GenHowTo: Learning to Generate Actions and State Transformations from Instructional Videos

0
Sign in to get full access
Overview
- This paper presents "GenHowTo", a system that learns to generate actions and state transformations from instructional videos.
- The goal is to enable robots and other AI systems to learn how to perform tasks by observing human demonstrations in videos.
- The approach involves using deep learning models to extract visual and language information from the videos and learn the underlying task structure.
Plain English Explanation
The research team wanted to develop a way for robots and AI systems to learn how to perform tasks by watching instructional videos, similar to how humans learn. Traditionally, it has been challenging for machines to understand the steps and sequences involved in completing tasks just from observing videos.
The researchers created a system called "GenHowTo" that can analyze instructional videos and extract the key actions and changes in the environment that occur during the task. By learning from many different video demonstrations, the system builds an understanding of the general steps and state transformations required to complete the task.
This allows the system to then generate its own plans for how to perform the task, including the specific actions it needs to take and how the environment should change as a result. The goal is for robots and other AI agents to be able to leverage this learned knowledge to effectively carry out tasks in the real world after observing human demonstrations.
Technical Explanation
The GenHowTo system uses a multi-modal deep learning approach to extract information from instructional videos. It takes in the video frames and associated narration or subtitles, and learns to map this input to a structured representation of the task.
This representation includes the sequence of actions performed, as well as the changes in the state of the environment that occur at each step. The model is trained on a large dataset of instructional videos covering a variety of tasks.
During inference, the system can take a new video as input and generate the corresponding sequence of actions and state transformations needed to complete the task. This allows it to produce step-by-step plans that can be executed by a robot or agent.
The key technical innovations include novel neural network architectures for fusing the visual and language inputs, as well as training approaches that can handle the complexity and variability of real-world instructional videos.
Critical Analysis
The paper provides a compelling approach for enabling AI systems to learn task-completion skills from observational data. However, a key limitation is that the system is still constrained by the specific tasks and environments present in the training data.
Extrapolating the learned knowledge to novel, unseen tasks or settings may be challenging. Additionally, the paper does not provide extensive real-world evaluation, so the practical deployment of the system remains an open question.
Further research is needed to enhance the generalization capabilities of the models, as well as to ensure the safety and robustness of the generated plans when executed in the physical world. Integrating the task learning with other key AI capabilities, such as common sense reasoning and physical world understanding, could also be an important direction.
Conclusion
Overall, the GenHowTo system represents an exciting step towards enabling AI agents to learn complex skills by observing human demonstrations, much like how humans learn. The core technical innovations around multi-modal learning and structured task representation are promising and could have significant implications for a variety of real-world applications.
However, significant challenges remain in scaling this approach to truly general and robust task learning. Continued research in this area has the potential to unlock new frontiers in robotics, automation, and AI-powered assistants that can fluidly adapt to diverse tasks and environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GenHowTo: Learning to Generate Actions and State Transformations from Instructional Videos
Tom'av{s} Souv{c}ek, Dima Damen, Michael Wray, Ivan Laptev, Josef Sivic
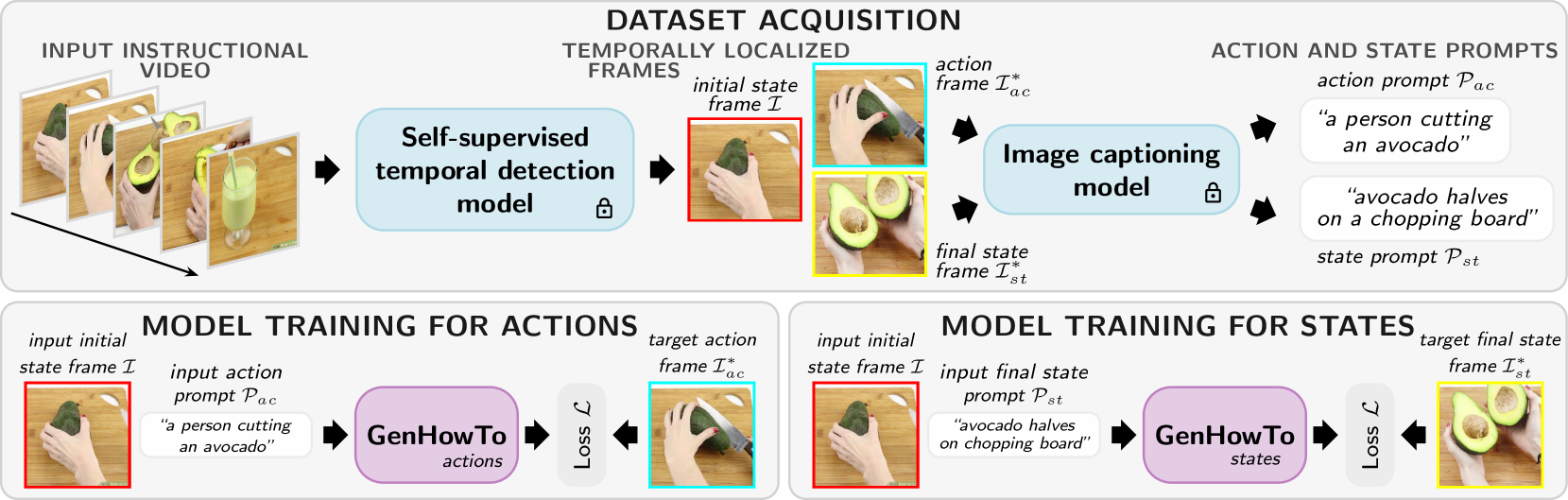
We address the task of generating temporally consistent and physically plausible images of actions and object state transformations. Given an input image and a text prompt describing the targeted transformation, our generated images preserve the environment and transform objects in the initial image. Our contributions are threefold. First, we leverage a large body of instructional videos and automatically mine a dataset of triplets of consecutive frames corresponding to initial object states, actions, and resulting object transformations. Second, equipped with this data, we develop and train a conditioned diffusion model dubbed GenHowTo. Third, we evaluate GenHowTo on a variety of objects and actions and show superior performance compared to existing methods. In particular, we introduce a quantitative evaluation where GenHowTo achieves 88% and 74% on seen and unseen interaction categories, respectively, outperforming prior work by a large margin.
Read more4/3/2024

0
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doersch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, Sean Kirmani
How can robot manipulation policies generalize to novel tasks involving unseen object types and new motions? In this paper, we provide a solution in terms of predicting motion information from web data through human video generation and conditioning a robot policy on the generated video. Instead of attempting to scale robot data collection which is expensive, we show how we can leverage video generation models trained on easily available web data, for enabling generalization. Our approach Gen2Act casts language-conditioned manipulation as zero-shot human video generation followed by execution with a single policy conditioned on the generated video. To train the policy, we use an order of magnitude less robot interaction data compared to what the video prediction model was trained on. Gen2Act doesn't require fine-tuning the video model at all and we directly use a pre-trained model for generating human videos. Our results on diverse real-world scenarios show how Gen2Act enables manipulating unseen object types and performing novel motions for tasks not present in the robot data. Videos are at https://homangab.github.io/gen2act/
Read more9/25/2024

0
Controlling the World by Sleight of Hand
Sruthi Sudhakar, Ruoshi Liu, Basile Van Hoorick, Carl Vondrick, Richard Zemel
Humans naturally build mental models of object interactions and dynamics, allowing them to imagine how their surroundings will change if they take a certain action. While generative models today have shown impressive results on generating/editing images unconditionally or conditioned on text, current methods do not provide the ability to perform object manipulation conditioned on actions, an important tool for world modeling and action planning. Therefore, we propose to learn an action-conditional generative models by learning from unlabeled videos of human hands interacting with objects. The vast quantity of such data on the internet allows for efficient scaling which can enable high-performing action-conditional models. Given an image, and the shape/location of a desired hand interaction, CosHand, synthesizes an image of a future after the interaction has occurred. Experiments show that the resulting model can predict the effects of hand-object interactions well, with strong generalization particularly to translation, stretching, and squeezing interactions of unseen objects in unseen environments. Further, CosHand can be sampled many times to predict multiple possible effects, modeling the uncertainty of forces in the interaction/environment. Finally, method generalizes to different embodiments, including non-human hands, i.e. robot hands, suggesting that generative video models can be powerful models for robotics.
Read more8/15/2024
0
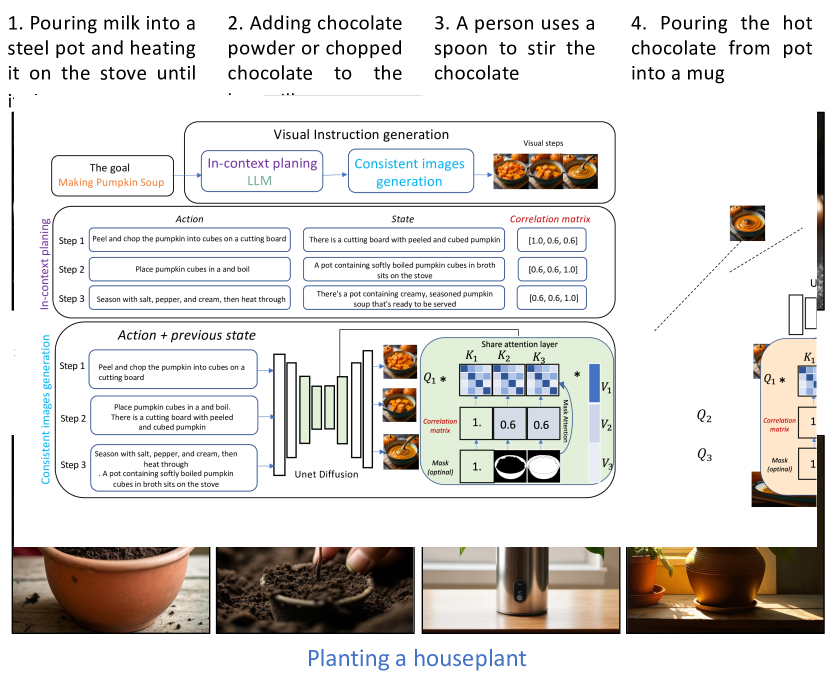
Coherent Zero-Shot Visual Instruction Generation
Quynh Phung, Songwei Ge, Jia-Bin Huang
Despite the advances in text-to-image synthesis, particularly with diffusion models, generating visual instructions that require consistent representation and smooth state transitions of objects across sequential steps remains a formidable challenge. This paper introduces a simple, training-free framework to tackle the issues, capitalizing on the advancements in diffusion models and large language models (LLMs). Our approach systematically integrates text comprehension and image generation to ensure visual instructions are visually appealing and maintain consistency and accuracy throughout the instruction sequence. We validate the effectiveness by testing multi-step instructions and comparing the text alignment and consistency with several baselines. Our experiments show that our approach can visualize coherent and visually pleasing instructions
Read more6/11/2024