Generative AI-Based Text Generation Methods Using Pre-Trained GPT-2 Model
2404.01786
0
0
🛸
Abstract
This work delved into the realm of automatic text generation, exploring a variety of techniques ranging from traditional deterministic approaches to more modern stochastic methods. Through analysis of greedy search, beam search, top-k sampling, top-p sampling, contrastive searching, and locally typical searching, this work has provided valuable insights into the strengths, weaknesses, and potential applications of each method. Each text-generating method is evaluated using several standard metrics and a comparative study has been made on the performance of the approaches. Finally, some future directions of research in the field of automatic text generation are also identified.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores various techniques for automatically generating text, including traditional deterministic approaches and modern stochastic methods.
- The researchers analyzed the strengths, weaknesses, and potential applications of different text generation methods, such as greedy search, beam search, top-k sampling, top-p sampling, contrastive searching, and locally typical searching.
- The performance of these approaches was evaluated using standard metrics, and the findings provide valuable insights for the field of automatic text generation.
- The paper also identifies future research directions in this area.
Plain English Explanation
Generating human-like text automatically is a complex challenge that researchers have been working on for years. This paper looks at a variety of techniques that can be used to create text without human input. Some of the approaches are more structured and predictable, while others take a more probabilistic approach.
The researchers tested out different text generation methods to see how well they perform. They looked at things like how coherent and diverse the generated text was, as well as how closely it matched human-written text. By comparing the strengths and weaknesses of each technique, the paper provides a useful guide for when and how to apply these text generation tools.
For example, some methods are good at producing consistent, on-topic text, while others can generate more varied and creative content. The researchers also identified areas where further improvements could be made to make the text generation even more natural and useful.
Overall, this work contributes to our understanding of the current state of automatic text generation and points the way toward future advancements in this rapidly evolving field.
Technical Explanation
The paper examines several text generation techniques, including:
- Greedy search: A deterministic approach that selects the most probable word at each step.
- Beam search: An extension of greedy search that considers multiple potential word sequences in parallel.
- Top-k sampling: A stochastic method that randomly samples from the k most probable words.
- Top-p sampling (nucleus sampling): A variation of top-k that samples from the smallest possible set of words that account for a specified probability mass.
- Contrastive search: An approach that encourages the generated text to be different from a given reference text.
- Locally typical search: A technique that aims to produce text that is "locally typical" rather than simply the most probable.
The researchers evaluated these methods using standard metrics like perplexity, BLEU score, and distinct n-grams, comparing their performance on text generation tasks. The analysis provided insights into the trade-offs between qualities like coherence, diversity, and fidelity to human-written text.
Critical Analysis
The paper provides a thorough and objective comparison of various text generation techniques, highlighting the strengths and weaknesses of each approach. However, it is important to note that the evaluation was conducted on a limited set of datasets and tasks. The performance of these methods may vary depending on the specific application and domain.
Additionally, the paper does not delve deeply into the ethical implications of automatic text generation. As these technologies become more advanced, there are concerns about their potential misuse, such as generating misinformation or impersonating real people. Future research should consider the societal impact and responsible development of text generation systems.
Another area for further exploration is the integration of these text generation techniques with other AI capabilities, such as language understanding and reasoning. Combining text generation with other natural language processing tasks could lead to more robust and versatile systems.
Conclusion
This paper provides a valuable contribution to the field of automatic text generation by systematically evaluating a range of techniques and offering insights into their strengths and weaknesses. The findings can inform the development of more advanced text generation systems, which have numerous potential applications in areas like content creation, language learning, and assistive technologies.
As the field continues to evolve, it will be important to address the ethical considerations and explore ways to integrate text generation with other AI capabilities to create more sophisticated and responsible language models. This research lays the groundwork for future advancements in this rapidly changing and impactful domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Text Summaries Generated by Large Language Models Using OpenAI's GPT
Hassan Shakil, Atqiya Munawara Mahi, Phuoc Nguyen, Zeydy Ortiz, Mamoun T. Mardini
0
0
This research examines the effectiveness of OpenAI's GPT models as independent evaluators of text summaries generated by six transformer-based models from Hugging Face: DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS. We evaluated these summaries based on essential properties of high-quality summary - conciseness, relevance, coherence, and readability - using traditional metrics such as ROUGE and Latent Semantic Analysis (LSA). Uniquely, we also employed GPT not as a summarizer but as an evaluator, allowing it to independently assess summary quality without predefined metrics. Our analysis revealed significant correlations between GPT evaluations and traditional metrics, particularly in assessing relevance and coherence. The results demonstrate GPT's potential as a robust tool for evaluating text summaries, offering insights that complement established metrics and providing a basis for comparative analysis of transformer-based models in natural language processing tasks.
5/8/2024
🤖
Automated Multi-Language to English Machine Translation Using Generative Pre-Trained Transformers
Elijah Pelofske, Vincent Urias, Lorie M. Liebrock
0
0
The task of accurate and efficient language translation is an extremely important information processing task. Machine learning enabled and automated translation that is accurate and fast is often a large topic of interest in the machine learning and data science communities. In this study, we examine using local Generative Pretrained Transformer (GPT) models to perform automated zero shot black-box, sentence wise, multi-natural-language translation into English text. We benchmark 16 different open-source GPT models, with no custom fine-tuning, from the Huggingface LLM repository for translating 50 different non-English languages into English using translated TED Talk transcripts as the reference dataset. These GPT model inference calls are performed strictly locally, on single A100 Nvidia GPUs. Benchmark metrics that are reported are language translation accuracy, using BLEU, GLEU, METEOR, and chrF text overlap measures, and wall-clock time for each sentence translation. The best overall performing GPT model for translating into English text for the BLEU metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.152$, for the GLEU metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.256$, for the chrF metric is Llama2-chat-AYT-13B with a mean score across all tested languages of $0.448$, and for the METEOR metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.438$.
4/24/2024
📊
Beyond Generating Code: Evaluating GPT on a Data Visualization Course
Chen Zhu-Tian, Chenyang Zhang, Qianwen Wang, Jakob Troidl, Simon Warchol, Johanna Beyer, Nils Gehlenborg, Hanspeter Pfister
0
0
This paper presents an empirical evaluation of the performance of the Generative Pre-trained Transformer (GPT) model in Harvard's CS171 data visualization course. While previous studies have focused on GPT's ability to generate code for visualizations, this study goes beyond code generation to evaluate GPT's abilities in various visualization tasks, such as data interpretation, visualization design, visual data exploration, and insight communication. The evaluation utilized GPT-3.5 and GPT-4 to complete assignments of CS171, and included a quantitative assessment based on the established course rubrics, a qualitative analysis informed by the feedback of three experienced graders, and an exploratory study of GPT's capabilities in completing border visualization tasks. Findings show that GPT-4 scored 80% on quizzes and homework, and TFs could distinguish between GPT- and human-generated homework with 70% accuracy. The study also demonstrates GPT's potential in completing various visualization tasks, such as data cleanup, interaction with visualizations, and insight communication. The paper concludes by discussing the strengths and limitations of GPT in data visualization, potential avenues for incorporating GPT in broader visualization tasks, and the need to redesign visualization education.
5/14/2024
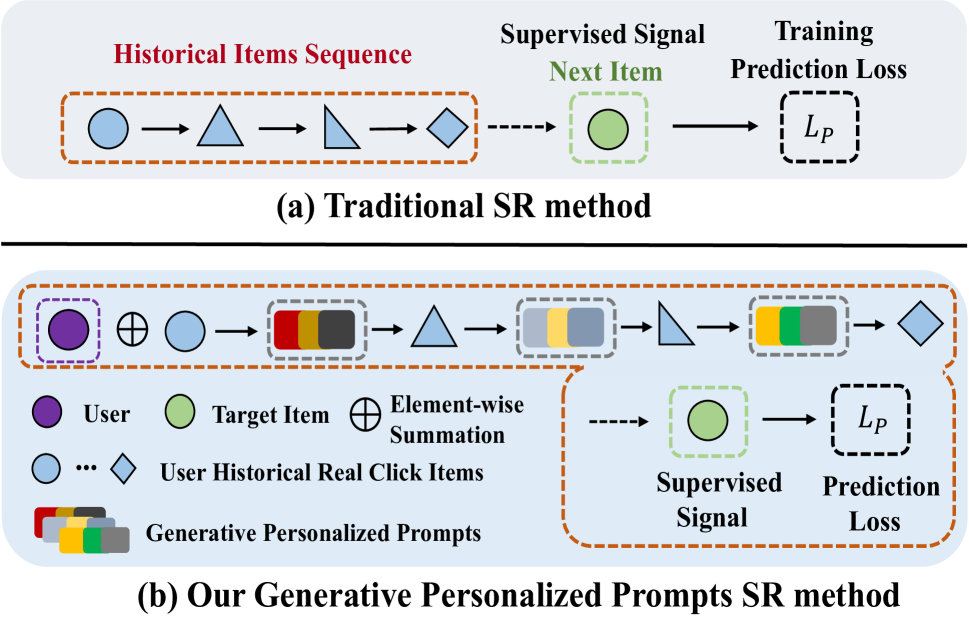
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Yabin Zhang, Wenhui Yu, Erhan Zhang, Xu Chen, Lantao Hu, Peng Jiang, Kun Gai
0
0
ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
4/16/2024