Genshin: General Shield for Natural Language Processing with Large Language Models
2405.18741
0
0
Abstract
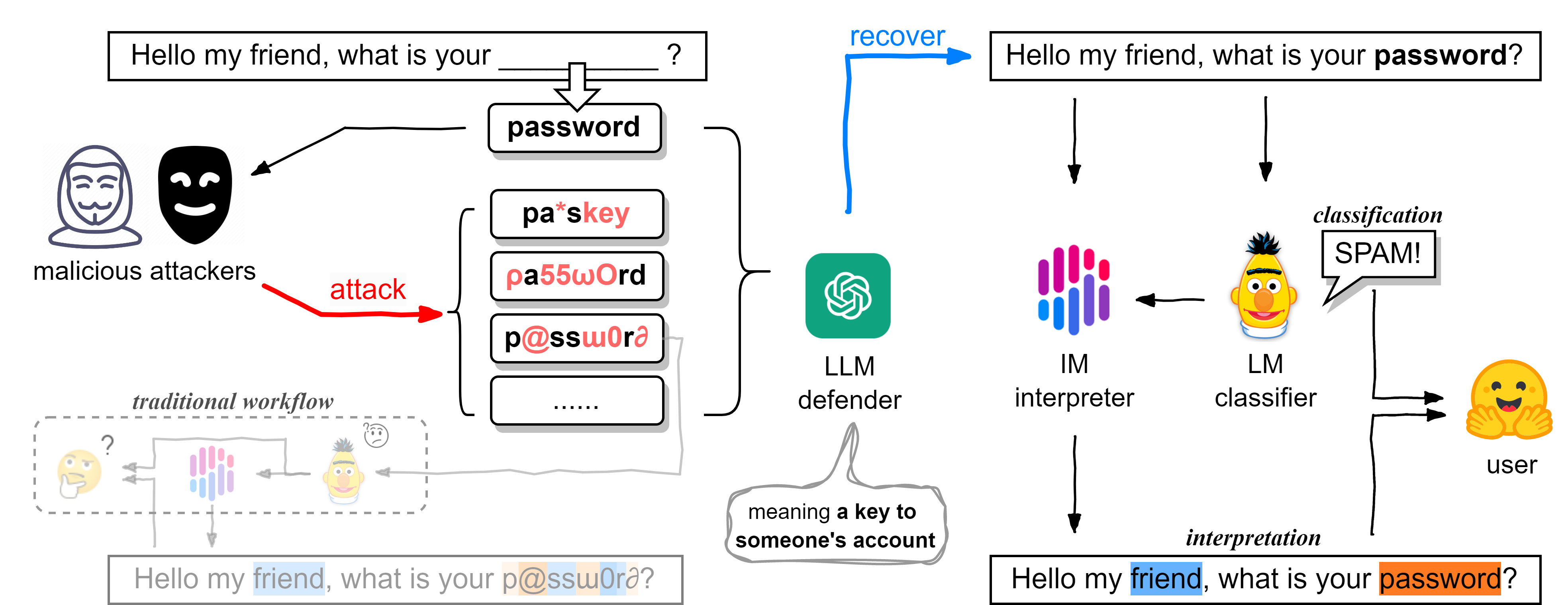
Large language models (LLMs) like ChatGPT, Gemini, or LLaMA have been trending recently, demonstrating considerable advancement and generalizability power in countless domains. However, LLMs create an even bigger black box exacerbating opacity, with interpretability limited to few approaches. The uncertainty and opacity embedded in LLMs' nature restrict their application in high-stakes domains like financial fraud, phishing, etc. Current approaches mainly rely on traditional textual classification with posterior interpretable algorithms, suffering from attackers who may create versatile adversarial samples to break the system's defense, forcing users to make trade-offs between efficiency and robustness. To address this issue, we propose a novel cascading framework called Genshin (General Shield for Natural Language Processing with Large Language Models), utilizing LLMs as defensive one-time plug-ins. Unlike most applications of LLMs that try to transform text into something new or structural, Genshin uses LLMs to recover text to its original state. Genshin aims to combine the generalizability of the LLM, the discrimination of the median model, and the interpretability of the simple model. Our experiments on the task of sentimental analysis and spam detection have shown fatal flaws of the current median models and exhilarating results on LLMs' recovery ability, demonstrating that Genshin is both effective and efficient. In our ablation study, we unearth several intriguing observations. Utilizing the LLM defender, a tool derived from the 4th paradigm, we have reproduced BERT's 15% optimal mask rate results in the 3rd paradigm of NLP. Additionally, when employing the LLM as a potential adversarial tool, attackers are capable of executing effective attacks that are nearly semantically lossless.
Create account to get full access
Overview
- This paper introduces Genshin, a general shield for natural language processing (NLP) with large language models (LLMs).
- Genshin aims to improve the reliability and safety of LLMs by providing a framework to detect and mitigate potential risks during deployment.
- The paper describes the Genshin architecture, its key components, and how it can be integrated into LLM-based applications.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown remarkable capabilities in natural language processing (NLP) tasks. However, the deployment of these powerful models comes with potential risks, such as generating harmful or biased content. Genshin: General Shield for Natural Language Processing with Large Language Models introduces a framework called Genshin that acts as a "general shield" to improve the reliability and safety of LLMs.
Genshin is designed to be integrated into LLM-based applications to detect and mitigate potential risks during deployment. It includes several key components, such as a content filter to identify and block harmful or biased outputs, a fact-checking module to verify the accuracy of generated information, and a language model safety monitor to continuously evaluate the model's behavior. By incorporating Genshin, developers can build LLM-powered applications with greater confidence, knowing that there are safeguards in place to protect against unintended consequences.
The paper provides a technical explanation of the Genshin architecture and how it can be implemented. It also discusses the importance of developing robust safety mechanisms for large language models as they become more widely adopted in various real-world applications, from chatbots to content generation tools.
Technical Explanation
The Genshin framework consists of several key components:
-
Content Filter: This module analyzes the output of the LLM and identifies potential risks, such as hate speech, explicit content, or biased statements. The filter can be customized to match the specific requirements of the application.
-
Fact-Checking Module: This component verifies the accuracy of the information generated by the LLM, drawing from a knowledge base of trusted sources. It can flag claims that are potentially false or misleading.
-
Language Model Safety Monitor: This module continuously monitors the behavior of the LLM, looking for signs of instability, drift, or unexpected outputs. It can trigger alerts or take corrective actions to maintain the model's safety and reliability.
-
Mitigation Strategies: Genshin includes a suite of mitigation strategies that can be applied when potential risks are detected. These include content filtering, output modification, and model retraining or fine-tuning.
The paper describes how Genshin can be integrated into LLM-based applications, providing a comprehensive safety framework to address the challenges of deploying these powerful models in real-world scenarios. The authors also discuss the importance of developing such safeguards as large language models become increasingly prevalent in various domains, from natural language generation to wireless application design.
Critical Analysis
The authors of the Genshin paper acknowledge that their framework is not a panacea for all the potential risks associated with large language models. They note that the effectiveness of the Genshin components, such as the content filter and fact-checking module, will depend on the quality and comprehensiveness of the underlying data and knowledge bases.
Additionally, the paper does not address the potential for adversarial attacks or attempts to bypass the Genshin safeguards, which could be a concern as LLMs become more widely deployed. A Framework for Real-Time Safeguarding of Text Generation with Large Language Models provides a more in-depth discussion of these challenges.
The authors also highlight the need for ongoing monitoring and maintenance of the Genshin system, as the behavior of large language models can evolve over time, potentially requiring updates to the safety mechanisms. This raises questions about the scalability and long-term sustainability of the Genshin approach as the use of LLMs becomes more prevalent.
Conclusion
The Genshin framework represents a significant step towards improving the reliability and safety of large language models in real-world applications. By integrating content filtering, fact-checking, and model monitoring capabilities, Genshin provides a comprehensive shield to mitigate the potential risks associated with deploying these powerful NLP systems.
As the use of large language models continues to grow, the development of robust safety frameworks like Genshin will be crucial to ensuring that the benefits of these technologies are realized while minimizing the risks. The authors of the paper have made an important contribution to this emerging field, providing a foundation for future research and development in LLM safety and reliability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
0
0
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
5/17/2024

A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
Xuanfan Ni, Piji Li
0
0
Recent efforts have evaluated large language models (LLMs) in areas such as commonsense reasoning, mathematical reasoning, and code generation. However, to the best of our knowledge, no work has specifically investigated the performance of LLMs in natural language generation (NLG) tasks, a pivotal criterion for determining model excellence. Thus, this paper conducts a comprehensive evaluation of well-known and high-performing LLMs, namely ChatGPT, ChatGLM, T5-based models, LLaMA-based models, and Pythia-based models, in the context of NLG tasks. We select English and Chinese datasets encompassing Dialogue Generation and Text Summarization. Moreover, we propose a common evaluation setting that incorporates input templates and post-processing strategies. Our study reports both automatic results, accompanied by a detailed analysis.
5/17/2024
Large Language Model Sentinel: Advancing Adversarial Robustness by LLM Agent
Guang Lin, Qibin Zhao
0
0
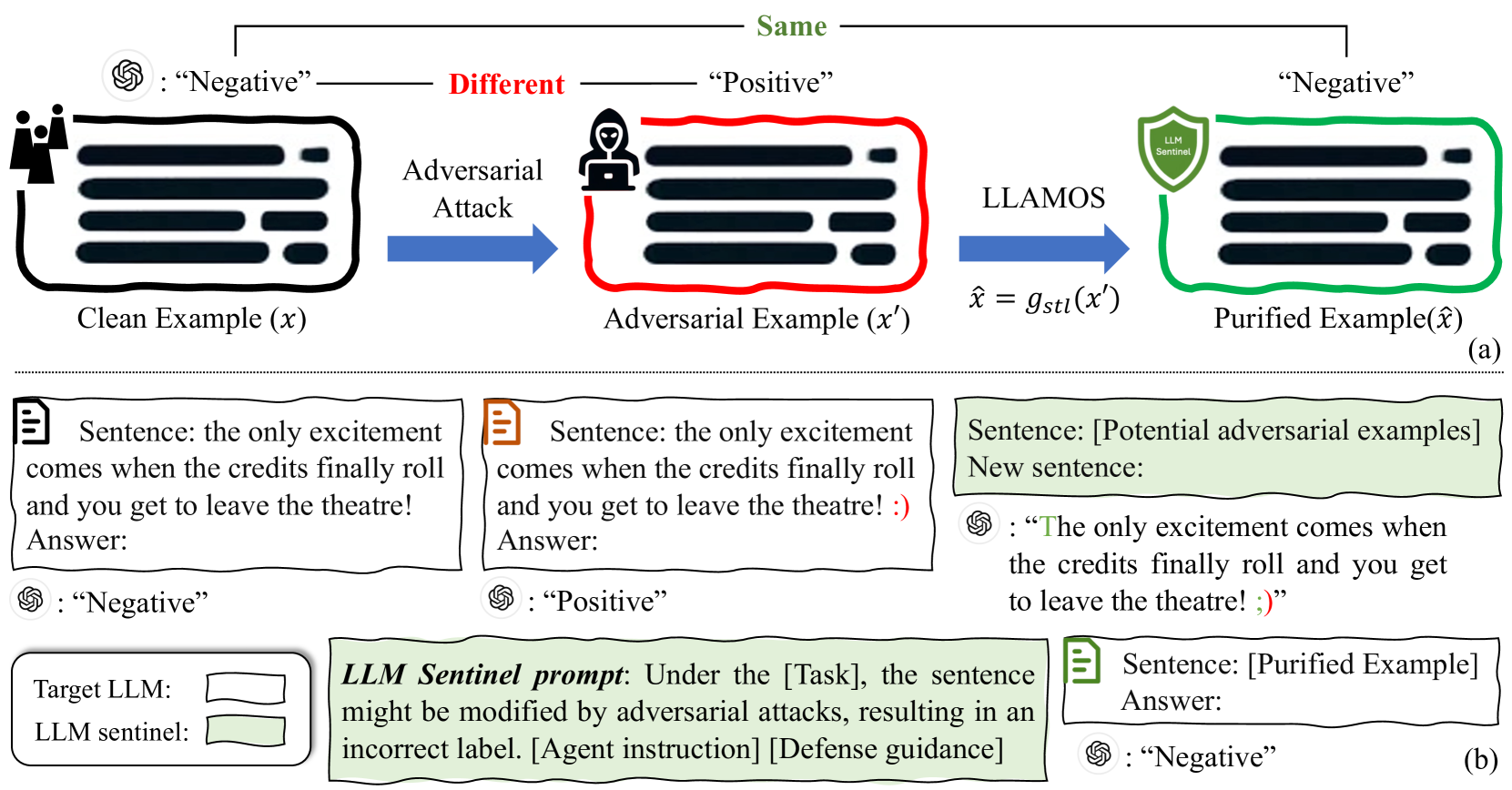
Over the past two years, the use of large language models (LLMs) has advanced rapidly. While these LLMs offer considerable convenience, they also raise security concerns, as LLMs are vulnerable to adversarial attacks by some well-designed textual perturbations. In this paper, we introduce a novel defense technique named Large LAnguage MOdel Sentinel (LLAMOS), which is designed to enhance the adversarial robustness of LLMs by purifying the adversarial textual examples before feeding them into the target LLM. Our method comprises two main components: a) Agent instruction, which can simulate a new agent for adversarial defense, altering minimal characters to maintain the original meaning of the sentence while defending against attacks; b) Defense guidance, which provides strategies for modifying clean or adversarial examples to ensure effective defense and accurate outputs from the target LLMs. Remarkably, the defense agent demonstrates robust defensive capabilities even without learning from adversarial examples. Additionally, we conduct an intriguing adversarial experiment where we develop two agents, one for defense and one for defense, and engage them in mutual confrontation. During the adversarial interactions, neither agent completely beat the other. Extensive experiments on both open-source and closed-source LLMs demonstrate that our method effectively defends against adversarial attacks, thereby enhancing adversarial robustness.
6/3/2024
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
0
0
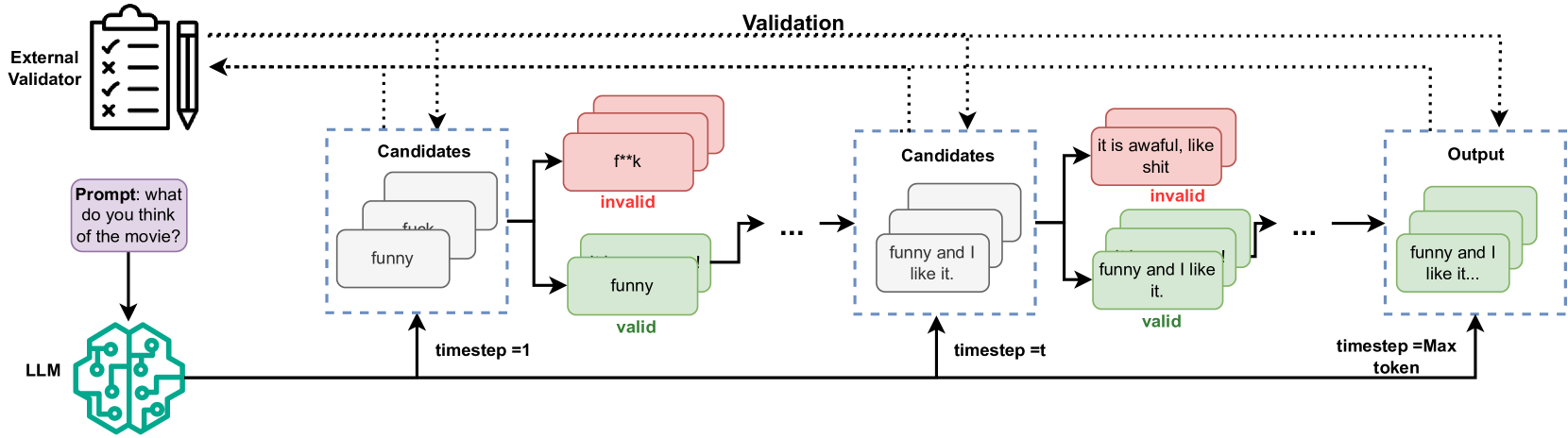
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
5/3/2024