fitness for specific usages. The common practice is to evaluate LLMs against a set of benchmarks. While benchmarks provide a sound foundation for evaluation and comparison of alternatives, they suffer from the well-known weakness of leaking into the training data cite{Xu2024Benchmarking}. We present a method for creating benchmark variations that generalize across coding tasks and programming languages, and may also be applied to in-house code bases. Our approach enables ongoing generation of test-data thus mitigating the leaking into the training data issue. We implement one benchmark, called textit{auto-regression}, for the task of text-to-code generation in Python. Auto-regression is specifically created to aid in debugging and in tracking model generation changes as part of the LLM regression testing process.
Read more7/30/2024

0
A System for Automated Unit Test Generation Using Large Language Models and Assessment of Generated Test Suites
Andrea Lops, Fedelucio Narducci, Azzurra Ragone, Michelantonio Trizio, Claudio Bartolini
Unit tests represent the most basic level of testing within the software testing lifecycle and are crucial to ensuring software correctness. Designing and creating unit tests is a costly and labor-intensive process that is ripe for automation. Recently, Large Language Models (LLMs) have been applied to various aspects of software development, including unit test generation. Although several empirical studies evaluating LLMs' capabilities in test code generation exist, they primarily focus on simple scenarios, such as the straightforward generation of unit tests for individual methods. These evaluations often involve independent and small-scale test units, providing a limited view of LLMs' performance in real-world software development scenarios. Moreover, previous studies do not approach the problem at a suitable scale for real-life applications. Generated unit tests are often evaluated via manual integration into the original projects, a process that limits the number of tests executed and reduces overall efficiency. To address these gaps, we have developed an approach for generating and evaluating more real-life complexity test suites. Our approach focuses on class-level test code generation and automates the entire process from test generation to test assessment. In this work, we present AgoneTest: an automated system for generating test suites for Java projects and a comprehensive and principled methodology for evaluating the generated test suites. Starting from a state-of-the-art dataset (i.e., Methods2Test), we built a new dataset for comparing human-written tests with those generated by LLMs. Our key contributions include a scalable automated software system, a new dataset, and a detailed methodology for evaluating test quality.
Read more8/19/2024
🎲
0
Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review
Debalina Ghosh Paul, Hong Zhu, Ian Bayley
With the rapid development of Large Language Models (LLMs), a large number of machine learning models have been developed to assist programming tasks including the generation of program code from natural language input. However, how to evaluate such LLMs for this task is still an open problem despite of the great amount of research efforts that have been made and reported to evaluate and compare them. This paper provides a critical review of the existing work on the testing and evaluation of these tools with a focus on two key aspects: the benchmarks and the metrics used in the evaluations. Based on the review, further research directions are discussed.
Read more6/19/2024
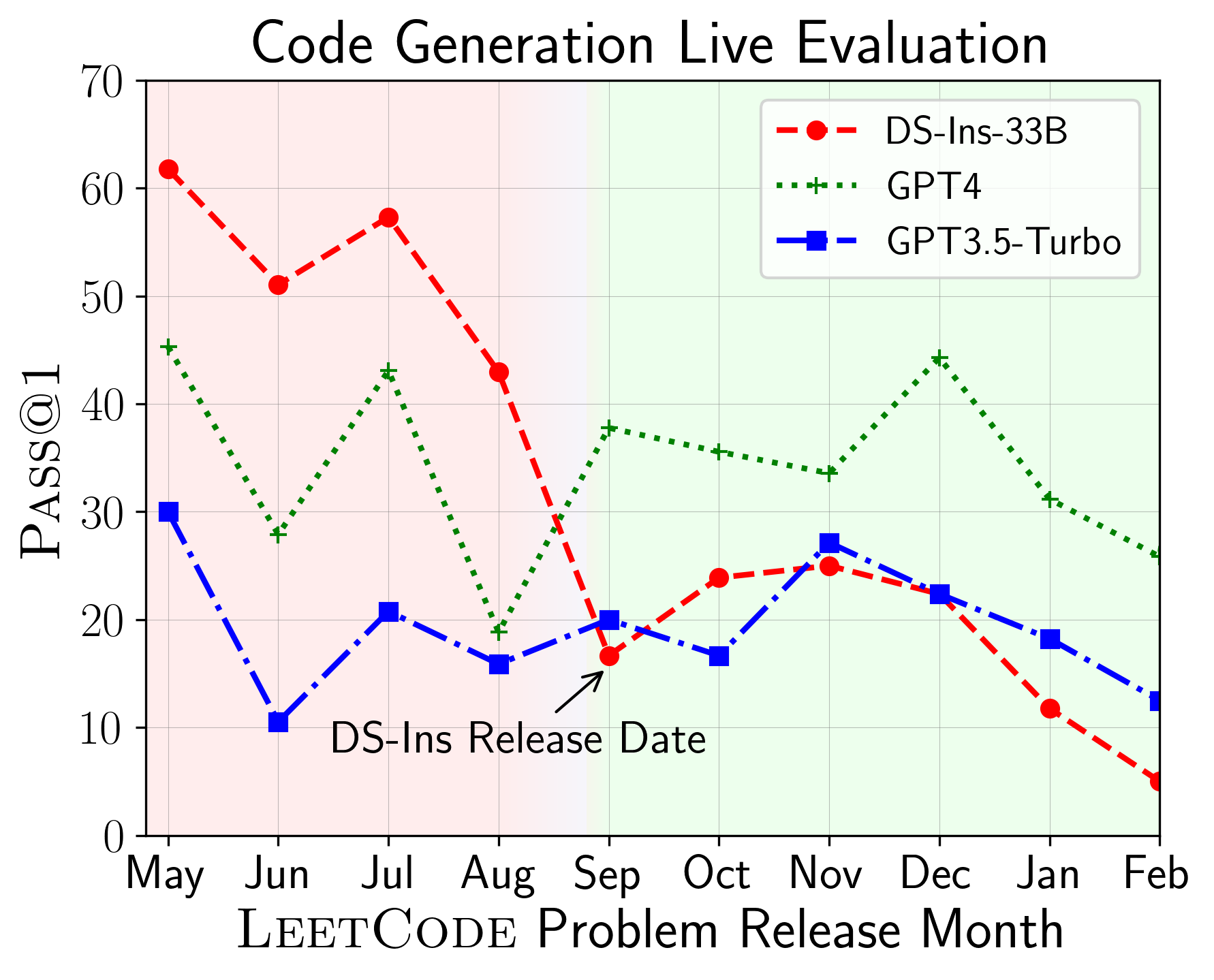
1
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica
Large Language Models (LLMs) applied to code-related applications have emerged as a prominent field, attracting significant interest from both academia and industry. However, as new and improved LLMs are developed, existing evaluation benchmarks (e.g., HumanEval, MBPP) are no longer sufficient for assessing their capabilities. In this work, we propose LiveCodeBench, a comprehensive and contamination-free evaluation of LLMs for code, which continuously collects new problems over time from contests across three competition platforms, namely LeetCode, AtCoder, and CodeForces. Notably, our benchmark also focuses on a broader range of code related capabilities, such as self-repair, code execution, and test output prediction, beyond just code generation. Currently, LiveCodeBench hosts four hundred high-quality coding problems that were published between May 2023 and May 2024. We have evaluated 18 base LLMs and 34 instruction-tuned LLMs on LiveCodeBench. We present empirical findings on contamination, holistic performance comparisons, potential overfitting in existing benchmarks as well as individual model comparisons. We will release all prompts and model completions for further community analysis, along with a general toolkit for adding new scenarios and model
Read more6/7/2024